上一篇談我們怎麼做文件開發,這篇從管理的角度切入。
從進到這個組織開始,我感覺一直在嘗試沒碰過的領域跟專案,搭著 AI 的浪潮,文件跟 GPT 是我能一路走到現在的金牌導師。
現在每次碰到沒做過的事情,翻文件是我首要想到的任務(或是查組織的 notion 跟 slack 記錄,看看前人是怎麼搞出現在這些神秘的玩意兒)。
在寫 dbt 文件時,在考慮要寫什麼內容時,原則就是:寫!知道的通通寫進去就對了!寫個五行十行的模型說明的不在少數。
這種短篇幅的說明,不管再怎麼多,都不到煩人的程度,然而若是少說了一些,後人又要到處搜索、查原始碼看資料是怎麼被記錄的,身為第一批後人,萬萬是不想要讓這些煩心事債留子孫。
哪個時間點因為 XX 功能取消了,所以後續不會有這個資料;這邊因為有過什麼 bug,所以需要這樣特別的篩選或轉換才能正常運行,一字不漏地寫進文件中。
如上一篇,資料模型分成 staging, intermediate, marts。
在 staging 中,文件內容通常記錄原始資料是怎麼產生這個欄位資訊的,我們經過了什麼調整等,在這個階段,盡可能把前後端的處理記錄下來,避免未來又需要花大把時間翻前後端的程式碼。
在 marts 中,文件主要提供給其他業務單位,讓其他單位能知道有哪些資料可以利用,因此在這邊必須用更白話的方式說明,此外,會在此階段加上資料表更新頻率等說明。
在 intermediate 中,由於前(staging)後(marts)都已經寫過說明了,其實大部分欄位的說明有些重複,主要會想看文件的人也都是資料工程師們,因此在這個階段中,蠻多複雜的轉換過程,我們直接將理由、操作手法等記錄在 sql code 中,說明各個 cte 為何要進行這些轉換。
欄位的部分就不太需要再多著墨,模型本身倒是可以做一些說明,為何要做這些轉換、有哪些下游表會用到等等。
不一定要追求百分之百的覆蓋率,重點是要考慮受眾、實用性,畢竟團隊中也就幾個人,負責業務繁多,寫文件要精準。
絕對不是因為懶得寫。
在 dbt 中,文件可以用 markdown 管理,我們另外開了一個資料夾,管理所有 markdown 文件,再使用 {{ doc(...) }} 的方式連結。
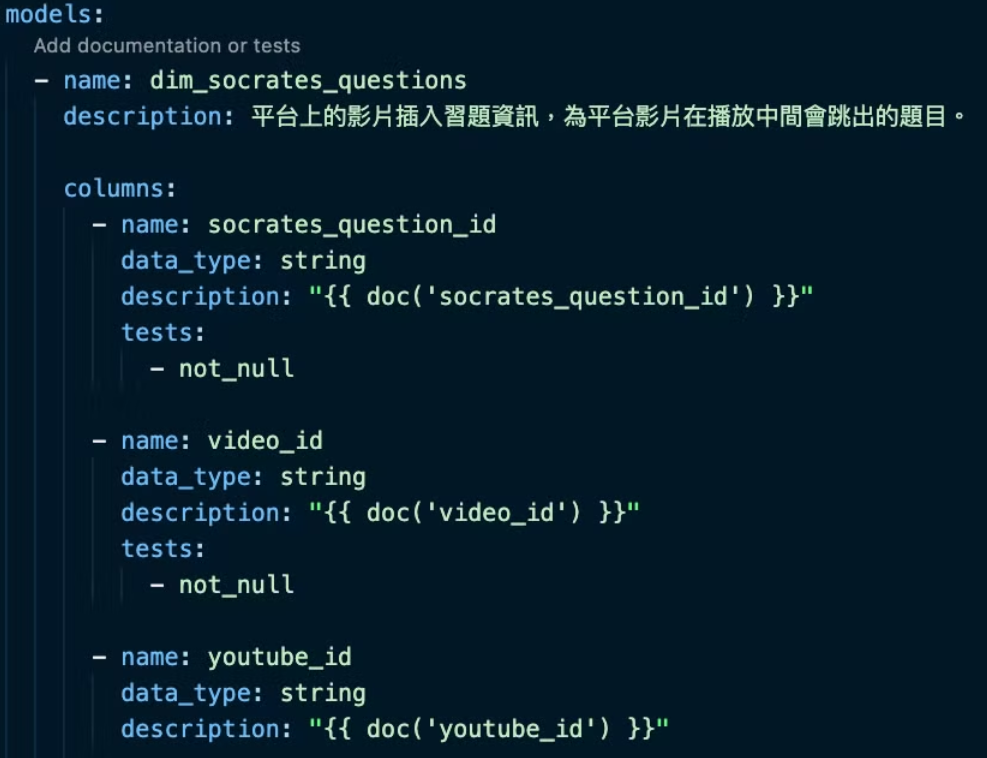
為什麼要拉出去另外管理呢?
我期待達成的目標是若多次使用同個欄位的資料,即可以此方式作使用。其一當然是不用重複的複製貼上,另外則是可以維護 single source of truth,即使已經在同一個 repo 了,若是同個欄位出現在很多不同的資料表中,還是有可能文件說明不一致,用 markdown 來管理,可以確保我同個欄位的說明完全一致,有變動時能同步改動。
因此,資料表的說明就不用 markdown 管理了,因為每張資料表應該都有不同的描述。
看起來很美好,不過在這邊會遇到一個問題,不同資料表中的 created_at 可能定義有所不同,是因應不同行為、不同方式所觸發的,在這樣的情況下,我創造了一個規則,針對較容易重複的欄位,我們就在前綴加上一些幫助辨識的歸類,像是時間紀錄可能會因為使用素材不同而有所差異,就將欄位文件加上前綴:video__created_at, problem__created_at, exam__created_at,可以因應整個資料庫的設計方式去調整這樣的規則,雖然我猜這可能也不是最好的方法,像是前綴樣式的規範,擔心會過於繁瑣等等的。不過大體來說,目前還蠻有效解決問題的。

