本篇將會使用 Pytorch 官方所撰寫的 code 進行流程介紹

要先把資料整理成需要的格式,成對的(圖像, label),Dataloader 取資料的時候才不會拿錯。
torchvision datasets 已經幫你打包好了,不用特別自己寫。
以下為資料內容
from torchvision import datasets, transforms
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1305,), (0.3171,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True,
transform=transform)
test_dataset = datasets.MNIST('./data', train=False,
transform=transform)
# 印出 Test Dataset 有幾筆資料
print(test_dataset.data.size())
print(test_dataset.targets.size())
# 印出第一筆資料的資料內容
print(test_dataset.data[0])
print(test_dataset.targets[0])
torch.Size([10000, 28, 28]),10000筆圖片 1張圖片size為28*287。如果是用 Custom Dataset 看流程圖會比較好理解,因為 MNIST 都打包好了比較難懂流程。
Custom Dataset: 需要自己整理抓取資料標籤、圖片的位址。
以下3個function是一定要有:
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, test_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.test_transform:
label = self.test_transform(label)
return image, label
Train Transform 和 test transform 要分開寫,後續會講解。
訓練開始時,會 call Dataloader 去取資料,在程式碼中 train_loader會執行流程圖中黃色區塊,Dataloader再去找 Dataset 的 __getitem__ 取資料,Dataloader 會給一個 index,在 Dataset 的 list 中取 N 筆,因為batch size=64,所以 Dataloder 最後回傳的資料會是(batch_size, dim, W, H)=(64, 1, 28, 28)。
訓練時模型會 call forward 而x就是我們input的data。最後一層Linear輸出為類別的數量。若要在更詳細,可以去看其他人的教學。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
...
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
...
output = F.log_softmax(x, dim=1)
return output
讓我們詳細講解一下模型訓練的過程。
model.train():設置模型為訓練模式for batch_idx, (data, target) in enumerate(train_loader):加載 datadata.to(device):移動到GPU/CPUoptimizer.zero_grad():每次反向傳播之前,我們需要清空優化器中的梯度。這是因為 PyTorch 中的梯度是累加的(即每次反向傳播時,梯度會累加到已存在的梯度上)。output = model(data):前向傳播,獲得模型的輸出loss = F.nll_loss(output, target):計算損失loss.backward():計算損失相對於模型參數的梯度。optimizer.step():使用計算出的梯度來更新模型的參數。這是通過優化器(如 SGD 或 Adam)實現的。model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
with torch.no_grad()::禁用梯度計算,因為在評估模型時不需要進行反向傳播和參數更新,這樣可以節省內存和計算資源。F.nll_loss(output, target, reduction='sum').item():計算模型輸出與真實標籤之間的損失,並將每個批次的損失累加起來。這裡使用的是負對數似然損失(Negative Log-Likelihood Loss),並將 reduction 設置為 'sum',以便累加每個批次的損失。 .item()取出torch裡面的數值。output.argmax(dim=1, keepdim=True):獲取模型輸出中機率最大的類別索引。要自己把args改掉,不能使用args,使用到args的地方自行修掉。
# Training settings
batch_size = 64
test_batch_size = 1000
epochs = 14
lr = 1.0
gamma = 0.7
no_cuda = False
no_mps = False
dry_run = False
seed = 1
log_interval = 10
save_model = False
use_cuda = not no_cuda and torch.cuda.is_available()
use_mps = not no_mps and torch.backends.mps.is_available()
torch.manual_seed(seed)
上次使用的是Tensorflow的Keras進行簡單的手寫辨識模型訓練。
現在來實際做一下簡單的 loss function 改寫,原本只有使用到SparseCategoricalCrossentropy,但實際上我們訓練的時候不會只有使用到一個loss。
基本上 pytorch 和 keras 沒有太大的差異,在改寫 loss function 的方法都是一樣的。
請在上次的程式碼中的 loss 改成 L1 Loss、 SparseCategoricalCrossentropy 和 CategoricalCrossentropy相加。
L1 Loss、SparseCategoricalCrossentropy 和 CategoricalCrossentropy 相加
CategoricalCrossentropy他需要兩者維度相同,所以要先把 y_true 轉 one hot ,因為 y_true維度 (32,) 而 y_pred 的維度是(32,10)。# 定義自訂的損失函數
from tensorflow.keras.utils import to_categorical # Import to_categorical
def custom_loss(y_true, y_pred):
# SparseCategoricalCrossentropy 損失
scce = SparseCategoricalCrossentropy()(y_true, y_pred)
# TODO: CategoricalCrossentropy 損失: 轉onehot使用 to_categorical、CategoricalCrossentropy()
# TODO: L1 損失: tf.reduce_mean(tf.abs(y_pred - y_true_onehot))
# TODO: 結合3個損失
return combined_loss
import tensorflow as tf
# 匯入 Keras 內建的損失函數
from tensorflow.keras.losses import SparseCategoricalCrossentropy, CategoricalCrossentropy
# Import to_categorical
from tensorflow.keras.utils import to_categorical
# 建立一個簡單的神經網絡模型
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # 將 28x28 的圖像展平成 784 的一維向量
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# TODO: 編譯模型,使用自訂的損失函數
model.compile(optimizer='adam',
loss='TODO',
metrics=['accuracy'])
# 加載數據
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 訓練模型
model.fit(x_train, y_train, epochs=5)
# 評估模型
model.evaluate(x_test, y_test)
如果不會的話,可以直接看最底下答案。
import tensorflow as tf
# 匯入 Keras 內建的損失函數
from tensorflow.keras.losses import SparseCategoricalCrossentropy, CategoricalCrossentropy
# Import to_categorical
from tensorflow.keras.utils import to_categorical
# 定義自訂的損失函數
def custom_loss(y_true, y_pred):
# sparse_categorical_crossentropy 損失
scce = SparseCategoricalCrossentropy()(y_true, y_pred)
# 將 y_true 轉換成 one-hot 編碼,因為 y_true維度 (32,) 而 y_pred 的維度是(32,10)
y_true_onehot = to_categorical(y_true, num_classes=10)
# cross_entropy 損失
cross_entropy = CategoricalCrossentropy()(y_true_onehot, y_pred) # Use one-hot encoded labels
# L1 loss
l1_loss = tf.reduce_mean(tf.abs(y_pred - y_true_onehot)) # 取平均值
# 結合3個損失
combined_loss = scce + cross_entropy + l1_loss
return combined_loss
# 建立一個簡單的神經網絡模型
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # 將 28x28 的圖像展平成 784 的一維向量
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
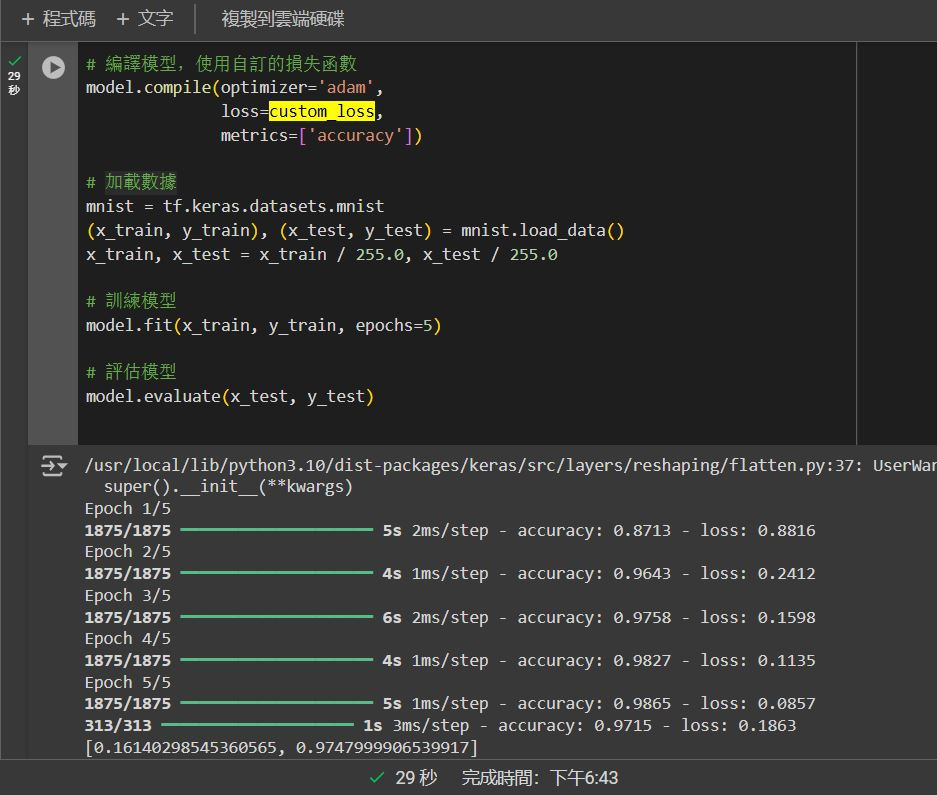
# 編譯模型,使用自訂的損失函數
model.compile(optimizer='adam',
loss=custom_loss,
metrics=['accuracy'])
# 加載數據
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 訓練模型
model.fit(x_train, y_train, epochs=5)
# 評估模型
model.evaluate(x_test, y_test)