在 part 1 裡,有舉出一個 Datalog 查詢的例子:
[:find ?title
:where
[_ :movie/title ?title]]
其中 :find 這個詞,英文的語意跟 SQL 的 SELECT 也差不多,而且它們的右方都是要寫查詢的目標、對查詢的輸出的修飾。
真正不一樣的地方是在 :where 。在 SQL 裡也有 WHERE ,且在 WHERE 的右邊是寫要用來篩選資料列的條件。 前述的 where 語意, Datalog 也差不多。但是,這邊有兩個不同點:
FROM 來指定是哪一張表。:where 條件的寫法,看起來與 SQL 條件的寫法頗不一樣。要解釋這些不同點,我們就必須先來了解 Datomic 的資訊模型 (information model) 了。
當我們在想象 SQL 資料庫的資訊模型時,我們通常是想成如下圖:
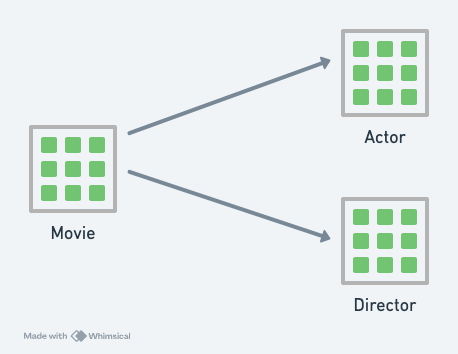
而 Datomic 資料庫的資訊模型則非常地不同,我們要想成是,彷彿整個資料庫只有一張表,而這張表有五個欄位。
[<entity-id> <attribute> <value> <tx-id> <op>]
...
[ 167 :person/name "James Cameron" 102 true]
[ 234 :movie/title "Die Hard" 102 true]
[ 234 :movie/year 1987 102 true]
[ 235 :movie/title "Terminator" 102 true]
[ 235 :movie/director 167 102 true]
...
在上述這張表中,每一列都可稱之為資料原子 (datom)。
而五個欄位分別是:
該怎麼理解上述這種特殊的資訊模型呢?我們可以這樣子想象:
如果我們要把 SQL 資料庫裡的若干張資料表裡的資料,全數塞入一張 Datomic 資料表,那我們可以怎麼做呢?具體的步驟如下:
entity-id, attribute 和 value,又可簡稱為 EAV model。其中,entity-id 的資料型態是長整數、attribute 的資料型態為字串、value 的資料型態為二進位 (BLOB)。movie 表有一個 title 欄位,這個欄位之後要叫 :movie/title
movie table
[entity-id :moive/title :movie/year :movie/director]
...
[214748 "Terminator" 1987 "James Francis Cameron"]
=>
Datomic table
[<entity-id> <attribute> <value>]
...
[214748 :moive/title "Terminator"]
[214748 :moive/year 1987]
[214748 :moive/director "James Francis Cameron"]
如果讀者心裡覺得,呃,這個方式滿酷的,還是說我們使用 SQL 資料庫時,也可以考慮這樣子設計資料表綱要來儲存資料?
這個作法叫做 EAV model ,通常被視為是反模式 (anti-pattern)。然而,wordpress 裡儲存 user meta 資料表、post meta 資料表都是用 EAV model ,所以實務中還是有在使用。
Datomic 的資訊模型還比 EAV model 更複雜一些些,因為還多了交易編碼與操作兩個欄位。這兩個欄位相對容易解釋:
交易編碼
操作
true 或是 false 。true 表示,這個資料原子對應的事實存在;而 false 表示,這個資料原子對應的事實不存在。換言之,當我們要刪除資料時,我們就會寫入新的資料原子,而這些資料原子會對應到某些既有的資料原子,且它們的操作欄位為 false 。以下這個查詢是要找出,所有含有 :person/name 恰好為 "Ridley Scott" 的資料實體編碼。
[:find ?e
:where
[?e :person/name "Ridley Scott"]]
逐字逐句來解釋上述的查詢:
[?e :person/name "Ridley Scott"] 這個條件比對整個資料庫的內容,:where 子句裡的 ?e 是一個未知的變數。?e 。是不是跟 SQL 查詢也有一點像呢?先執行的部分是寫在下方的部分。

