原文連結:Working with Complex Internal Tables
之前提過使用APPEND來新增資料列到Internal Table之中。這種與表格資料相對應的物件,又可稱為work area。
之前介紹簡易Internal Table,其work area都是單值的型別。對於複雜的Internal Table,work area會是structure型別。
*work area 建立
*connections為Internal Table
DATA connections TYPE st_connections.
*connection為work area
DATA connection LIKE LINE OF connections.
APPEND connection TO connections.
以上例而言,有兩個標準方式宣告work areaconnection:
st_connection
LIKE LINE OF接指定的internal table,間接參照其structure由於work area多半是針對internal table建立的,採用方法二有兩個優點:
可以為internal table建立預設值,在用work area填值之前,internal table裡的最新一列都會先用預設值代替(否則為空)。
DATA connections TYPE tt_connections.
* 建立預設值
connection = VALUE #( carrier_id ='NN'
connection_id = '1234'
airport_from_id = 'ABC'
airport_to_id = 'XYZ'
carrier_name = 'My Airline' ).
也有不使用work area就賦值的方式,那就是直接用表達式APPEND VALUE #()來賦值。甚至還能節省建work area的記憶體。
DATA connections TYPE tt_connections.
* 用表達式直接賦值
APPEND VALUE #( carrier_id ='NN'
connection_id = '1234'
airport_from_id = 'ABC'
airport_to_id = 'XYZ'
carrier_name = 'My Airline' ).
TO connections.
另一個用表達式直接賦值的還有#VALUE可以賦值多筆資料,這種方式使用括號區別每一列資料。在下面的範例中,表格被存入了三列資料,每列都有不同的值。
DATA carriers TYPE tt_carriers.
carriers =VALUE #( (carrier_id = 'AA' carrier_name ='American Airlines')
(carrier_id = 'JL' carrier_name ='Japan Airlines')
(carrier_id = 'NN' carrier_name ='My Airline')
).
註:使用上面的這個方法賦值時,所有既存的資料列會在填入新資料列時被移除。
* connections為目標資料表,carriers為來源資料表
connections = CORRESPONDING #( carriers ).
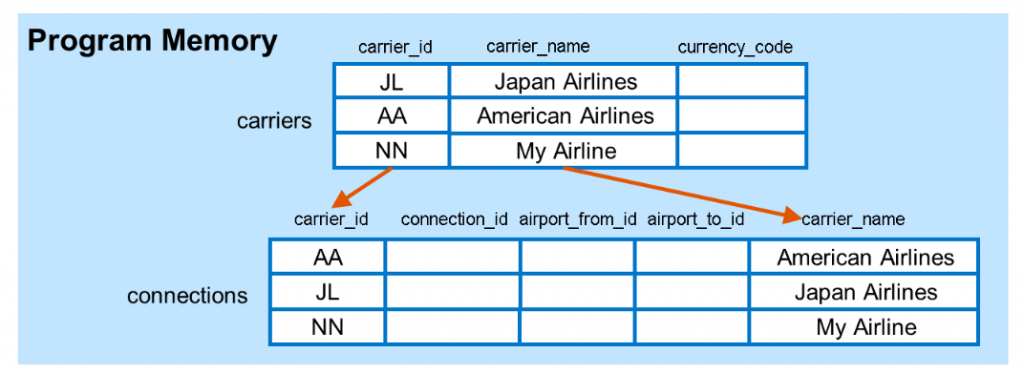
如上圖所示,使用CORRESPONDING可以對兩個表格自動進行對應,當我們把carriers表格複製進時,將會新增對應的行數即資料到目標表格,如果欄位為與來源資料表沒有吻合,將不會複製任何資料。而對於沒有吻合名稱的欄位,將會自動填入該欄位型別的初始值。
在範例中,來源資料表carriers中有三列資料,將依序複製到CORRESPONDING表格中,在範例中兩張表都有carrier_id與carrier_name欄位,其餘的空欄位就不會複製過去了。
註:如果目標表格在賦值前有包含資料,系統會將其原先的資料刪除。
之前的章節中,我們已經學習過如何透過表達式檢索Internal Table。用索引檢索的的流程大致與先前無異,接下來主要會側重於如何在Internal Table中用鍵(key)來檢索。
雖然都說是用鍵值來檢索,但是其實不限定是要作為key的欄位才被列入搜索條件。如果條件符合的回傳資料多於一筆,就只會回傳檢索到的第一筆。
DATA connections TYPE tt_connections.
DATA connection LIKE LINE OF connections.
connection = connections[ carrier_id = 'SQ'
connection_id = '0001' ].
如上例所示,用兩個欄位值對表格connections進行基本檢索,當有符合條件的資料時,就會把找到的第一筆存入connection這個work area之中。
但如果沒找到任何資料,系統將回傳CX_SY_ITAB_LINE_NOT_FOUND錯誤,可以用TRY CATCH避免runtime error。
為了在檢索時能處理多行回傳資料,可以用LOOP AT迴圈提取並處理每筆搜尋到的結果
* 用迴圈處理每筆搜尋到的資料列
* LOOP AT <internal table> INTO <target>WHERE <condition>.
LOOP AT connections INTO connection
WHERE airport_from_id <> 'MIA'.
"處理資料列"
...
ENDLOOP.
WHERE後接的條件運算子可以包含AND,OR,=,>,>=,<,<=,<>以及BETWEEN。
資料表除了查詢外,有時也會有更改資料內容的需求,這時可以使用一種變更資料的方法:先用workarea抓取資料列,在變更workarea內的值之後,使用語法MODIFY TABLE把資料覆寫回對應的表格內。
"宣告表格與work area"
DATA carriers TYPE STANDARD TABLE OF st_carrier
WITH NON-UNIQUE KEY carrier_id.
DATA carrier LIKE LINE OF carriers.
"取得資料存入work area"
carrier = carriers[ carrier_id = 'JL' ].
"改寫work area內的資料"
carrier-currency_code = 'JPY'.
"將work area覆寫回資料表"
MODIFY TABLE carriers FROM carrier.
由於系統會根據work area內的值來複寫至對應的表格列,這種方式也是一種鍵存取。
注意,為了在存回表格時仍能識別原本參考的鍵值在哪行,MODIFY TABLE僅能變更非鍵值的欄位。
"宣告表格與work area"
DATA carriers TYPE STANDARD TABLE OF st_carrier
WITH NON-UNIQUE KEY carrier_id.
DATA carrier LIKE LINE OF carriers.
"編輯空work area內的資料"
carrier-carrier_id = 'LH'.
carrier-currency_code = 'EUR'.
"將work area覆寫於指定的索引列"
MODIFY carriers FROM carrier INDEX 1.
當單純使用沒有TABLE關鍵字的MODIFY字段,由於使用索引值INDEX後方接的整數或integer參數來決定欲存入的資料行,將不會限制變更欄位是否為key。
當我們需要大量變更資料列時,可以先用LOOP迴圈抓取資料列,並在迴圈內變更workarea內的值之後,使用語法MODIFY TABLE把資料覆寫回對應的表格內。
DATA carriers TYPE STANDARD TABLE OF st_carrier
WITH NON-UNIQUE KEY carrier_id.
DATA carrier LIKE LINE OF carriers.
"用迴圈一筆一筆存取資料"
LOOP AT carriers INTO carrier
WHERE currency_code IS INITIAL.
"編輯空work area內的資料"
carrier-currency_code = 'USD'.
"將work area覆寫回資料表(隱式的依照索引回填)"
MODIFY carriers FROM carrier.
ENDLOOP.
在上述範例中,先抓取出每個currency_code為空的資料列,並於work areacarriers中編輯,再用MODIFY複寫回表格。
此時MODIFY雖然沒有指定索引值,但仍能在LOOP迴圈中匹配相應的資料行。如果MODIFY被放在LOOP迴圈外而無指定索引值,就會觸發non-catchable 錯誤。
明天是Internal Table 與 ABAP SQL的使用~


 iThome鐵人賽
iThome鐵人賽