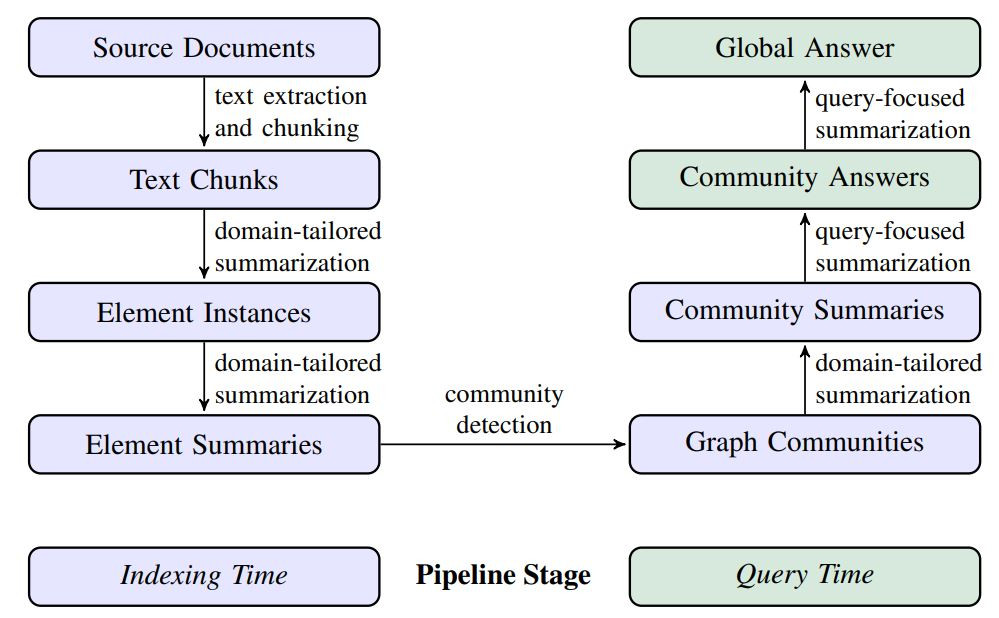
GraphRAG 是一種新穎的方法,用於回答針對整個文本集合的全局性問題。它結合了知識圖譜、檢索增強生成(RAG)和查詢聚焦摘要技術,實現了對大規模文本集合的全面理解和回答。
傳統RAG 方法主要用於回答局部問題,通過檢索相關文本片段並生成答案。然而,當問題涉及整個文本集合時,傳統RAG方法往往無法提供全面的回答。
Graph RAG 則不同,它首先從來源文件中提取實體和關係,構建知識圖譜,然後使用社群檢測算法將知識圖譜分割成模塊。每個模塊生成一個摘要,這些摘要可以並行處理,最終匯總成全局答案。
假設我們有一個包含大量新聞文章的資料集,並且我們想知道烏克蘭戰爭對股市的影響,但新聞沒有提到。傳統 RAG 方法可能會檢索到一些提到烏克蘭戰爭的文章,但無法全面回答這個問題。
GraphRAG 則會先構建一個包含所有實體和關係的知識圖譜,然後將這些實體和關係分成不同的社群模塊。每個模塊生成一個摘要,這些摘要可以並行處理,最終匯總成全局答案。這樣我們就可以得到一個全面的回答,說明烏克蘭戰爭如何影響股市。
這種方法不僅提高了回答的全面性和多樣性,還節省了大量的上下文信息量,提升了查詢效率。
text extraction and chunking
內文中提到另一篇論文 Kuratov et al., 2024; Liu et al., 2023
HotPotQA, Yang et al., 2018
當使用 600 個 tokens 的 Chunks 大小時,提取的 entity 數量幾乎是使用 2400 個 tokens 的 Chunks 大小時的兩倍。這表明較小的 Chunks 可以得到更詳細的資訊。
- Tokens: 在自然語言處理中,tokens 是指文本中的基本單位,通常是單詞或標點符號。例如,句子 "I love AI." 包含三個 tokens:"I"、"love" 和 "AI"。
- Entity: Entity 是指文本中具有特定意義的實體,例如人名、地名、組織名等。例如,在句子 "Microsoft is a tech company." 中,"Microsoft" 是一個 entity,表示一家公司。
- Chunk: Chunk 是指將文本分割成較小的部分,便於處理和分析。例如,一篇長文章可以被分割成多個段落,每個段落就是一個 chunk。
instances(實例): 指的是從文本中識別和提取出的具體實體和它們之間的關係。這些實體和關係被視為圖形節點和邊的實例。(實體實例/關係實例)
實際例子
假設我們有一篇關於科技公司的文章:
Microsoft was founded by Bill Gates and Paul Allen. It is headquartered in Redmond, Washington. The company is known for its software products like Windows and Office.
- Tokens: 這段文字包含 31 個 tokens。 標點符號也算。
- Entities: "Microsoft"、"Bill Gates"、"Paul Allen"、"Redmond"、"Washington"、"Windows"、"Office" 都是 entities。
- Chunks: 這段文字可以被分成兩個 chunks:
1. "Microsoft was founded by Bill Gates and Paul Allen. It is headquartered in Redmond, Washington."
2. "The company is known for its software products like Windows and Office."
定義完Chunks大小之後,要從每個 chunks 裡面提取出 Element Instances,這一步驟的基本要求是提取 graph nodes 和 edges,建立每個 nodes 關聯。但因為不是每次檢測都能順利提取出所有的關聯性,所以他們採用多輪“收集”,提取多次抓出所有可能遺漏的任何其他實體。
因為上一輪已經建立好實體和關係,這已經是一種抽象摘要形式。但會出現一個問題,因為多輪提取的關係會有實體重複。
實體一致性問題:LLM可能無法一致地提取相同實體的引用,導致實體元素重複。
接下來會使用 communities 的特性會檢測和統整出所有相同實體,LLM的能力可以理解多個名稱變化和重點摘要的需求相一致。
利用前面的實體和關係建立一個加權無向圖。這個圖為層次結構 (實驗使用了4層 (C0, C1, C2, C3)),而每個層級都提供了一個社區分區,該分區以互斥的、群集詳盡的方式覆蓋圖的節點,同時也為全局摘要。
摘要作為理解資料集的整體結構和語義的一種方式,用戶可以直接點擊某一level的社區摘要,尋找感興趣的主題,他會出現一些連接線,為每個相關的子主題並提供了更多資訊。
這是為了確保在生成摘要時,能夠最大限度地利用上下文窗口的容量,從而提供更全面和詳細的回答。這樣可以避免重要信息因為上下文窗口的限制而被忽略,確保生成的摘要能夠涵蓋所有相關的細節和觀點。
同樣的資料大小與設備情況下,RAG 只需要30秒就能回答出答案,但 GraphRAG 可能需要到1分半鐘才能回答答案。
LLMs之GraphRAG:《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》翻译与解读

