在 ollama.com 找到模型後,在模型頁上顯示模型大小,以「starcoder2 3B」為例
https://ollama.com/library/starcoder2 ,頁面上顯示是 1.7GB,保守乘 2 倍約為 3.4G
那麼電腦的 vRAM 只要有 4G 就能完全載入模型在顯卡上執行。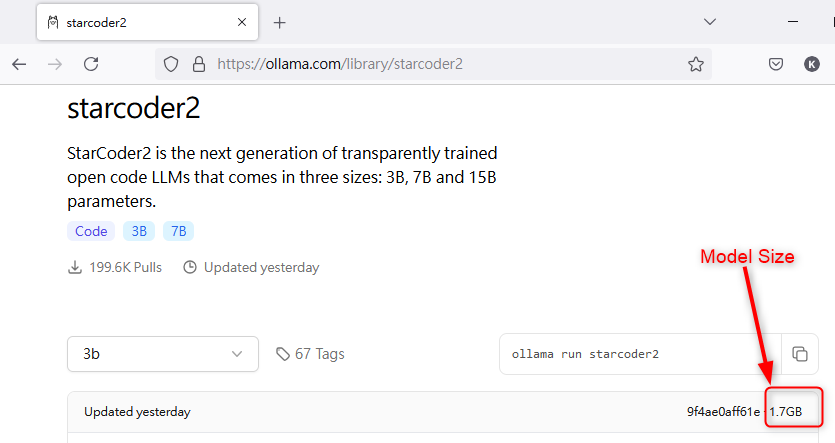
以上僅是大略推估方法。實際上「starcoder2 3B」載入全部模型需要 3G。
雖然 Ollama 可以用 CPU 執行,但根據
黑暗大文章「用入門級顯卡 RTX 3050 + Ollama 跑小模型,會比 CPU 快多少倍?」,
用 CPU 會掉速1/3,大模型當然就更不用說了...
注意:
截至今天(2024-09-08)單張消費者級顯卡的 vRAM 最高有 24GB,
所以消費者級顯卡最多能順跑【20B以下】的模型。
如果要跑更高參數的就要挑「量化」後的模型,例如:llama3.1:70b-instruct-q2_k 只有 26GB,
也許大部分可塞進 24GB vRAM,但「量化=效果打折」,效果有沒有比 llama3.1:8b 好就需要多測試了。
Ollama 對於電腦的 RAM 也有建議,參考:
https://github.com/ollama/ollama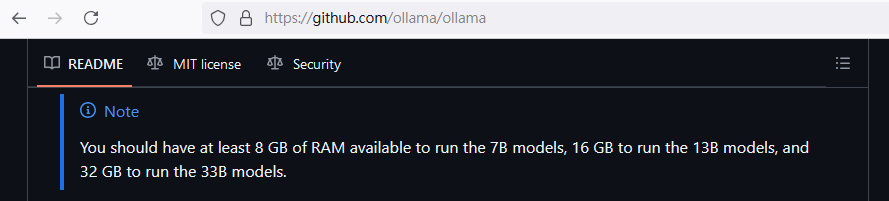
簡單劃分參數【20B以下】及【超過20B】;
以我用途是在 vscode 支援寫 C# 程式為例,
用 starcoder2(3B) 在自動完成(autocomplete)、加註解等「小動作」體感相當滿意,
我用大模型 Hermes-3 405B(截至今天 2024-09-08 免費使用,來自雲端 OpenRouter 的),
對於複雜的動作只要簡單的指令就能執行的很好,例如:新增 XXXServcie.cs 在指定資料夾,並建立 CRUD 方法。
(有時候會失敗,似乎是 token 太長...)
 kawa0710
kawa0710
