原始迴圈:
for (i=0; i<N; i++)
B[i] = A[i] + C;
這個迴圈逐一處理數組元素,每次執行一次加法操作。
展開後的迴圈:
for (i=0; i<N; i+=4) {
B[i] = A[i] + C;
B[i+1] = A[i+1] + C;
B[i+2] = A[i+2] + C;
B[i+3] = A[i+3] + C;
}
將內部迴圈展開一次處理 4 次迭代,這樣做可以減少迴圈控制(如比較、跳轉指令)的頻率,從而提升整體運行效率。
以下展示了展開後的迴圈 code 是如何在硬體中被調整執行的。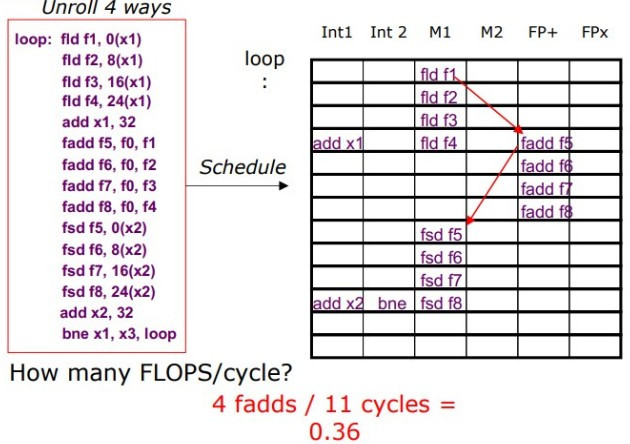
fld 指令(浮點載入)在 M1 和 M2 週期中執行。fadd 指令(浮點加法)在 FP+ 和 FPx 單元中執行。fsd 指令(浮點存儲)安排在後面的週期中執行。透過迴圈展開和有效的指令調整,可以顯著提升處理器的平行性和 throughput。且需要編譯器或開發者仔細安排指令,以避免數據危險和資源衝突。
兩種不同的可擴展多處理器系統架構:共享記憶體(NUMA)和訊息傳遞叢集(Cluster)。NUMA 提供了高效的記憶體訪問,但建設和維護成本較高;而訊息傳遞叢集利用更低成本的硬體實現了擴展性,適合更大規模和更分散的計算需求。每種架構都有其優勢和適用場景,取決於應用需求和成本考量。

