實際上執行服務的元件 (●°u°●)
Worker Node 是實際乘載服務的節點,除了 pod 外也包含執行用的組件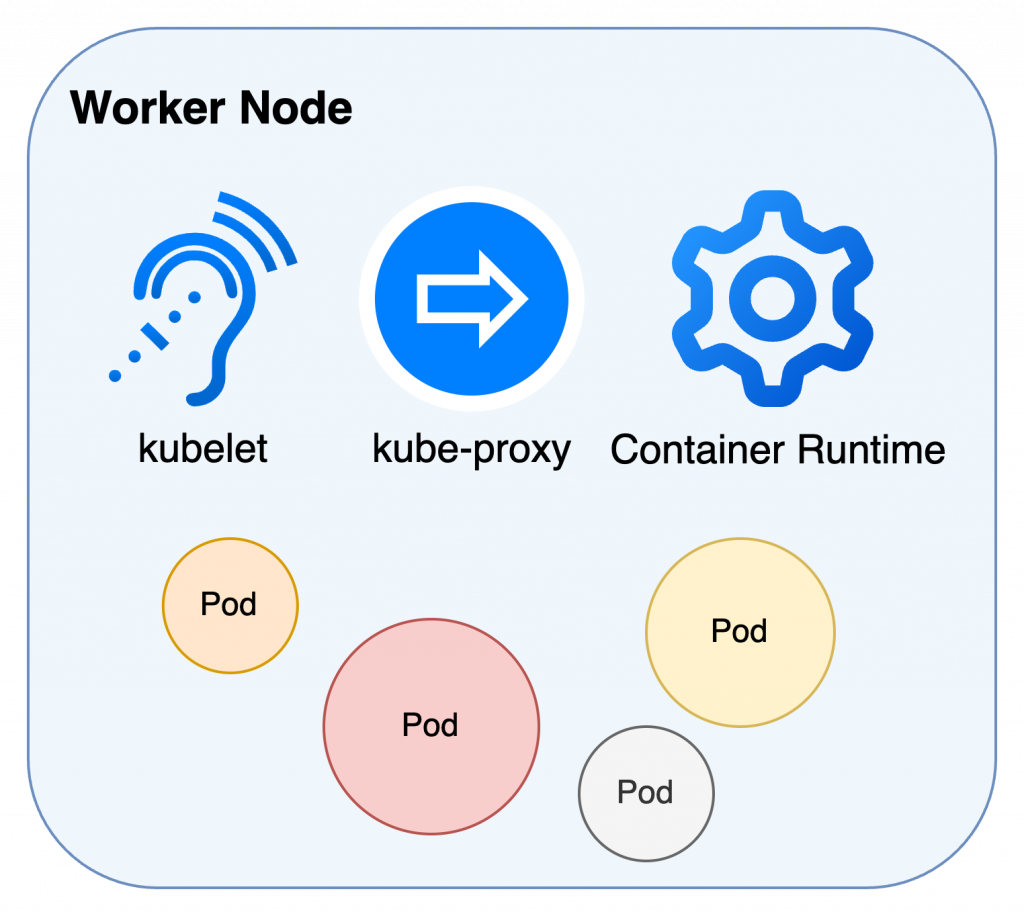
如果有看過地獄廚房,應該對廚房如何完成一個晚宴應該不陌生。
(地獄廚房很好看,推推。)
(沒看過的話就是地獄廚神 Gordon Ramsay 對一群職業廚師破口大罵的實境秀。)
AI繪圖蠻傳神的,差不多就是個樣子
晚宴是這樣:
由外場侍者帶回顧客訂單,主廚喊單並確認廚師們知道要出什麼餐並開始烹飪,將完成的菜品端上前台,經過主廚的最後確認再由侍者送上餐桌。
基本上就是想像一個忙到不行的餐廳。元件的工作分配如下:
爐灶和設備:container runtime,根據餐廳食譜的要求配置烹飪環境
主廚:kubelet,接收侍者傳過來的訂單並確保每個膳台都有好好做事
侍者:kube-proxy,負責引導客人和管理訂單流程
廚師:container&pod,在準備好設備的廚房中完成烹飪
詳細介紹各元件:
Worker Node 上最重要的組件。
處理來自透過 kube-apiserver 的指令,也會主動向 kube-apiserver 傳送訊息
管理 node 上的所有 pod 和其中的 container
(不認識 kube-apiserver 的話可以參考前一篇:Control Plane)
獨立運行
前面有提到,如果kube-apiserver毀損會使整個叢集都無法操作。
由於 kubelet 的管理範圍只在 Worker Node,因此在所屬的 node 中還是可以就現有資訊繼續工作。
(跟 Control Plane 溝通就沒辦法了,相當於無法從外部執行任何建立、修改、更新。)
自註冊 self-registers
如果將kubelet的--register-node 設定為 true,kubelet就會主動向apiserver自行註冊
,使自己擁有建立和修改 node 的權限。
預設情況下,這個範圍包含 Cluster 中的「所有」node,基於安全考量,會建議把權限限縮在 kubelet 所在的 node 上。
處理節點間的通訊和流量轉發。
會監聽 node 上的 service 和 pod,隨時依照變化更新節點的網絡設置。
有兩種模式:
依照 image 的需求配置執行環境並運行 container。
以 Docker Engine 最常見,導入 CRI (Container Runtime Interface) 後的 k8s 版本1(v1.5)支援任何符合 OCI 規範的服務。
只有 Worker Node 才能運行 Pod 嗎?
所有的服務都是以
pod形式存在的,當然 Control Plane 上的組件也是。
Control Plane 上的 pod 皆運作在kube-system這個namespace中。那為什麼常會看到 Control Plane 上不能運行 pod 的討論呢?
一般情況下在討論 pod 部署的時候,是指經由
kube-scheduler決策,使用者自行部署在 k8s 上的應用程式(Control Plane 上運行的 pod 有另一套機制)。
在 k8s 的設計概念中,Control Plane 作為決策中樞可說是最為重要的存在,會盡可能避開所有可能產生風險的操作,而不會把它當成 Worker Node 使用,而是將工作切分乾淨,中間只透過kube-apiserver溝通。實際上是怎麼做的呢?
後面會講
沒,開玩笑的。
node 的設定值中有個名為Taint的參數,Control Plane 將它預設為NoSchedule,意即標示這個 node 不參與kube-scheduler部署 pod 的評選流程。
對... 把設定移除後 pod 是可以被部署到 Control Plane 上的,
但這種增加風險的行為還是不要做吧 (´・ω・`)
Worker Node 是 Kubernetes Cluster 中實際運行容器的單位,負責執行和管理分配給它們的容器。
透過 kubelet 確保所有的 pod 按照規則運行;透過 kube-proxy 管理服務間的網路通訊。
綜合前一天的 Control Plane 介紹,可以大致上知道 Control Plane 和 Worker Node 之間的工作模式。以建立一個 pod 舉例: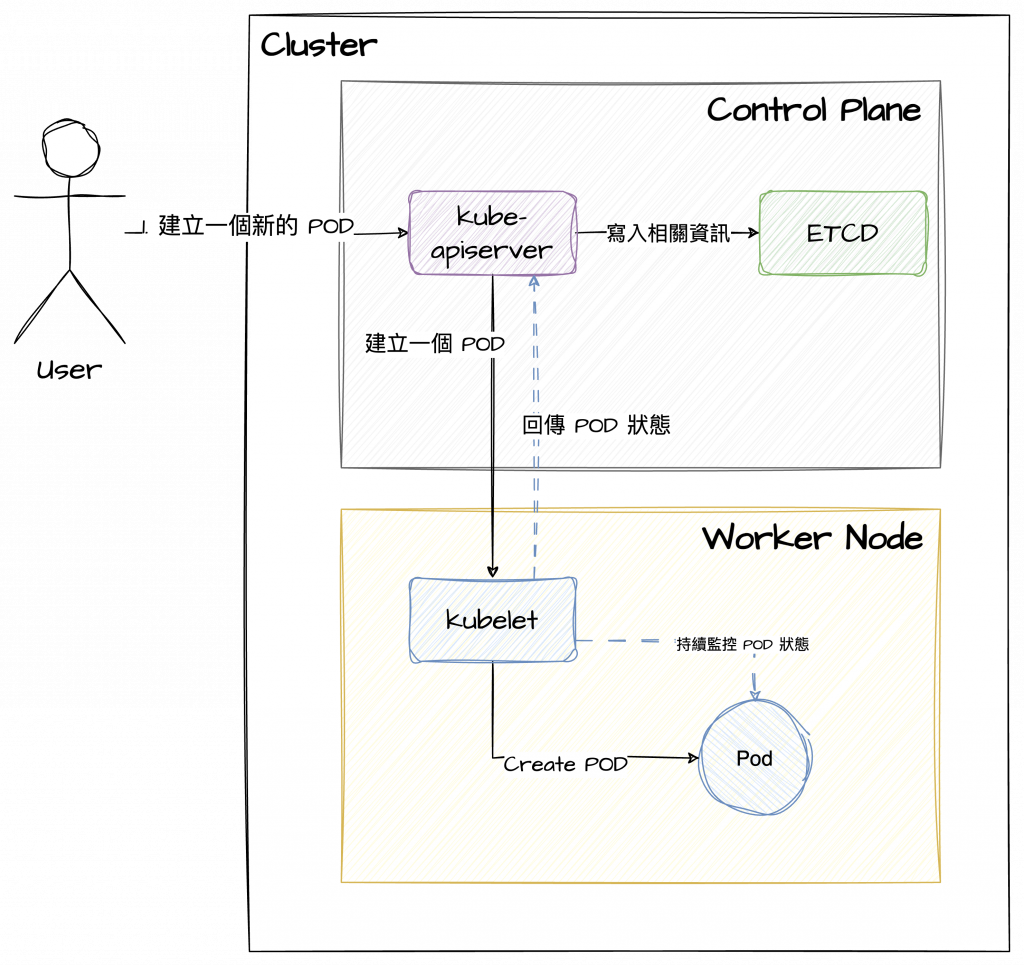
雖說上圖只專注於元件之間的協作,實際上Worker Node的運作複雜許多,但也不難看出兩者之間的分工是非常明確的。實務上,一個 Kubernetes Cluster 通常有多個 Worker Node,以確保系統擴展、容錯和工作負載的能力。

