今天我們來聊聊 DB 的 index。
簡單來說,資料庫索引是一種可以加速資料查詢的資料結構,他是一種有序的結構。他就像書的目錄頁一樣,讓我們透過目錄可以快速找到我們要找的頁數,而不用翻遍整本書。在資料庫中,索引的作用就是指向資料表中特定資料的「指標」,幫助我們快速定位所需的 row 。
在講索引的原理之前,我們先了解一下資料庫是怎麼查詢資料的。
Full Table Scan:
無索引的缺點:
一般來說,我們自己設定的索引都會是一種非叢集索引(Non-clustered Indexes),因為叢集索引只針對一個欄位,這個我們待會會講到,現在先介紹非叢集索引是如何運作的。
舉個例子最快理解,今天我們把 record_date 設成 index,我們要找 2024-09-26
[2024-09-25]
/ \
[2024-09-22] [2024-09-28]
/ \ / \
[2024-09-20] [2024-09-23, 2024-09-24] [2024-09-26, 2024-09-27] [2024-09-29]
在 B-tree 索引中,每個子節點不僅僅儲存索引值(如 record_date),他還包含一個指向實際資料位置的 pointer。這些 pointer 指向資料表中實際儲存的 row。當查詢到索引時,就會透過 pointer 馬上找到對應的資料。
以下圖為例,Index 是有序的 friend 資料結構,並會指向 friends 的 table。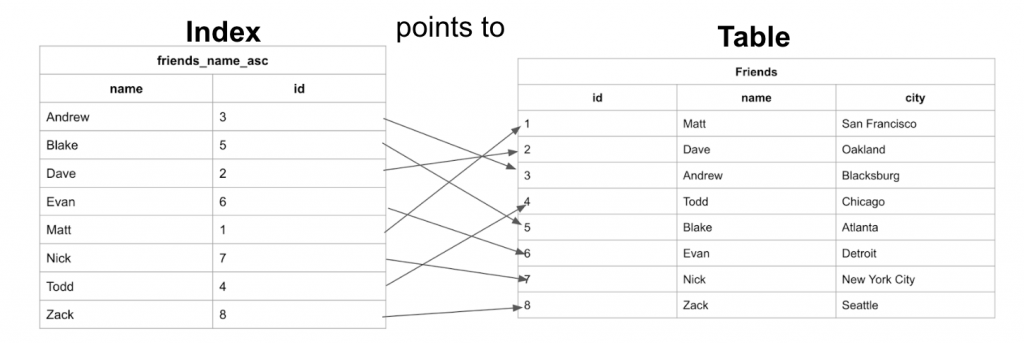
圖片來源
叢集索引(clustered Indexes)是每個表的唯一索引(unique index),設有叢集索引的 table 中,table 的資料實際上是按照索引鍵的順序來儲存的,因此該索引幾乎都會是 table 的主鍵。
可以看到下圖跟上面的非叢集索引比起來,它就會完全參照它的順序。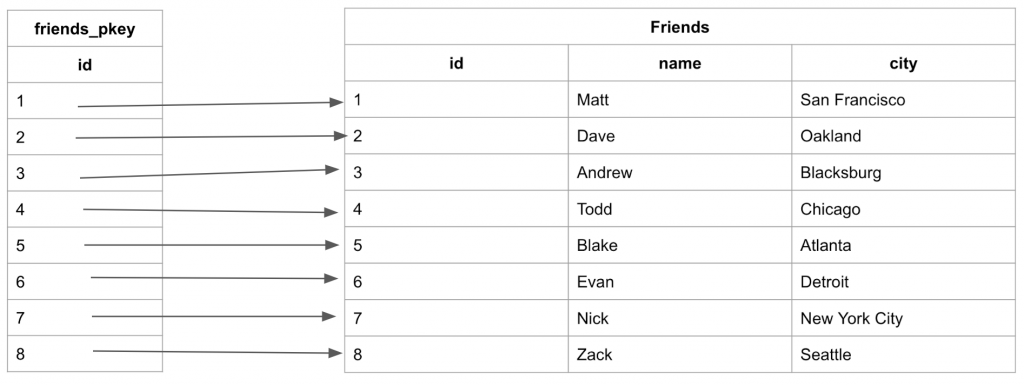
圖片來源
雖然索引大幅提升了查詢效能,但也有一些限制需要考量:

