備註: 雖然這個系列的主題圍繞 AI,但今天的內容中 AI 元素稍顯不足,還請大家見諒。
在前一篇文章中,我提到我選擇了 n8n 平台來設計這個自動化流程。起初的構想是這樣的:將 Podcast 音檔上傳到 S3,再利用 Whisper AI 進行語音轉文字。但在實作過程中,我突然發現一個意外驚喜 —— Podcast 的 RSS 鏈接其實已經公開了音檔的 URL,這讓我要上傳的麻煩程序瞬間化為烏有。
這個發現讓我深刻體會到流程簡化的重要性,也為接下來的開發指明了方向。我決定直接利用 RSS 提供的音檔 URL,省去繁瑣的上傳步驟,專注於轉檔和摘要的生成,目標就是要以最簡單、高效的方式完成這個系統。
一開始,我打算繼續挑戰 n8n 和 Divy.ai 這兩套自動化流程工具。我的想法是先從 Podcast 平台(例如 Apple Podcast 或 Spotify for Podcasters)抓取音檔的 URL,最後我選了 Spotify for Podcasters,因為它的原始碼裡面就有 Podcast 的 RSS 資訊,比較好分析處理。
不過,這些資訊藏在 <script> 標籤裡面,要解析出來有點麻煩。為了處理這個問題,我花了些時間寫了一個 Python 腳本來解決。
import requests
from bs4 import BeautifulSoup
import re
import json
def extract_audio_url(podcast_url):
"""
從 Spotify for Podcasters 的特定集數網頁中提取音頻 URL。
Parameters:
podcast_url: Spotify Podcast 集數的網址。
Returns:
str or None: 提取到的音頻 URL,若未找到則返回 None。
"""
try:
response = requests.get(podcast_url)
response.raise_for_status()
except requests.RequestException as e:
print(f"Error fetching the URL: {e}")
return None
# 查找包含 `window.__STATE__` 的 <script> 標籤
soup = BeautifulSoup(response.text, 'html.parser')
script_tag = None
for script in soup.find_all('script'):
if script.string and 'window.__STATE__' in script.string:
script_tag = script.string
break
if not script_tag:
print("Couldn't find the script tag containing 'window.__STATE__'.")
return None
# 使用 RegEx 提取 JSON 字串
match = re.search(r'window\.__STATE__\s*=\s*({.*?});', script_tag, re.DOTALL)
if not match:
print("Couldn't extract JSON data from 'window.__STATE__'.")
return None
json_str = match.group(1)
try:
state = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"Error decoding JSON: {e}")
return None
# 根據提供的 HTML 結構,提取 `episodeEnclosureUrl`
try:
episode_enclosure_url = state['episodePreview']['episodeEnclosureUrl']
except KeyError:
print("Couldn't find 'episodeEnclosureUrl' in the JSON data.")
return None
decoded_url = bytes(episode_enclosure_url, "utf-8").decode("unicode_escape")
return decoded_url
if __name__ == "__main__":
# 範例網址:台灣通勤第一品牌 —— EP144 此處應有本
podcast_episode_url = "https://podcasters.spotify.com/pod/show/taiwanfirstcommuter/episodes/EP144-e18ghfi"
audio_url = extract_audio_url(podcast_episode_url)
if audio_url:
print(f"Extracted Audio URL: {audio_url}")
else:
print("Failed to extract the audio URL.")
意外發現,不管是 n8n 還是 Divy.ai,它們提供的 Python 執行環境都不支援外部套件。這表示我只能用 Python 3 內建的標準函式庫,我嘗試改寫使用 urllib 加上正則表達式來抓取和解析 HTML 內容。而且,這兩個平台也沒辦法直接呼叫 Web API 來抓外部資料,只能先用它們的 HTTPS 功能模板取得 HTML,再把資料傳給 Python 功能模組處理。
更麻煩的是,Divy.ai 對 HTTP 回應內容的大小有限制,超過 1MB 就沒辦法處理。因為 Spotify for Podcasters 由於把整個 RSS 內容都放在 meta data 裡面,網頁內容很容易就超過 1MB,所以 Divy.ai 在這個階段就被我淘汰了,畢竟之後轉出來的逐字稿應該也很容易超過 1MB。
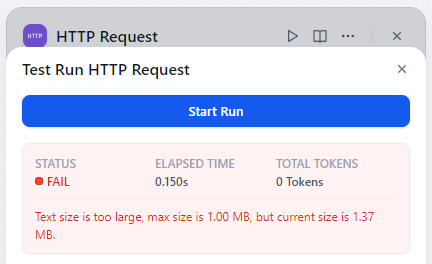
後來,我在 n8n 上試著做一些處理的時候,嘗試將 HTTP 功能模組抓取到的資料傳遞到 Python 能模組,卻一直碰壁。而且,n8n 的除錯工具功能陽春,說明文件寫得也不夠詳細,讓我在探索 n8n 的 Python 執行環境上浪費了不少時間,最後只好放棄使用它。
經過多次嘗試和調整,我最終決定採用 Serverless 的方式來解決這些問題。我將腳本部署在 DigitalOcean 的 Function 上,這樣不僅可以自由使用像 Requests 和 BeautifulSoup 這樣的外部套件來解析 HTML,還能利用 DigitalOcean 每月的免費額度來滿足需求。
這次的經驗讓我深刻理解到,像 n8n 擅長的是流程控制,且內建了許多功能模組;Divy.ai 則擅長打造 AI workflow 或 RAG 應用。然而當這些自動化流程缺乏你所需的功能時,以我目前的使用體驗來看,強烈不建議在它們上面執行 Python 程式碼,這只會浪費時間
轉向 Serverless 方案,不僅能夠更靈活地運用各種外部套件,還能提升整體效率。若 Low-code 平台無法滿足需求,強烈建議直接轉向 Serverless 方案,避免在半殘的運行環境上寫 Python 程式碼浪費寶貴時間。
自動化遇阻?Serverless 是王道!
自動化遇阻?Serverless 是王道!
自動化遇阻?Serverless 是王道!
很重要所以要講三次
目前,我已經完成 Podcast 節目 URL 到逐字稿的整套流程。我的 Webhook 可以接收 Podcast 節目的 URL,透過 DigitalOcean 的 Function 擷取音檔的實際 URL,然後加上一些參數,將音檔的 URL傳遞到 Replicate 的 Whisper API 進行語音轉文字的處理。由於這是一個非同步的過程,我額外加上了一組 if-else 迴圈,每隔五分鐘呼叫 GET API,檢查任務是否完成。任務完成後,我就能取得轉好的逐字稿。
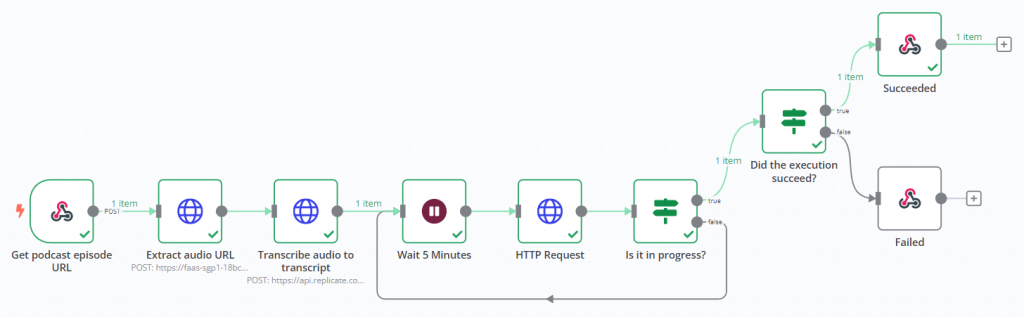
實際測試的效果相當不錯,從 Podcast 節目 URL 中提取音檔並順利轉譯成文字的流程已經運作良好。接下來,我將開始進行 AI 摘要的生成,這也是我計畫明天要完成的工作。讓我們拭目以待,期待明天的成果吧!
在打造自動化系統的過程中,選擇適合的工具和方法非常重要。Low-code 平台如 n8n 和 Divy.ai,雖然在某些領域有優勢,但遇到特殊需求時反而可能綁手綁腳。這時候不妨考慮把這部分工作交給 Serverless 方案,這樣一來,不只能更彈性地運用各種外部套件,還能大幅提升整體效率。希望我的經驗分享,能給正在尋找自動化解決方案的您一些幫助!


 iThome鐵人賽
iThome鐵人賽