進階式?? 那當然就是 Naive 版的結果不夠好,
所以才會有Advanced的版本囉!
接下來將介紹幾種改良版的 也就是被統稱為Advanced RAG的版本囉!
在不改變太多架構下,可以先針對以下進行調整
Chunk 切法: 可否再優化? 長度是否足夠捕捉到足夠的上下文訊息?
目前切法: (可以研究一下如何調整參數)
Embedding-model 是否要更換其他的看看
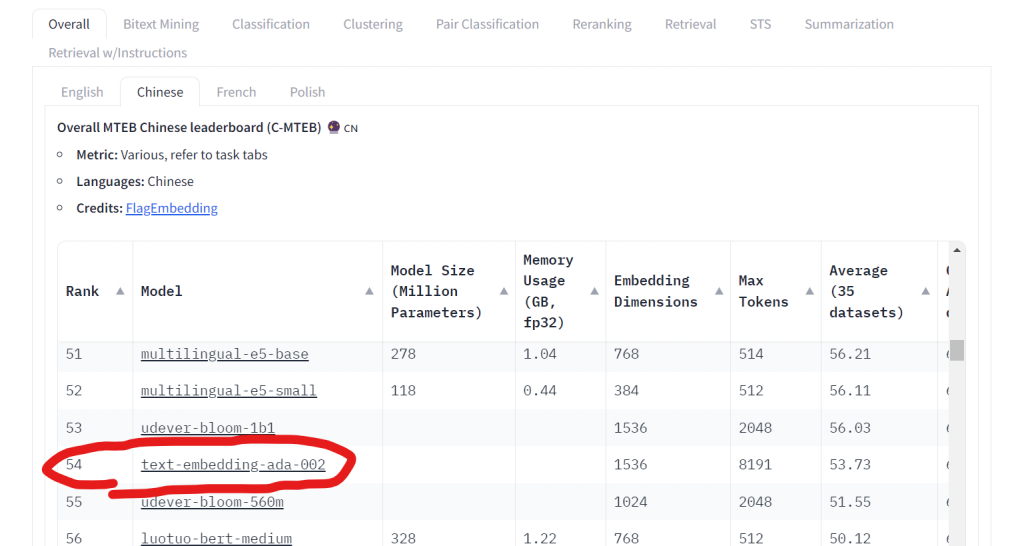
針對中文,我們目前採用的ada-002,只排第54名,大家可以斟酌考慮使用的embedding model為何
→ AOAI 上面的不多,用三個再去各別測試即可
text-embedding-3-large
text-embedding-3-small
text-embedding-ada-002
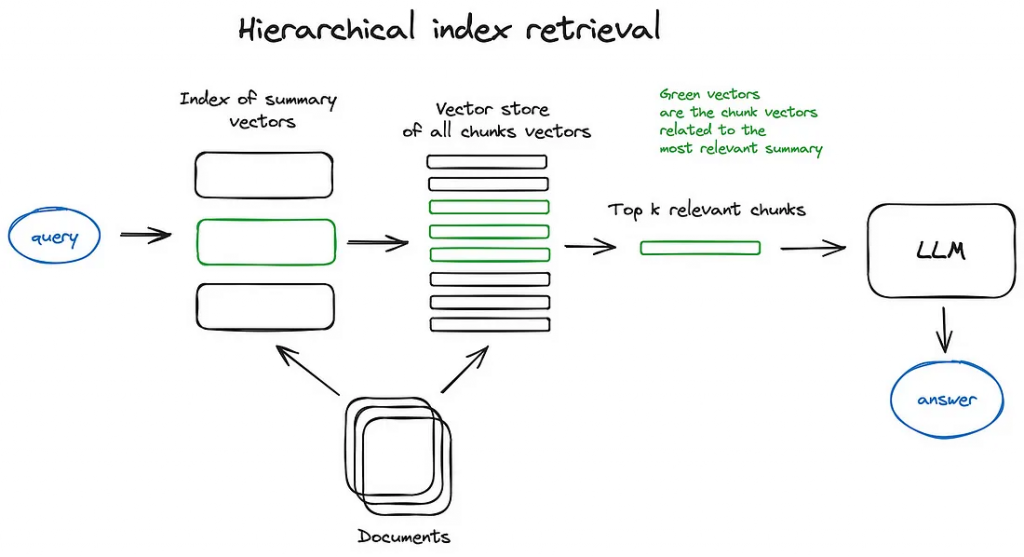
在擁有大量的documents集合時適用,可以顯著提高搜尋效率與結果,讓日後的search可更加針對相關文件進行搜尋
初次先對所有不同的documents 做summary並儲存此向量在Vector DB (用Atlas可儲存內容與向量)
→ 這裡的summary是直接下prompt給LLM去製作【精簡敘述的summary】嗎?
日後要進行搜尋時,就會先從summarize的結果進行過濾,找出最相關的那幾個摘要後
再開始去讀他們原始完整的檔案內容並將他們的chunks向量化,去找出最相關的Top k個chunks
再連同user query一同餵給LLM 生成最終答案
執行方法:
要先將所有chunks 取出content,然後傳給LLM 去做摘要生成。
→ 如果chunk詞語不完整就忽略不計,透過system prompt指定LLM不要去將不完整的句子敘述納入summary中。
→ 或者就讓LLM 強制生成summary
將獲得的摘要透過text-embedding-ada-2 來轉換成向量來表示( summary_vector) ,並且將summary_vector建立成search index。並且存回到原本的document單位中
未來直接透過summary_vector來去進行cosine similarity search
# 要將文字轉成向量
def embed_text(text):
response = openai_client.embeddings.create(
model="text-embedding-ada-002",
input=[text] # 必須是列表形式
)
return response.data[0].embedding
# 根據查詢,找出最相關的chunk 並回傳
def find_similar_documents(query, top_n=5, similarity_threshold=0.8):
query_embedding = embed_text(query) # 轉成向量
query_embedding = np.array(query_embedding).reshape(1, -1) # 將生成的embedding轉換為NumPy,並重塑為(1, -1)的形狀,以便後續進行相似度計算
# 從MongoDB集合 collection 中查詢所有文檔,只提取特定的key: 設為1就代表要取這個部分的值 (沒有指定到的key預設為 0)
documents = collection.find({}, {'summary': 1, 'summary_embedding': 1, '_id': 1, 'docName': 1, 'content': 1})
similarities = []
for doc in documents: # 從MongoDB中提取的所有文檔
if 'summary_embedding' in doc: # 若有包含此key
doc_embedding = np.array(doc['summary_embedding']).reshape(1, -1) # 轉換形狀 (因cosine_similarity接受兩個輸入參數,形狀應為2D)
similarity = cosine_similarity(query_embedding, doc_embedding)[0][0] # 計算餘弦相似度
similarities.append((similarity, doc)) # 將計算出的相似度和對應的文檔作為tuple 加進去
if similarity >= similarity_threshold: # 只保留相似度高于阈值的文档
similarities.append((similarity, doc))
# 根據相似度排序並返回前top_n個結果
similarities.sort(reverse=True, key=lambda x: x[0]) # 按相似度降序對 similarities 列表進行排序(變成由大到小排列)
top_documents = similarities[:top_n] # 提取排序後的前面 top_n 個文檔,這些文檔與查詢文本最為相關 ,它包含 (similarity, doc) 的列表
return top_documents
# 結合
def advanced_chain(query: str):
top_k = find_similar_documents(query)
related_chunks = "\n\n".join([doc['content'] for _, doc in top_k])
messages = [
SystemMessage(content="你是一個非常了解銀行法規相關資訊的人"),
HumanMessage(content=f"請根據以下資訊回答我的問題:\n\n{related_chunks}\n\n 問題:{query}")
]
response = llm(messages=messages)
return response.content.strip()
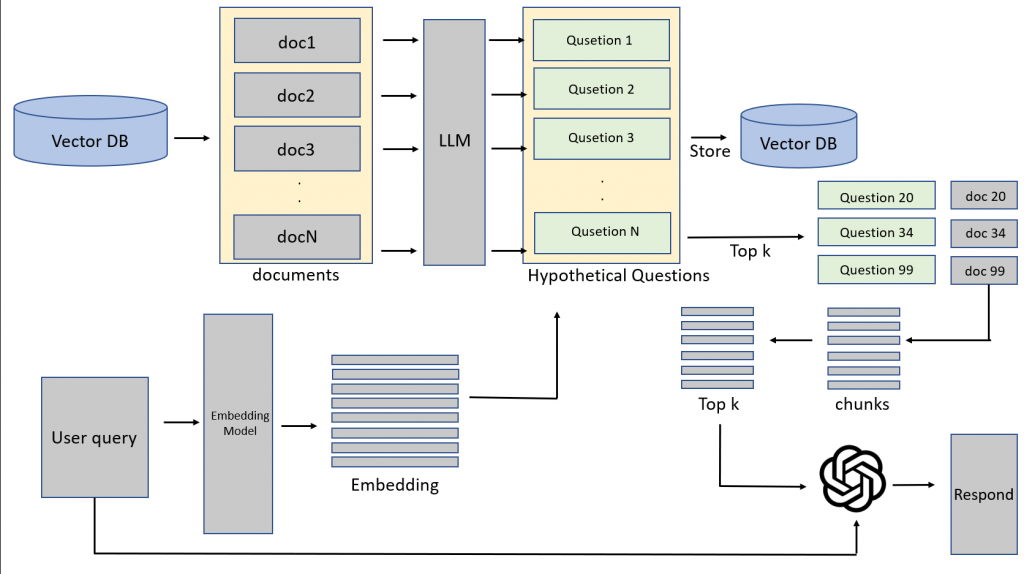
將各個documents利用LLM去產生出對應的questions,再儲存至Vector DB中。當user query 要進行查詢時,會先與hypothetical questions進行比對,去找出相關的documents後,再mapping到原始文檔再去切成chunk進行相似度比對,抓出Top k個chunks後,再連同user query一同餵給LLM 做生成
from langchain_core.messages import HumanMessage, SystemMessage
# 要將文字轉成向量
def embed_text(text):
response = openai_client.embeddings.create(
model="text-embedding-ada-002",
input=[text] # 必須是列表形式
)
return response.data[0].embedding
# 根據查詢,找出最相關的chunk 並回傳 (自己算相似度)
def find_similar_documents(query, top_n=5):
query_embedding = embed_text(query) # 轉成向量
query_embedding = np.array(query_embedding).reshape(1, -1) # 將生成的embedding轉換為NumPy,並重塑為(1, -1)的形狀,以便後續進行相似度計算
# 從MongoDB集合 collection 中查詢所有文檔,只提取特定的key: 設為1就代表要取這個部分的值 (沒有指定到的key預設為 0)
documents = collection.find({}, {'question': 1, 'question_embedding': 1, '_id': 1, 'docName': 1, 'content': 1})
similarities = []
for doc in documents: # 從MongoDB中提取的所有文檔
if 'question_embedding' in doc: # 若有包含此key
doc_embedding = np.array(doc['question_embedding']).reshape(1, -1) # 轉換形狀 (因cosine_similarity接受兩個輸入參數,形狀應為2D)
similarity = cosine_similarity(query_embedding, doc_embedding)[0][0] # 計算餘弦相似度
similarities.append((similarity, doc)) # 將計算出的相似度和對應的文檔作為tuple 加進去
# 根據相似度排序並返回前top_n個結果
similarities.sort(reverse=True, key=lambda x: x[0]) # 按相似度降序對 similarities 列表進行排序(變成由大到小排列)
top_documents = similarities[:top_n] # 提取排序後的前面 top_n 個文檔,這些文檔與查詢文本最為相關 ,它包含 (similarity, doc) 的列表
return top_documents
def hypothetical(query:str):
top_documents = find_similar_documents(query)
related_chunks = "\n\n".join([doc['content'] for _,doc in top_documents])
messages = [
SystemMessage(content="你是一個非常了解銀行法規相關資訊的人"),
HumanMessage(content=f"請根據以下資訊回答我的問題:\n\n{related_chunks}\n\n 問題:{query}")
]
response = llm(messages=messages)
return response.content.strip()
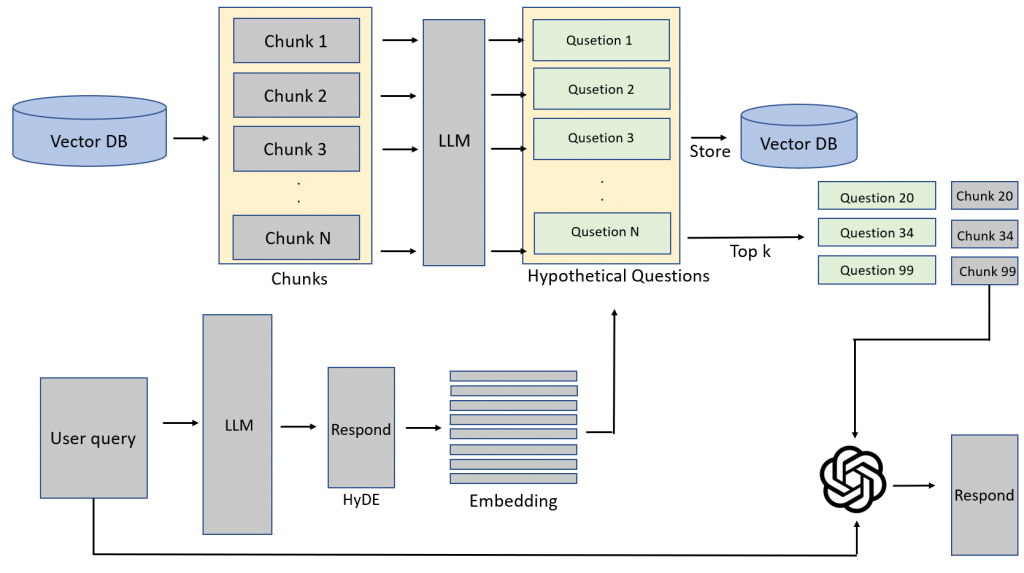
執行方法:
將User query先透過LLM生成出一組回答,將此回答再用embedding 轉成向量,再去Hypothetical Questions中進行相似度計算,去找出top k個相關questions後,再mapping到背後的chunks,再連同user query一同餵給LLM去回答
from langchain_core.messages import HumanMessage, SystemMessage
# 使用者查詢
user_query = "保證書遺失可否補發?"
def hypothetical_chain(query: str):
messages = [
SystemMessage(content="你非常了解銀行法規、內部資訊等相關事宜,請根據使用者問題,回答一個精簡但又與事實相近的答案"),
HumanMessage(content=query)
]
response = llm(messages=messages)
hyde = response.content.strip() # 去除前後空格
top_k = retrieve(hyde) # 找5個
related_chunks = "\n\n".join([doc.page_content for doc in top_k])
messages = [
SystemMessage(content="你是一個非常了解銀行法規相關資訊的人"),
HumanMessage(content=f"請根據以下資訊回答我的問題:\n\n{related_chunks}\n\n 問題:{query}")
]
response = llm(messages=messages)
return response.content.strip()
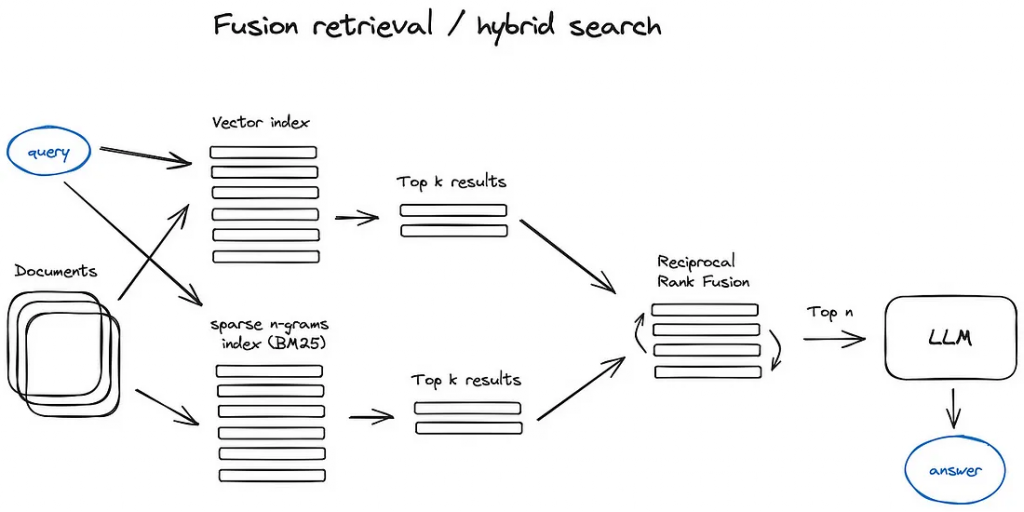
結合傳統基於關鍵字的搜索方法(如TF-IDF或BM25)與現代基於向量的搜索技術的混合方法。這種混合方法通過整合多種相似性計算,來優化檢索結果
from langchain_core.retrievers import BaseRetriever
from langchain.schema import Document
from pydantic import BaseModel, Field
from typing import List, Dict, Any
from rank_bm25 import BM25Okapi # 使用BM25算法
import numpy as np
import uuid # 生成唯一的標識符
class CombinedRetriever:
def __init__(self, vector_store, collection, bm25_k=5, vector_k=5, top_n=5):
self.vector_store = vector_store
self.collection = collection
self.bm25_k = bm25_k # 檢索返回的前 k 個文檔數量
self.vector_k = vector_k # 向量檢索返回的前 k 個文檔數量
self.top_n = top_n
def bm25_search(self, query):
documents = [doc['content'] for doc in self.collection.find()]
tokenized_documents = [doc.split() for doc in documents]
bm25 = BM25Okapi(tokenized_documents)
tokenized_query = query.split()
scores = bm25.get_scores(tokenized_query)
top_k_indices = np.argsort(scores)[::-1][:self.bm25_k]
top_k_docs = [documents[i] for i in top_k_indices]
return [Document(page_content=doc) for doc in top_k_docs]
def similarity_search(self, query):
vector_results = self.vector_store.as_retriever(search_type="similarity", search_kwargs={"k": self.vector_k}).get_relevant_documents(query)
return vector_results
def rrf(self, results_list, k=60): # 將多個檢索進行融合的算法
rrf_scores = {}
for results in results_list:
for rank, doc_id in enumerate(results):
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank + 1.0)
sorted_results = sorted(rrf_scores.items(), key=lambda item: item[1], reverse=True)
print(sorted_results)
return [doc_id for doc_id, score in sorted_results[:self.top_n]]
def get_relevant_documents(self, query):
vector_results = self.similarity_search(query)
vector_results_ids = [str(uuid.uuid4()) for _ in vector_results] # 為每個檔案生成唯一ID
bm25_results = self.bm25_search(query)
bm25_results_ids = [str(uuid.uuid4()) for _ in bm25_results] # 為每個檔案生成唯一ID
# 使用 RRF 融合结果
combined_results_ids = self.rrf([vector_results_ids, bm25_results_ids])
# 從兩種方法中篩出最終結果
final_results = [doc for doc, doc_id in zip(vector_results + bm25_results, vector_results_ids + bm25_results_ids) if doc_id in combined_results_ids]
return final_results
class LangChainRetriever(BaseRetriever): # 繼承自 BaseRetriever: BaseRetriever 定義了一些基礎的檢索功能,使得 LangChainRetriever 可以充當LangChain檢索框架中的一部分
combined_retriever: CombinedRetriever = Field() # 是 CombinedRetriever 類的實例,用來調用 get_relevant_documents 方法
class Config:
arbitrary_types_allowed = True
def _get_relevant_documents(self, query: str) -> List[Document]: # 實現抽象方法
results = self.combined_retriever.get_relevant_documents(query) # 調用 CombinedRetriever 來獲取最終的文檔列表
return results
# 創建自定義的Langchain retrieve 實例
langchain_retriever = LangChainRetriever(combined_retriever=CombinedRetriever(vector_store, collection))
# 使用from_chain_type 建構QA chain
def fusion_chain_bm25(query: str):
qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=langchain_retriever, return_source_documents=True)
result = qa_chain.invoke({"query":query})
return result['result'].strip()
將檢索到的Top k 個chunk進行排序,有論文指出LLM較容易忽略掉中間的訊息,
所以透過repack方法,先將最重要的chunk上下上下這樣去做插入
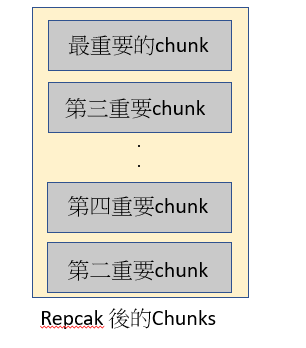
將repack後也就是重新排序過的chunk們,再餵給LLM去生成答案前,
先再請LLM優化一下這些repack過的chunk 與 user query結合過的prompt,
此作法可以讓prompt變得更好以利於後續的LLM要來生成更好的回答
參考資料&部分圖片來源: https://medium.com/@krtarunsingh/advanced-rag-techniques-unlocking-the-next-level-040c205b95bc
以上就是Advanced RAG的介紹,剩下最後5天囉!
有了Advanced RAG的方法,但Advanced RAG的方法又這麼多種,
到底該導入哪個呢? 接下來就是一起來探討 如何去評估RAG囉
您好,有關Day25 GAI爆炸時代 - Advanced RAG 介紹
裡面有提到
documents = collection.find({}, {'summary': 1, 'summary_embedding': 1, '_id': 1, 'docName': 1, 'content': 1})
想請問這一段產生summary到mongoDB的部分,有langchain程式碼可以參考嗎?


 iThome鐵人賽
iThome鐵人賽