今天想和大家分享一個有趣的 AI 技術應用,靈感來自光明頂創育執行長洪大倫老師在 Facebook 上的分享。他利用 FLUX LoRA 這個 AI 影像生成模型,成功生成了自己的形象照。我也忍不住親自嘗試了一番,過程既簡單又有趣,現在就來和大家詳細介紹。
首先,需要準備訓練模型所需的資料,也就是多張自己的照片。這些照片應該涵蓋各種角度和表情,特別是頭部和臉部的特寫。照片的數量越多越好,能為模型提供更豐富的參考資訊。不過要注意,照片越多,訓練所需的時間和資源也會相應增加。
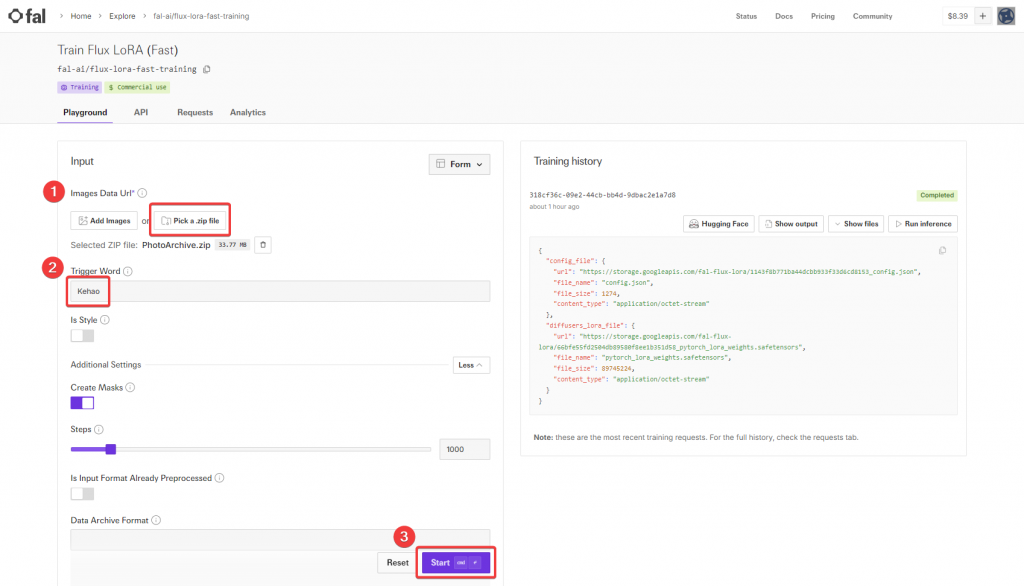
洪大倫老師提到他對照片進行了排序,但我這次並沒有特別整理,只是隨意拍攝了二十幾張頭部照片,請家人幫忙拍攝。然後,將這些照片壓縮成一個 .zip 檔案,準備進行模型訓練。
洪大倫老師使用了 Replicate 平台進行訓練,這個平台我們之前也介紹過,提供方便的 GPU 運算服務。我之前曾使用 Replicate 來進行 Podcast 的 Whisper 語音轉文字以及說話者識別。然而,這次我選擇了另一個我偏好的 GPU 平台 —— Fal.ai。我相信這兩個平台都能達到相似的效果,選擇哪一個純粹取決於個人習慣和需求。
額外提一下,Fal.ai 提供了一個特殊版本的 Whisper v3 模型,稱為 fal-ai/wizper。如果你的需求不包含說話者識別,這個模型會是更快且更經濟的選擇。而在這次的影像生成中,我選用了 Fal.ai 平台下的 FLUX LoRAs 模型,模型位置為:fal-ai/flux-lora-fast-training。
訓練過程其實非常簡單:
上傳照片:可以透過 Web UI 介面一張張上傳照片,或是一次上傳一個壓縮檔。我選擇後者,直接上傳了準備好的 .zip 檔案。
設定觸發詞(Trigger Word):這是非常重要的一步。你需要設定一個觸發詞,在之後生成影像的提示詞(prompt)中,只要包含這個觸發詞,模型就會根據你提供的照片生成對應的影像。這樣,模型就知道要生成的是你設定的特定人物。
開始訓練:上傳照片並設定好參數後,就可以開始訓練了。在 Fal.ai 平台上,整個訓練過程不到五分鐘,非常迅速。
訓練完成後,就可以使用這個模型來生成你的形象照。為了測試效果,我從網路上找了一個描述性的 prompt,並加入了我的觸發詞。以下是完整的 prompt:
Kehao, a charismatic speaker, was captured giving a speech. He has a round face, clean shaven, and wears black-rimmed glasses with rounded rectangular frames. He gestures with his left hand and his expression is very vivid. He held a black microphone in his right hand and spoke passionately. The man was wearing a navy blazer and a white T-shirt. He also had a simple black lanyard hanging around his neck. The lanyard badge has the word "Kehao" on it. Behind him, a blurred background with logos on white banners, a professional conference environment.
生成後的影像效果令我非常滿意,感覺就像真的參加了一個研討會並被拍攝下來一樣。這次的體驗讓我深刻感受到 AI 影像生成的廣泛應用和無限趣味。
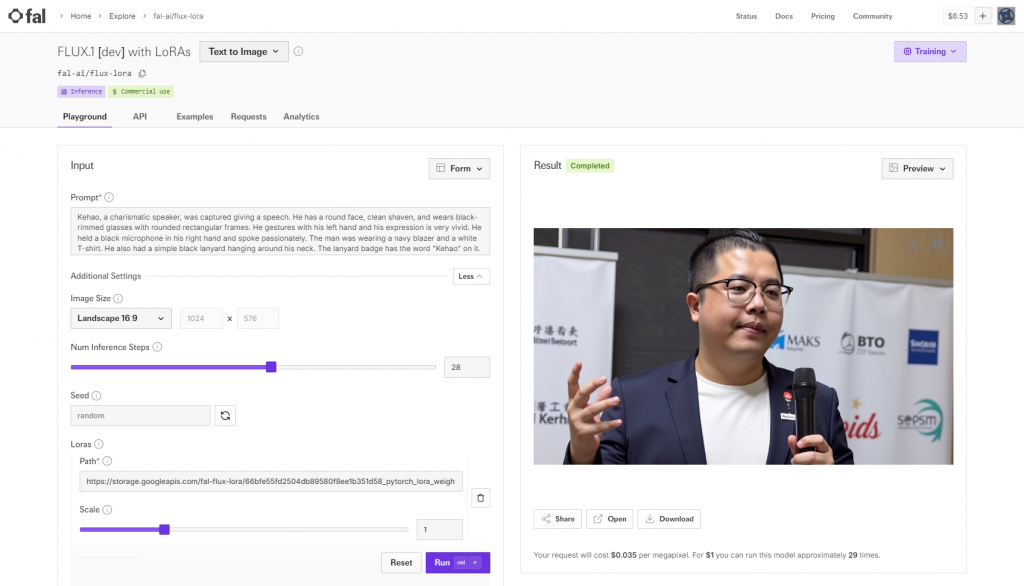
透過這次的嘗試,我體驗到了利用 FLUX LoRA 模型生成個人形象照的便捷性和樂趣。如果你也想製作一張獨一無二的形象照,不妨試試這種方法。感謝洪大倫老師的分享,讓我有機會學習並實踐這項技術。
以上就是我的技術分享,感謝大家的閱讀!希望這篇文章能對你有所啟發,也期待你能分享自己的 AI 影像生成體驗。


 iThome鐵人賽
iThome鐵人賽