在上一篇文章中,我們簡單介紹了 OpenTelemetry,並且探討了Sentry 如何整合它來增強對應用的監控能力。而當我們深入了解 OpenTelemetry 時,會發現它其實是圍繞著三大支柱進行數據收集和觀測的:trace、metric 和 log。這三者共同構成了現代應用觀測性的核心。這一篇,我們將逐一解析這三個觀測性概念。
Trace 是 OpenTelemetry 中最常見的觀測數據形式之一,它主要用來追蹤請求在分佈式系統中的流轉路徑。每個 trace 都會包含許多 spans,而每個 span 代表應用中一個操作的執行階段。
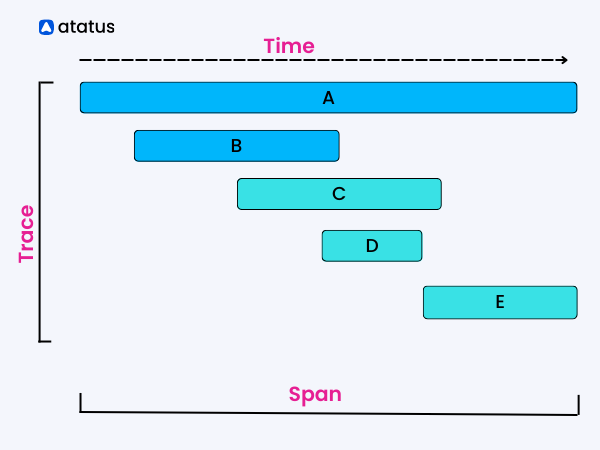
image from What are Spans in Distributed Tracing? | Ataus
透過 trace,我們可以非常清楚地看到一個請求從前端到後端、再到資料庫、再到其他服務等等的整個路徑。在有異常時間發生時,這樣的觀測數據可以幫助我們快速找出是錯誤是從哪個鏈路拋出的;或者一個請求耗時過長,我們也可以透過觀測全鏈路來定位那些耗時操作。
metric 在 Opentelemetry中,是設計為多功能、支援各種類型數據的觀測指標,可以依據工程團隊的需求,從簡單的Http請求計數、到複雜的系統資源利用率都可以採集。
在 Opentelemetry中的 metric 類型,主要有
通過分析 metrics,開發者可以評估應用的整體性能,並在系統過載或其他異常情況發生前,提前進行警告和修復。
在 Opentelemetry 中的log,主要是提供了一個定義框架,如timestamps、resource identifiers和attributes等,確保日誌的跨工具和跨平台性。
同時,這樣做的目標也是為了讓log 能夠和 trace 、 metric 聯繫起來,實現全面的可觀測性。
OpenTelemetry 為我們提供了 trace、metric 和 log 這三大核心數據,讓我們能夠從不同維度觀測應用的健康狀態和性能。這三者並非孤立存在,而是互相補充,幫助開發者全面掌控應用的運行狀況。
接下來幾篇,我們將會先demo每個觀測數據是如何在 Opentelemetry 中採集並呈現,然後探究其中的邏輯,最後手動實現看看。


 iThome鐵人賽
iThome鐵人賽