
在前一天的內容中,我們透過設計提交 Simple Baseline 和 Retrieval-based Method 來間接地確認 hidden testset 是不是和 trainset 一樣,大部分來自 Persuade 2.0 Corpus。
然而很遺憾地發現,事情沒有那麼簡單,testset 似乎沒有和 Persuade 2.0 Corpus 有任何重疊的資料。
目前確定 trainset 至少來自兩個不同的 source: Persuade 2.0 Corpus 和另外一個來源;而 hidden testset 則很有可能來自那一個來源。
| Dataset | Size |
|---|---|
| Kaggle-Only | 4,436 |
| PERSUADE-Only | 13,125 |
| Kaggle-PERSUADE | 12,871 |
既然如此,一個新的問題產生了:
Persuade 2.0 和另外一個來源的 essay(Kaggle-Only) 有什麼差別、這些 essay 的內容是在討論什麼、有什麼特性是相通的?以及這兩種來源的 essay 在分數的分佈上又有什麼區別呢?

(圖片擷取自1)
🔎 Findings:
max_seq_lenth 在這之間的pretrained model。開始實際著手分析這些 essays 的主題分佈吧!
首先,一樣是把 train data 中的 essay 都轉成 embeddings:
from InstructorEmbedding import INSTRUCTOR
# Embedding model
EMB_MODEL = 'hkunlp/instructor-xl' # 'BAAI/bge-large-en'
embedding_model = INSTRUCTOR(EMB_MODEL)
# Compute essay embeddings (max_seq_length = 512, embeddings size = 784)
instruction = "Represent the essay statement: "
documents = []
for essay in essays:
documents.append([instruction ,essay])
embeddings = embedding_model.encode(documents, show_progress_bar=True, batch_size=32)
有了 embeddings 之後,我們就可以借助 BERTopic 來進行主題建模(Topic Modeling)。關於 BERTopic 的詳細原理與使用方法介紹可以參考2。
# UMAP
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=SEED)
# Clustering
min_cluster_size = 30 # We don't want small clusters
hdbscan_model = HDBSCAN(min_cluster_size=min_cluster_size, metric='euclidean', cluster_selection_method='eom', prediction_data=True)
# Extract ngram
top_n_words = 25
vectorizer_model = CountVectorizer(ngram_range=(1,3), min_df=2, stop_words="english", strip_accents="unicode")
representation_model = KeyBERTInspired(top_n_words=top_n_words, nr_repr_docs=5, random_state=SEED)
topic_model = BERTopic(language="english", top_n_words=top_n_words, embedding_model=embedding_model, umap_model=umap_model, hdbscan_model=hdbscan_model,
vectorizer_model=vectorizer_model, representation_model=representation_model, calculate_probabilities=True, verbose=True)
topics, probs = topic_model.fit_transform(documents=essays, embeddings=embeddings)
// Visualize 前面照到的 top 24 個 topic,並顯示每個 topic 的9 個關鍵字。
chart = topic_model.visualize_barchart(top_n_topics=24, n_words=9, width=512)
chart.show()
🔎 Findings: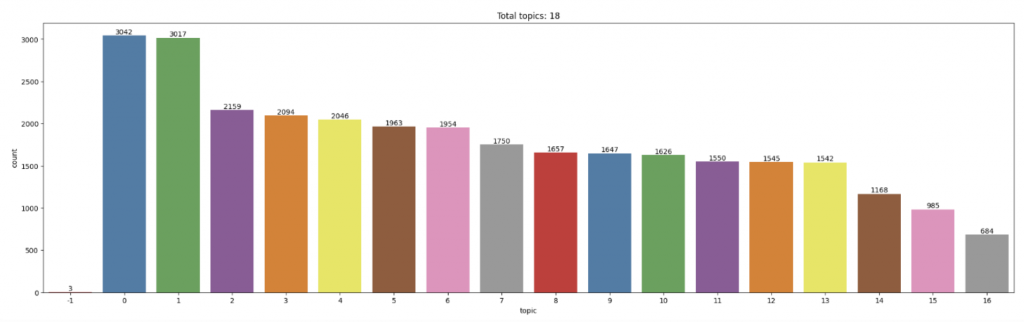
最後 BERTopic 是找到 17 個主題,其中 -1 那個類別是沒辦法被歸類的其他 17 個 topics 的 essay 就會被分類到 -1 ,還好只有 3 篇。
視覺化如下(只呈現前三個 topic)。Topic 0 應該是和情緒、臉部情緒等相關的內容;Topic 2 的 essay 應該是和地球科學等相關的內容;Topic 3 是和線上教育、在家線上學習等內容相關。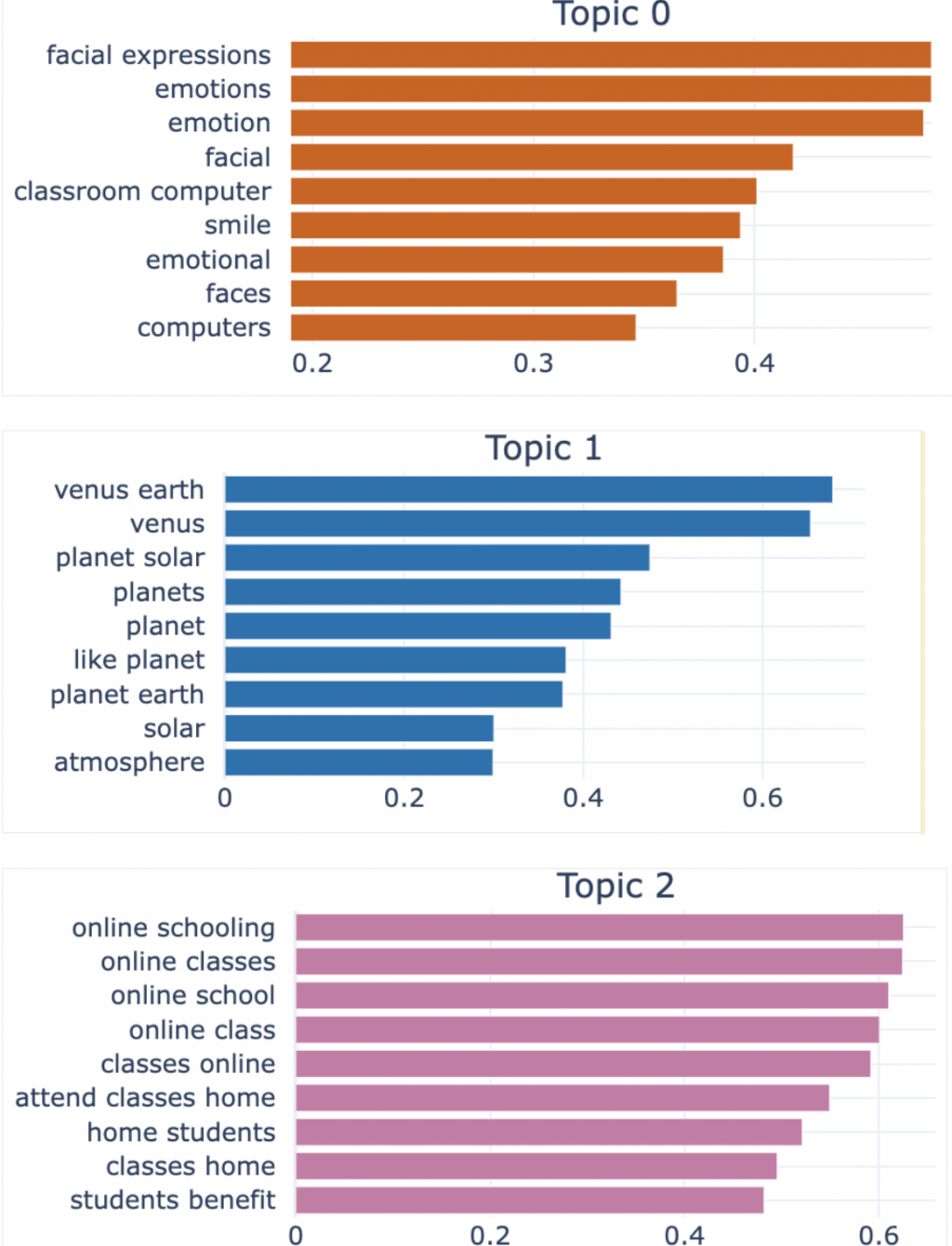
下圖為 17+1 個 topic 的代表 keywords 以及是來自哪部分 dataset 的可視化結果: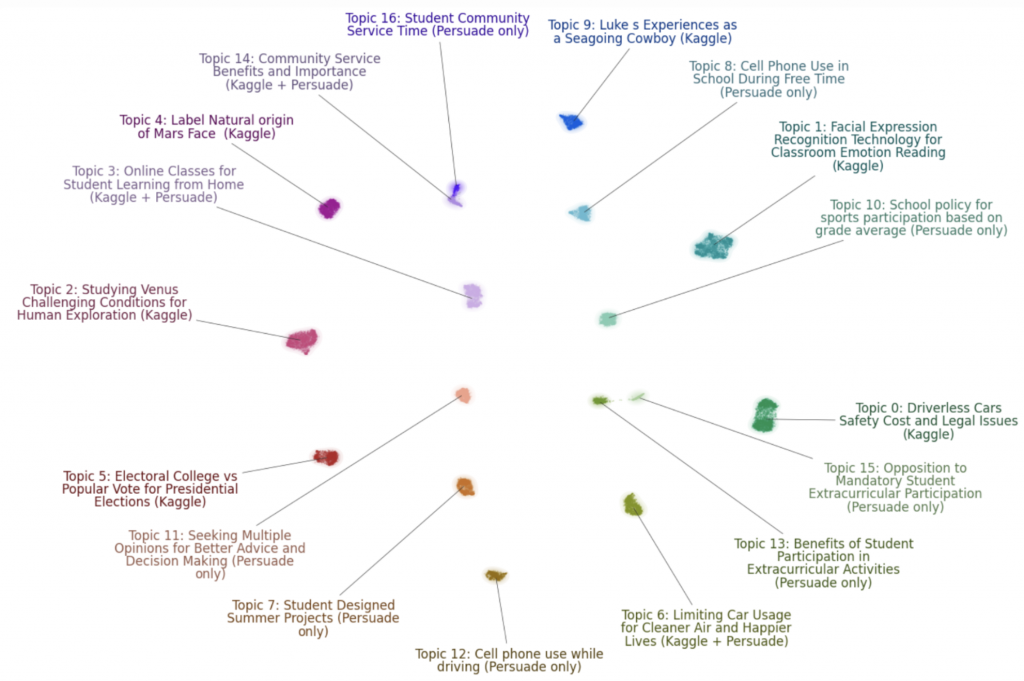
🧐 有了整體的主題分佈後,也許你會好奇:
那 taining data 中的 Kaggle-only 和 Kaggle-PERSUADE essays ,在主題分佈上會不會也有差異呢?
我們可以把 train_df 新增一個 column 叫做 'topic',把 BERTopic 預測的 topic 填上去;再新增一個 column 叫做 'source‘,把該 essay 是 kaggle-only/kaggle-persuade/persuade-only的標籤放上去,就可以輕鬆得到上面的圖以及下方的表格。
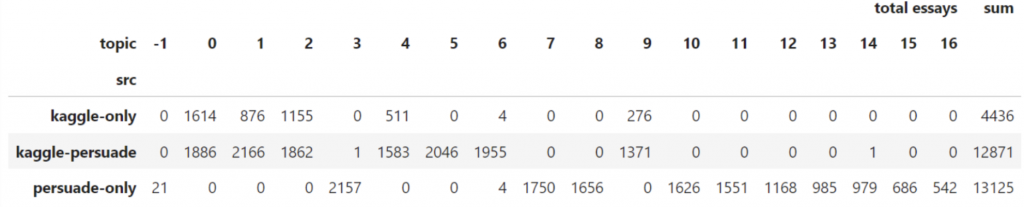
🔎 Findings: 可以發現 Topic3, Topic14 都只有 1 篇,可能是一些 corner cases。
所以最後,比較合理的想法是考慮 topics 3, 7, 8, 10, 11, 12, 13, 14, 15, 16 ,這些只有出現在 PERSUADE 2.0 的 topics:
Online course/classes (3).
Student summer projects (7).
Cell phone use in school (8).
School policy for sports participation (10)
Asking advice/opinion for decision making (11)
Cell phone use while driving (12).
Student extracurricular activities (13, 15).
Student community services (14, 16).
以及 topics 0, 1, 2, 4, 5, 6, 9 這些同時出現在 Kaggle 和 PERSUADE 2.0 的 topics:
Driverless cars safety cost and legal issues (0).
Emotions/facial expressions recognition (1).
Solar planets exploration (Venus, Mars) (2, 4).
Voting/Election (5).
Limiting car usage for cleaner air (6).
Experience as seagoing cowboy (9).
🧐 有了這些主題分佈後,下一步我們想了解的就是:
不同 topics 之間會有怎麼樣的分數分佈呢? 會不會有某些 topic 特別容易拿高分,某些特別容易拿低分呢? 主題和分數之間會有某種特定的關係嗎?
🔎 Findings:
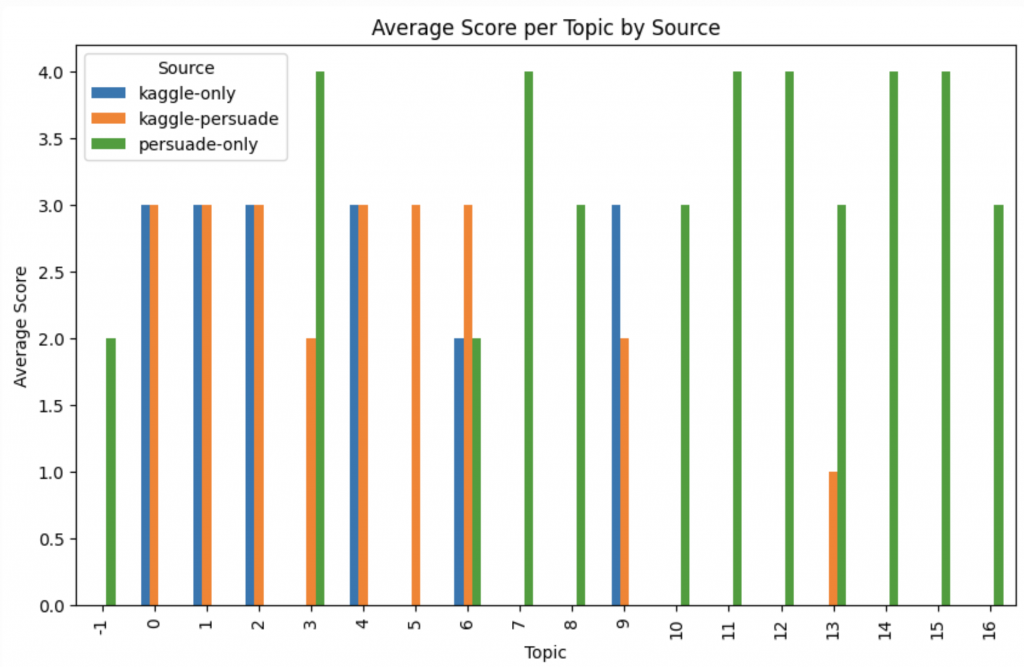
如果只關注 Kaggle-only 和 kaggle-persuade,可以發現在其中兩個 topics(topic 6, topic 9) 的平均分數上有差異(差一級),這意味可能這兩種不同來源的 dataset 有不同的打分標準。
除了用 topic 來分類 essay,由於 Persuade 2.0 Corpus 本身有提供學生寫的該篇 essay 的題目/主題,這邊稱為 Prompt Name,一共有 15 種不同的 prompt name,例如其中一個 Prompt Name 是:Phones and driving,所以屬於這個 prompt name 的 seeay 都是在討論關於現代手機、交通工具等的議論文。

(Persuade 2.0 Corpus Dataset 示意圖)
Prompt Name 這個資訊是本題主辦方提供的 data 所缺乏的,但是透過前面的探索,我們其實可以 link training data 中的其中 12,871 個 essay back to PERSUADE 2.0 Corpus。因此我們也可以獲得這一萬多筆 essay 的 prompt name,就能利用來進一步分析 dataset。
簡單的資料處理後,我們發現 training data 中來自 Kaggle-PERSUADE 的 essay 分別出自下面這七個 Prompt: 'Driverless cars', 'Does the electoral college work?', 'Facial action coding system', '"A Cowboy Who Rode the Waves"', 'The Face on Mars', 'Exploring Venus','Car-free cities'。
和前面探索 topics 一樣,我們也同樣好奇不同 prompt 的分數分佈。
你會發現每個 Prompt 的分數分佈都不太一樣: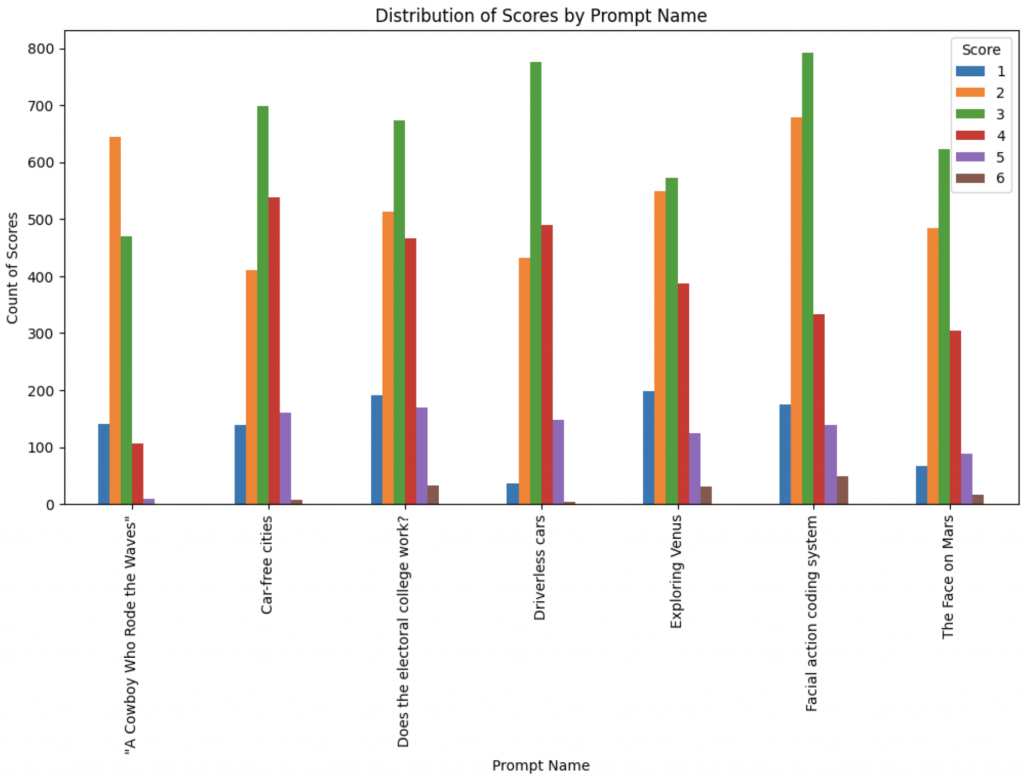
有了 prompt name 這個額外資訊後,討論區有人提問:
🤔 雖然沒辦法在 Persuade 2.0 Corpus 找到一模一樣的 test data,但會不會 test data 的 essay ,也和 trainset 一樣,是根據這 7 個 prompt name 所寫的呢?還是說,test data 完全出自新的未知的 prompt?
如果出自新的 prompt,那會不會是來自 PERSUADE Corpus 的剩下 8(15-7)的 prompt? 還是完全全新的、甚至未出現在 PERSUADE Corpus 的 Prompt 呢?
在一連串問題轟炸下,也許你會忍不住在心裡質問:
到底為什麼要去探究這些,直接混在一起爆 train 一波不就完事了嗎?
因為從前面的觀察來看,train data 包括兩種不同的來源,這兩種來源可能是來自不同的評分者或是程度不同的學生,因此似乎在相同的 topic 上有不同的分數偏好;從上圖也能發現不同 Prompt 有不同的分數分佈,例如: "A Cowboy Who Rode the Waves" 這個 Prompt 大部分都拿偏低的 2 分,但是其他 Prompt 的 essay 卻大部分都可以拿到中間分 3 分。
Hidden Test Data 可能很幸運和 training data 有類似的分數分佈,也有可能又是新的未看過的分佈。
我們為了避免 model 過度 fitting 在 training data 上的某些 topic or prompt or 其他擁有某些特定 feature 的 data 上,我們通常在比賽會使用 cross-validation(CV) 的方式,透過合理的切割 data 的方式,在不同部分的 training data 上訓練,希望每個訓練出來的 model 都能學到不同 feature 的分數分佈。
最終在 inference 的時候,再把所有 model 合成起來(透過平均所有預測結果或是 majority vote 等方法)得到最終預測結果,盡量確保最終的這個預測結果,是眾多模型分別考慮不同因素後綜合做出的決定,來緩解潛在的 overfitting problem。
Cross-Validation 在 Kaggle 等資料科學競賽中被大量的使用,並且要用什麼樣方法切分訓練數據,往往每個團隊都會發展出自己的策略。
❓❓到底要用什麼樣的策略切割 train/validation set 來訓練模型,才能讓 local 這邊跑出來的 CV 分數和 LB(Leaderboard) 分數的 gap 越小越好呢❓❓
越小的 gap 代表在你的 CV 策略下訓練出的模型,能越成功地 transfer 到 hidden testset 上,所以 CV, LB 的分數差不多;反之,如果差很多,通常會是 CV 比較高 LB 比較低,那很有可能就是訓練出的模型 overfit 在已有的這些數據上了。
回到 prompt 本身,參賽者兼網友3 他提出了一個有趣的做法:
根據這七個不同的 prompt 來做 GroupKFold(7 folds),每次都會有一個沒有出現在 training set 過的 prompt 被保留,然後屬於該個 prompt 的 data 就被收集歸類到輪次的 validation set 裡面。
下方是 GroupKFold 的簡單示意圖(擷取自:Visualizing cross-validation behavior in scikit-learn)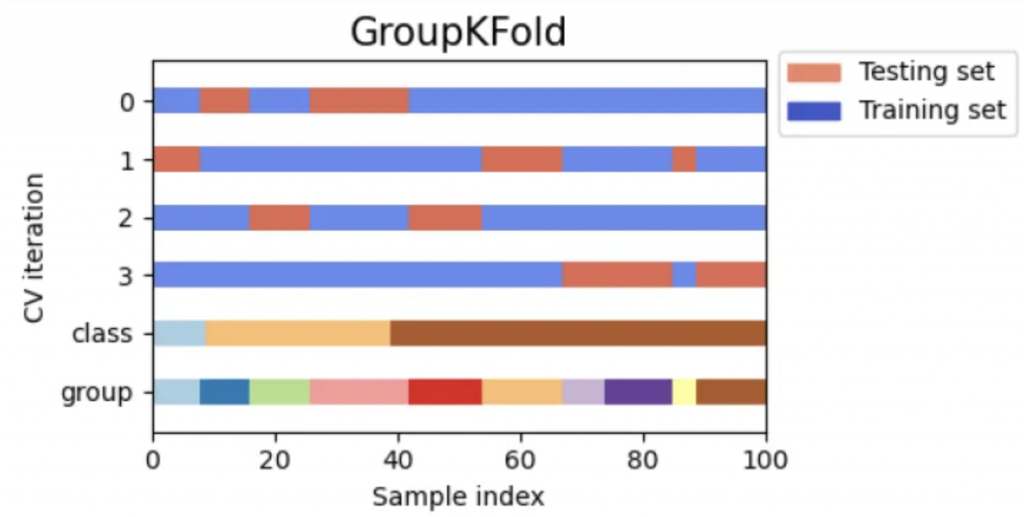
只是還有四千多筆 training set 沒有 prompt name 的資訊怎麼辦?
於是,網友 1 他用現有的那一萬兩千多筆有 prompt name column 的 data,訓練一個 deberta classification model,目標是根據輸入的 essay 預測它是屬於哪一個 prompt name,這個模型的 F1 macro score 幾乎到 1.0,performance 非常好! 於是他就用這個 deberta model 去幫剩下那四千多筆 data 標註它的 prompt name。
結果發現,那四千多筆數據幾乎都被分到其中某5個prompt裡面。
好了!
所有主辦方提供的 training data 都有自己的 prompt name 了~
現在就可以用 GroupKFold 切成 7 fold 來做 cross-validation 訓練我們真正的自動評分模型。
🔎 Finding:
原始 random shufle 後直接做 kfold 得到的分數是:CV 0.8300, LB 0.789;但是在根據 prompt name 做 GroupKFold 後得到的分數是:CV 0.7921, LB 0.806。
雖然 CV 分數變低,但和 LB 的 gap 變小了,LB 的分數也比較高。這代表之前的做法模型們可能都 overfit 在某些特徵上,所以在 CV 的分數虛高了,一上傳到 LB 上分數就大降;改良 CV 策略之後的模型顯然有較好的 transferability。
探索完 training data 中關於 prompt name 的分佈,按照慣例我們就會思考 testset 是否和 trainset 一樣,也都是來自這 7 個 prompt 的 essay?
❓❓如何驗證 hidden test set 是不是也出自這七個 prompt 呢❓❓
網友 4 提供了一個有趣的解法:
他上傳一份檔案,這份程式碼包含剛剛訓練好的分類 essay 是屬於哪一個 prompt name 的 model,會自動幫 hidden test data 預測它屬於哪一個 prompt name,並在下面新增下列這段代碼:
if len(df_test[df_test.prompt_name=="Prompt A"]) > len(df_test)*0.14:
df_sub = None
df_sub.to_csv("submission.csv", index=False)
如果你在終端顯示 error,代表被預測為 Prompt A 的 test data 超過整體 test data 的 14%,那這意味 test data 大概是有包含出自 Prompt A 的 essay 了。
因為假如 test data 完全不包含這 7 個 prompt,那這個 predictor 在預測的時候應該會開始亂猜,也就是說每個類別被預測到的機率平均大概是 100 / 7 = 14% 。如果測試發現 Prompt A 的佔比超過整體資料量的 14%,那就很有理由相信這些多出的 data 應該是真的屬於 Prompt A 的 essays 了。
透過替換 Prompt A 到其他 Prompt 可以逐一測試 test set 到底包含哪些 prompt。
最終在網友的共同努力下,最終發現 test set 應該包含 train set 的其中 5 個 prompt,但不排除還有包含其他新的、未出現在 train set 的其他 prompt。
另外補充,最終獲得第三名的作者 5 針對 prompt name 分佈也跟前面所提的一樣,提出三種假設:
接著他根據 prompt name 切出 7-folds 分別訓練之後,觀察 local CV, 以及 LB 上的 public score:
🔎 Finding: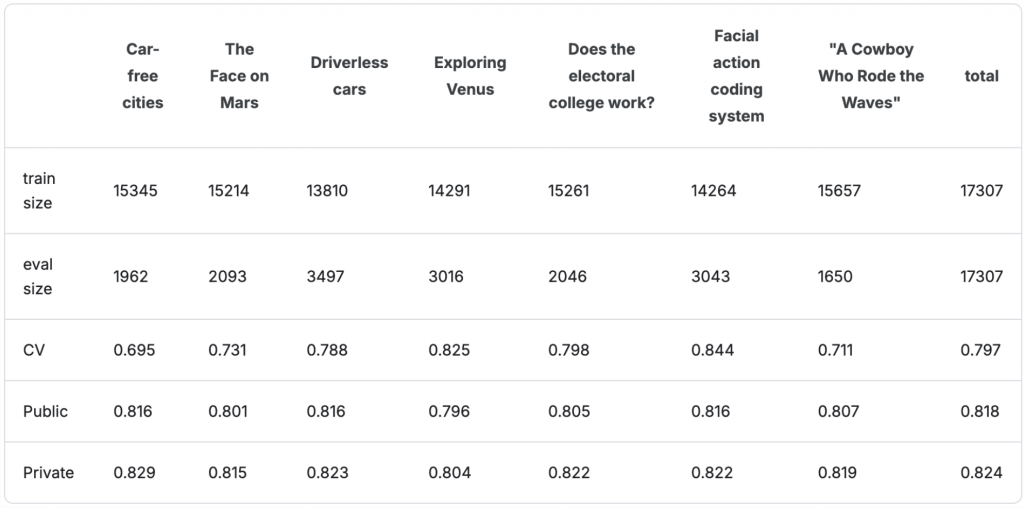
發現不同 folds 的 CV 分數差滿大的,最差的是 0.695 最好的有到 0.844,然而在 LB Public 卻沒有觀察到類似的現象,基本上不同 folds 的分數都在 0.80~0.81 之間,所以初步可以認定第一種假設應該不成立。因為如果 test data 所包含的 prompt name 和 train data 完全一樣,那 Public Score 應該也會和 CV 一樣根據不同的 fold 分數有高低分較大的差距。
算是從另一個角度來回答「如何驗證 hidden test set 是不是也出自這七個 prompt 呢?」這個問題!很有趣吧XDD
既然前面講了那麼多方法在旁敲側擊觀察 train/test 不管是特徵、主題、prompt 或是他們的分數分佈有什麼差異,網友 6 提出了一個更有意思的方式:
直接訓練一個 model 讓他來幫我們區分 train/test。
不過當然做這件事情不是真的想知道現在這筆 data 是來自 train 還是 test set,因為這不用分,主辦單位給我們的 training data 都在 train.csv,test set 都在 test.csv。
這件事的意義是在用一種間接的方式觀察 train/test 的資料會不會差很多?
他的假設是這樣:
如果今天這個模型他在這個「分類目前這筆 data 是 train or test data」這個二分類任務上做得非常差,那也許 train/test data 本質上其實沒有什麼明顯差異,導致模型根本就分不太出來只好亂猜,那我們就很有理由相信,我們在已有的 training data 上 fine-tuned ,他的結果應該會和 LB 上的 test set 差不多;反之如果這麼分類模型超輕鬆就分出這個是 train or test data,那就代表這兩者可能有很顯著的差異,最終 CV, LB 的分數可能就會差很多,我們在 local 這邊做的實驗結果可能都不會反映在 test set 上。我們可能要去分析到底是差在哪邊、共同之處又在哪邊。
知道他的假設後,他的做法如下:
首先先做一個小實驗:
把 trainset 隨機一分為二,一半打上 0 的標籤,一半打上 1 的標籤,然後把 essay 的文字轉成 TF-IDF 的 feature,訓練一個 LGBM 根據 tf-idf 的特徵去區分哪些 train data 是 0 哪些是 1。
我們預期 training data 應該都是類似的,因為是隨機幫這些 data 打上 label 的,沒什麼理由說因為 xxx 所以這筆 data 的 label 應該是 0 or 1,所以這個 LGBM 應該會學得很差。
train = pd.read_csv('/kaggle/input/learning-agency-lab-automated-essay-scoring-2/train.csv')
test = pd.read_csv('/kaggle/input/learning-agency-lab-automated-essay-scoring-2/test.csv')
kfold = StratifiedKFold(n_splits = 2, shuffle = True, random_state = 1)
for num, (train_index, val_index) in enumerate(kfold.split(train, train['score'])):
train.loc[val_index, 'target'] = int(num)
kfold = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 2)
for num, (train_index, val_index) in enumerate(kfold.split(train, train['score'])):
train.loc[val_index, 'fold'] = int(num)
vec = TfidfVectorizer(max_features = 10000)
data = vec.fit_transform(train['full_text'])
train_ind = train[train['fold'] != 0].index
valid_ind = train[train['fold'] == 0].index
x_train, x_valid = data[train_ind], data[valid_ind]
y_train, y_valid = train['target'][train_ind], train['target'][valid_ind]
train_dataset = lgb.Dataset(x_train, y_train)
valid_dataset = lgb.Dataset(x_valid, y_valid)
params = {
'objective': 'binary',
'metric': 'auc',
'boosting': 'gbdt',
'seed': 42,
'num_leaves': 31,
'learning_rate': 0.1,
'n_jobs': -1,
}
early_stopping = lgb.early_stopping(50, verbose = 50)
model = lgb.train(
params = params,
train_set = train_dataset,
num_boost_round = 10000,
valid_sets = [train_dataset, valid_dataset],
callbacks = [early_stopping]
)
pred = model.predict(x_valid)
score = roc_auc_score(y_valid, pred)
print(f'Roc Auc Score: {score}')
最後在 train set 做的這個小實驗所算出來的 AUC 分數是 0.51。
算出來的 AUC 意義如下:
AUC = 0.5 表示模型的區分能力與隨機猜測無異。
AUC < 0.5 表示模型的表現比隨機猜測還差。
AUC 接近 1.0 表示模型能夠很好地區分正負樣本。
符合預期,模型幾乎是隨機在猜測這筆 data 的 label 是 0 or 1,因為模型根本找不到什麼依據來區分。
接下來提交一份code,這份code會開始用真正的 train / test 來訓練,前者 label 0 後者 label 1 。
train = pd.read_csv('/kaggle/input/learning-agency-lab-automated-essay-scoring-2/train.csv')
test = pd.read_csv('/kaggle/input/learning-agency-lab-automated-essay-scoring-2/test.csv')
train['target'] = 0.0
test['target'] = 1.0
train = pd.concat([train, test], axis = 0, ignore_index = True)
kfold = StratifiedKFold(n_splits = 3, shuffle = True, random_state = 1)
for num, (train_index, val_index) in enumerate(kfold.split(train, train['target'])):
train.loc[val_index, 'fold'] = int(num)
vec = TfidfVectorizer(max_features = 10000)
data = vec.fit_transform(train['full_text'])
train_ind = train[train['fold'] != 0].index
valid_ind = train[train['fold'] == 0].index
x_train, x_valid = data[train_ind], data[valid_ind]
y_train, y_valid = train['target'][train_ind], train['target'][valid_ind]
train_dataset = lgb.Dataset(x_train, y_train)
valid_dataset = lgb.Dataset(x_valid, y_valid)
model = lgb.train(
params = params,
train_set = train_dataset,
num_boost_round = 10000,
valid_sets = [train_dataset, valid_dataset],
callbacks = [early_stopping]
)
pred = model.predict(x_valid)
score = roc_auc_score(y_valid, pred)
print(f'Roc Auc Score: {score}')
因為沒辦法在 kaggle 的評分系統上直接看到這個 print 出來的分數,我們只能看到產生的 submission.csv file 和 ground truth 比對後的分數,所以需要加上一些小技巧。
作者在code的最後加上這一段:
if score >= threshold:
sub = pd.read_csv('/kaggle/input/learning-agency-lab-automated-essay-scoring-2/sample_submission.csv')
sub.to_csv('submission.csv', index = False)
如果最後所有 test data 算出來的 score 大於某個 threshold,他就不填分數,讓最後跑出來的成績是 0.0;如果沒有大於該閾值的話,他就填一個固定的結果,讓最終的成績是某個 baseline 的數值。
透過這種方式測試,最終結果如下:
Baseline Score -> 0.737
Threshold 0.99 -> 0.737
Threshold 0.80 -> 0.737
Threshold 0.70 -> 0.737
Threshold 0.60 -> 0.0
以上結果代表,testset 的結果顯示,AUC 大概在 0.6~0.7之間。這意味 testset 和 trainset 微微有些不同,但沒有到非常不同。我想可以呼應前面的觀察,testset 應該是有一些 essay 來自新的 prompt name,但如前面的觀察,大部分的 prompt 應該都還是有出現過在 train 裡面的。
寫到這邊,希望沒有把正在閱讀的你搞得暈頭轉向🤯。
今天透過文本資料探勘的起手式:Topic Modeling,以及 score, topic, prompt name 的 distribution analysis ,讓我們對主辦方提供的資料集有更深刻的理解。之後在挑戰相關 NLP 的 Kaggle 競賽時,一開始也可以透過這些方法讓自己和 data 混熟,說不定可以從中產生新的 insight。
像是今天,我們就從對 prompt name 的觀察中,產生「以 prompt name 作為 Cross-Validation 切割數據的依據」這樣的策略,也確實相較原本打亂直接 n-folds ,在 LB 分數上有明顯的提升👏👏。
後面關於更多 prompt name 以及 adversarial validation 等的討論,其實都只是想要回答一個問題:「Hidden testset 和 trainset 的真實差距到底有多遠? 彼此之間有哪些相異與相同之處呢?」。
因為在參加這種比賽,最害怕的就是訓練出來的模型 overfit 在已知的 trainset 上,卻在真正重要的 testset 上有很差的 transferability。因此掌握兩者之間的差距,對於制定後續訓練策略來說,是很重要的事情呦!
明天開始會帶大家一起欣賞前四名的優勝解法,也終於將迎來本賽題的最終章。
今天的這些觀察,都會成為明天他們為什麼會發展出這樣那樣的解法的原因呦!
我們明天見吧!
謝謝讀到最後的你,希望你會覺得有趣!
如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵呦!(希望今年可以堅持完賽QQ
如果有任何回饋和建議,歡迎在留言區和我說✨✨
(Kaggle - Learning Agency Lab - Automated Essay Scoring 2.0 解法分享系列)
