今天是學習Python的第17天,居然已經過了一半以上了,我要學習的是正規表示式(Regular Expressions,簡稱 regex),在處理文本資料時,經常需要進行模式匹配、驗證或過濾特定的字串內容。這時,正規表示式是一個很重要的工具。Python 提供了內建的 re 模組來支持正規表示式的操作。
正規表示式是一種用來描述字串模式的語法,它可以非常靈活地搜尋、匹配或替換文本。正規表示式的應用範圍包括驗證電子郵件、檢查密碼強度、從文件中提取特定模式的數據等。
Python 的 re 模組提供了許多方法來處理正規表示式,例如 search()、match() 和 findall()。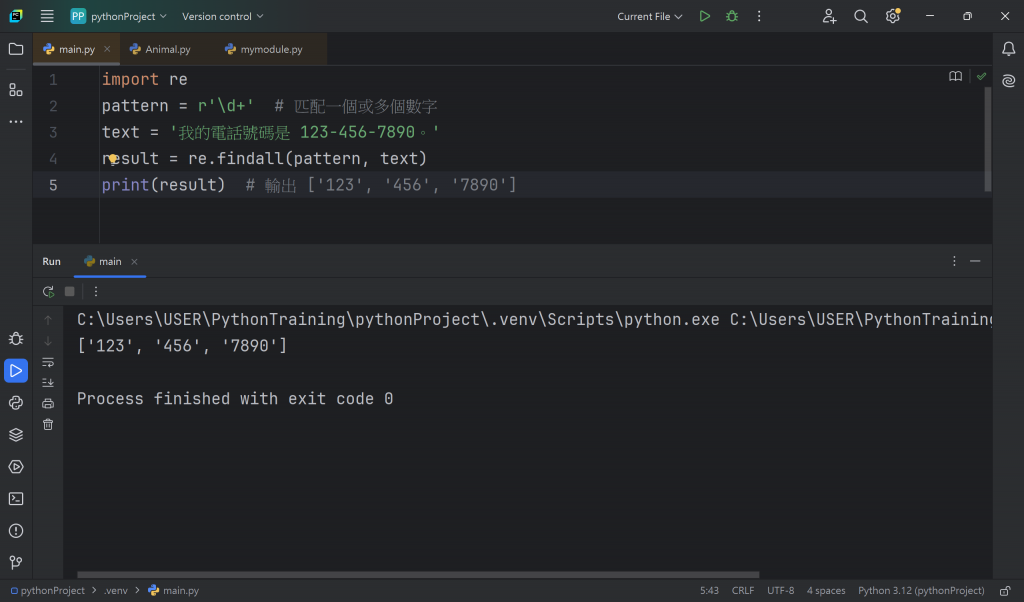
在這個例子中,findall() 會搜尋字串中符合正規表示式的所有部分,並返回一個列表。
.:匹配任意單個字符,除了換行符。
\d:匹配任何數字,相當於 [0-9]。
\w:匹配任意字母、數字或下劃線。
+:表示前面的模式出現一次或多次。
*:表示前面的模式出現零次或多次。
^:匹配字串的開頭。
$:匹配字串的結尾。
除了匹配與搜尋,re 模組還提供了 sub() 方法來替換文本內容,以及 split() 方法來根據正規表示式分割字串。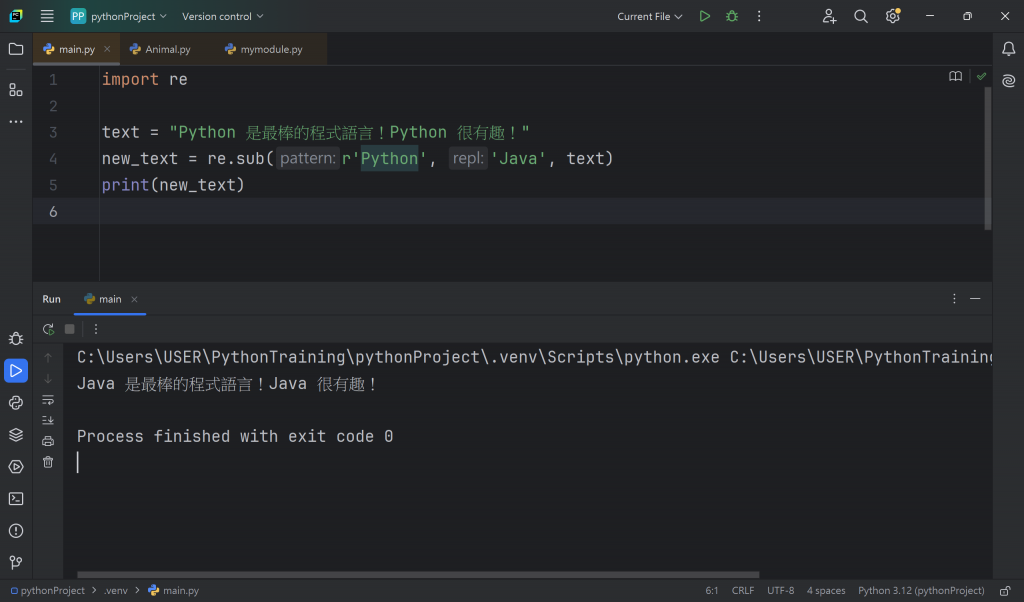
今天的學習讓我了解了如何使用 Python 的 re 模組處理正規表示式,這對於進行字串處理、資料驗證等操作來說非常有用。我在用第二個範例的時候忘了加 import re,程式跑不出來讓我緊張了一下,所以在打程式碼的時候不能忘了任何一個小錫杰,明天我將繼續學習Python的進階知識!加油加油!!

