在剩餘約10天的學習中,我將會學習大量的爬蟲實例,
並試著跟隨製作相關的爬蟲程式,檢驗前20天的學習成果到底如何。
在接下來的時間裡,我會參考
https://www.youtube.com/watch?v=1PHp1prsxIM 的影片內容,
並跟著一步一步實作,以自己的方式進行吸收學習。
那事不宜遲,進行最後衝刺!!!
在第一個實作中,我會爬取在ppt版中的nba區的熱門文章,
並試著將裡面的「標題」、「人氣指數」以及「發文日期」抓取出來,
最後將抓取到的資料利用pandas變成便於閱讀的檔案。
因為各個爬蟲庫之前都已經安裝過了,所以我之後的文章就不會再多做介紹了。
首先,我們就先來看看這次要抓取的網站頁面: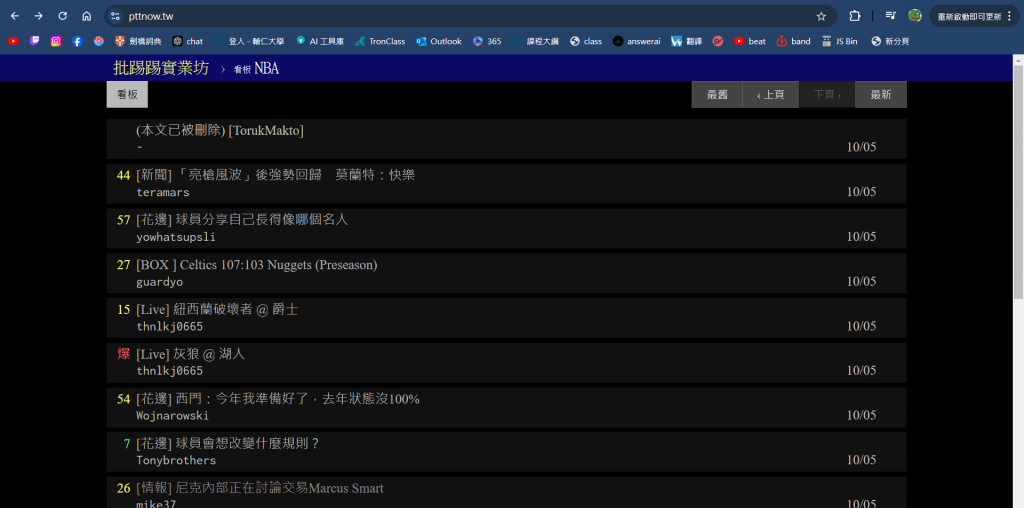
上方就是這次要抓取的ptt的nba版的網站頁面,我們可以在上面看到很多資訊,
例如像是我們等等要抓取的標題、人氣、以及發文日期。
那就先來看我們要打的第一步程式碼: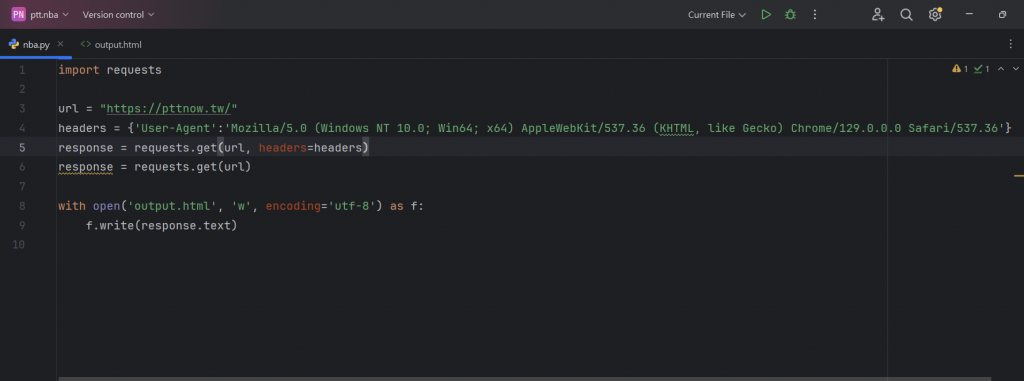
上述就是我們程式碼的第一部份,就是最基礎的環境設置,
設定要爬取的URL、設置反偵測的請求頭、以及使用GET來獲取網頁的HTML。
最後一行稍微複雜一點點,但也剛好是我們在前幾篇講過的輸出模式,
所以這邊也不再贅述了,有興趣的讀者可以自己去翻看看前幾天的文章。
那我們就來看看這個程式碼執行所得到的內容: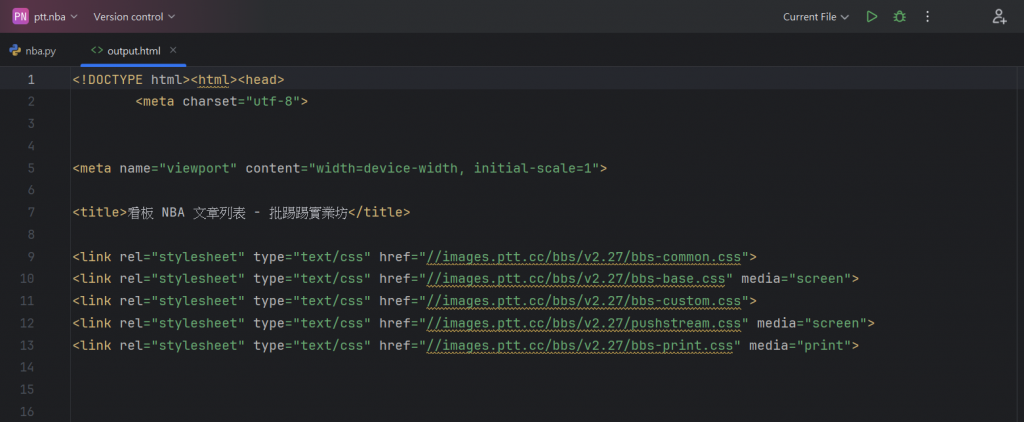
可以看到因為我們是設定成開啟一個HTML檔案,所以我們會抓取到這樣的內容。
上方就是我們所抓取到的HTML內容。
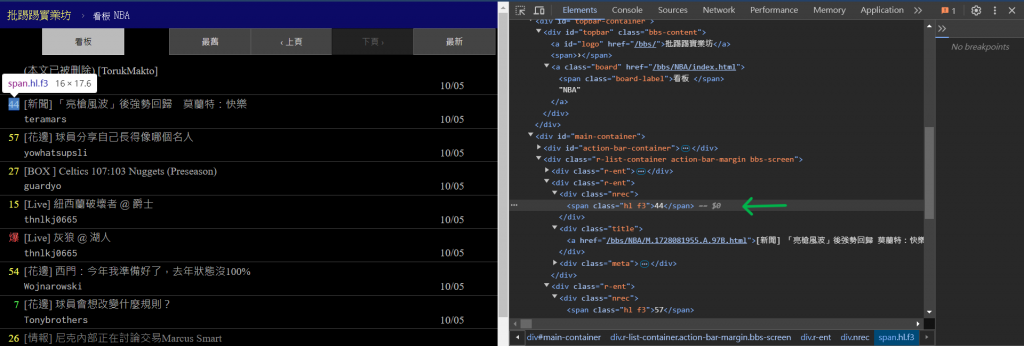
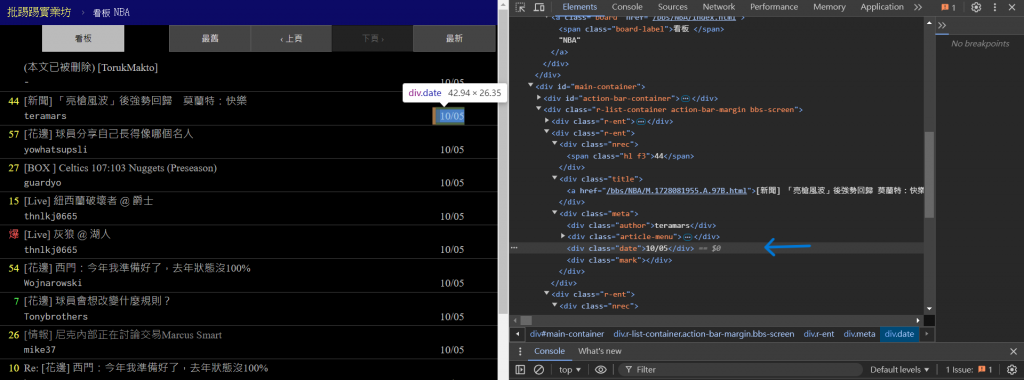
接著,我們就是要一步步的抓取其中的數據,首先先來看看要抓取的資料,
他們各自的HTML編碼,以及他們是如何構成的:
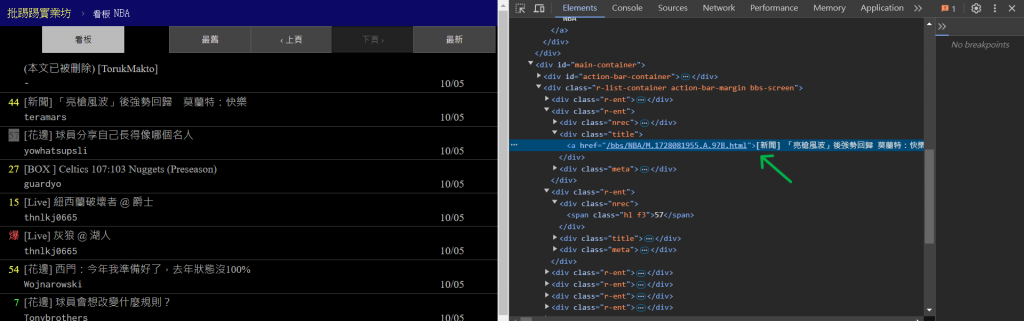
(這邊我就不多解釋,請讀者自行查看HTML碼,後面都會依照上圖資訊撰寫程式碼)
透過用F12開啟該網頁的開發工具,我們就可以清楚的查看到他們的HTML結構碼,
如此就可以安排要如何抓取他們的數據。
接著,我們就先從整個文章類表開始進行抓取: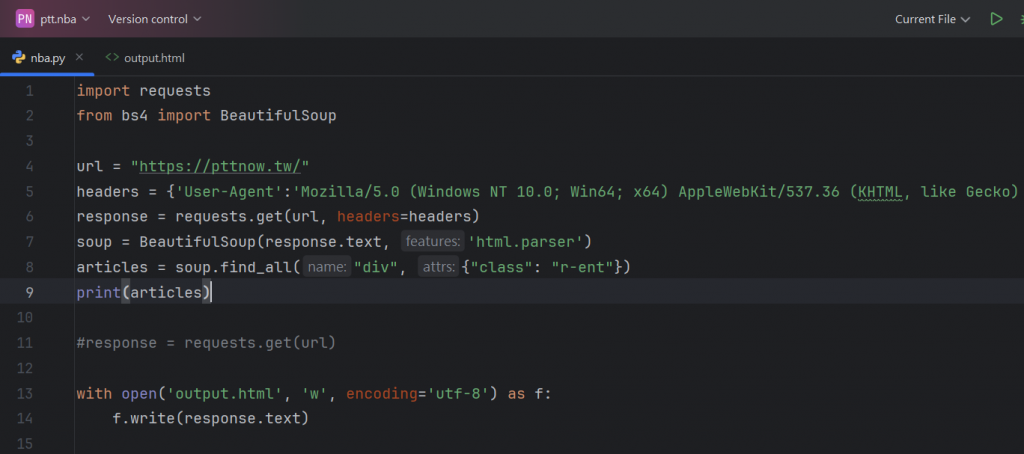
在上述的程式碼中,我們引進了BeautifulSoup這個爬蟲套件,
並且使用了它的 find all() 方法
來抓取元素< div >裡面的類別 ”-r-ent”
(我們剛剛在HTML文件中發現的程式碼,意思是整個文章類表),
那呈現出來的結果如下: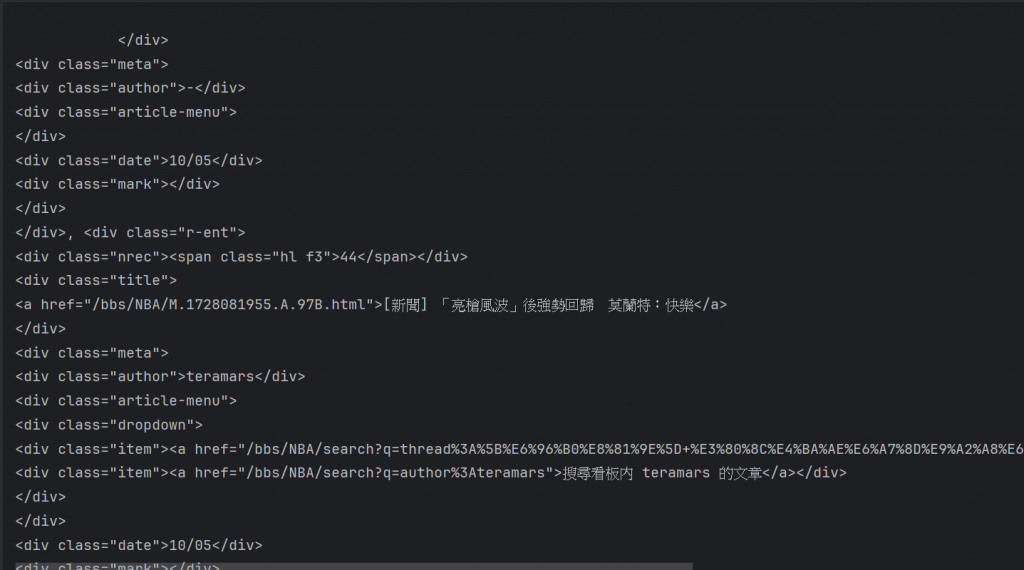
如此就抓取到整個文章格裡面的所有內容了,
裡面就包含了我們剛剛說要抓取的最後三個類別。
下一步,就要來抓取第一個物件 -「標題」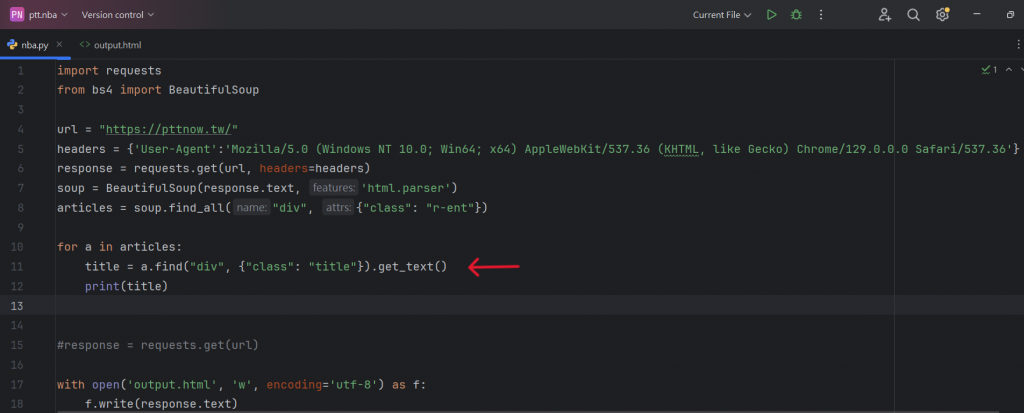
在上面的程式碼中,我們使用了for迴圈讓指令可以對網頁進行不斷的抓取,
並且使用了get指令定義了要抓取的 class - title,
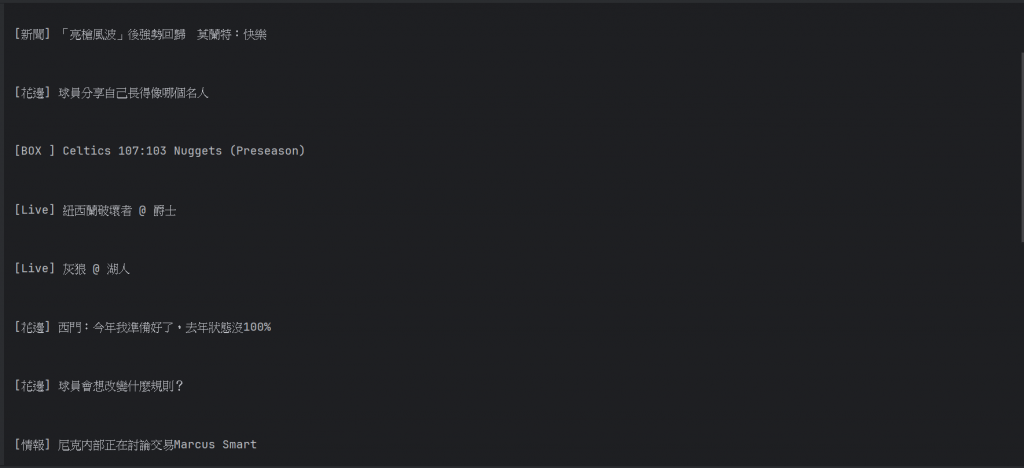
因此我們就可以把標題的內容抓取出來了:
接著就是要來輸入獲得「人氣度」的指令,以下是程式碼:
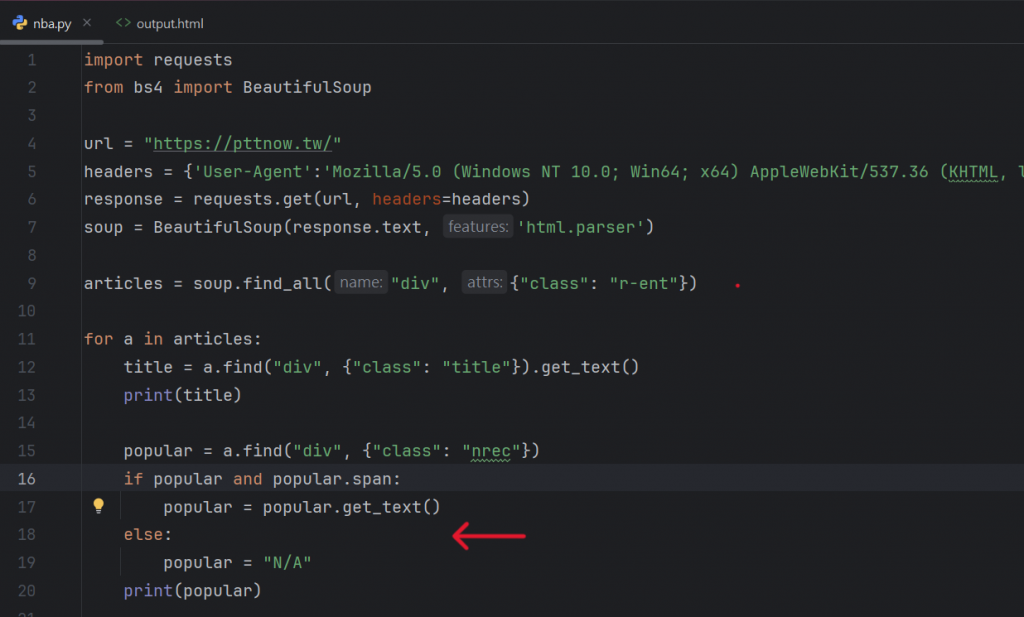
與標題不太一樣,這邊我們新增了一個if/else 機制,這樣當發生找不到元素的情況時,
就會在人氣的那一欄顯示N/A,以此做比較好的呈現。
下方就是執行出來的結果: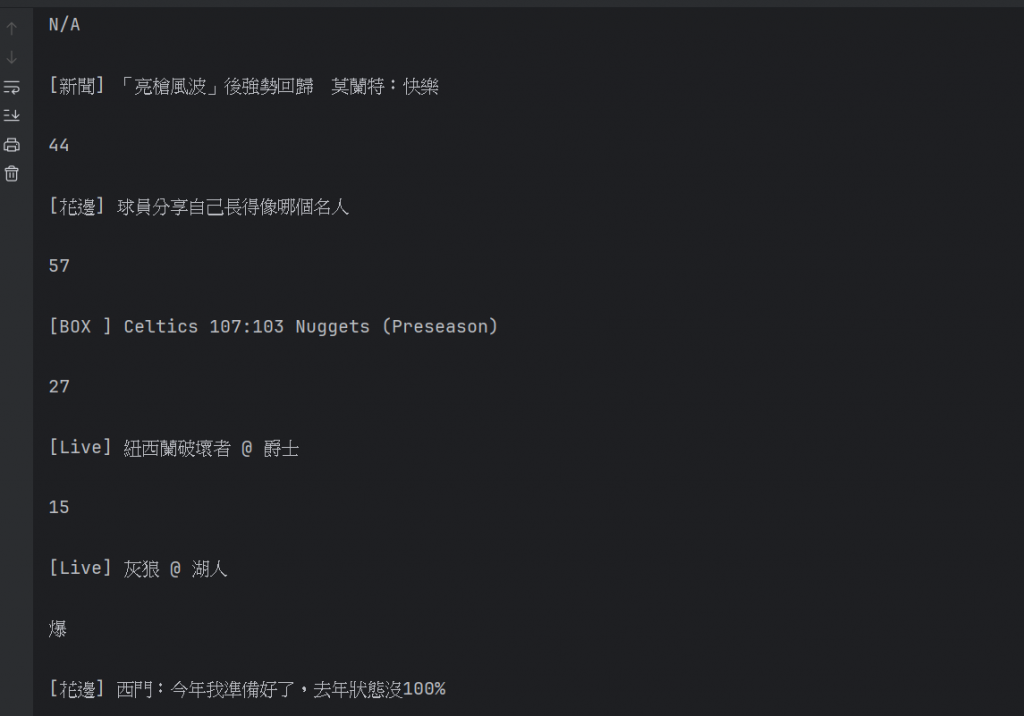
但可以看到,這邊顯示的內容是分開的,當我們想要看一篇文章時,
我們理所當然是希望文章的全部資訊可以排列在一起,
而不是各自分開,
所以我們這邊要把兩個輸出結合在一起,程式碼如下: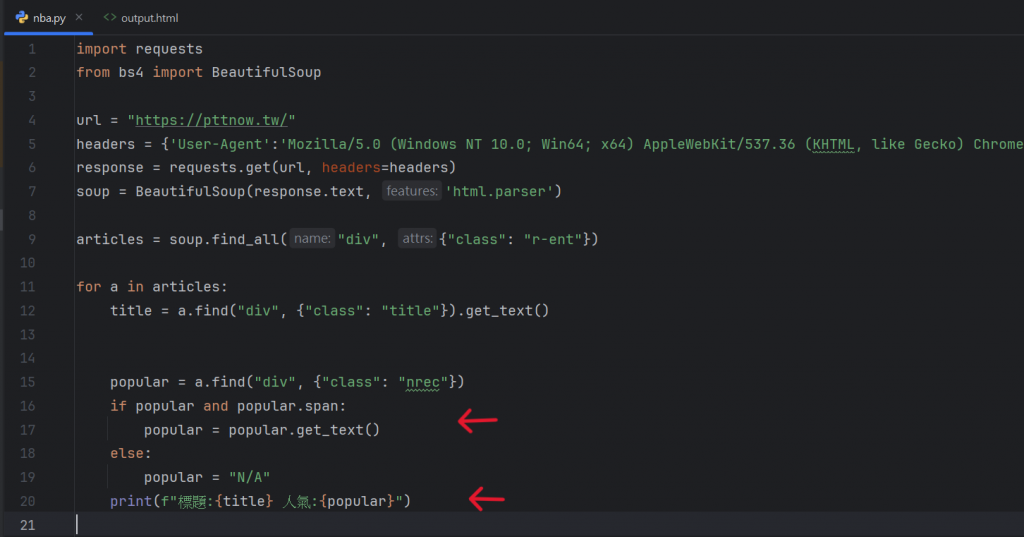
如此我們就可以獲得排版更好看的回覆了。
接著就是抓取最後一個要的資訊 - 「日期」,
那程式碼如下: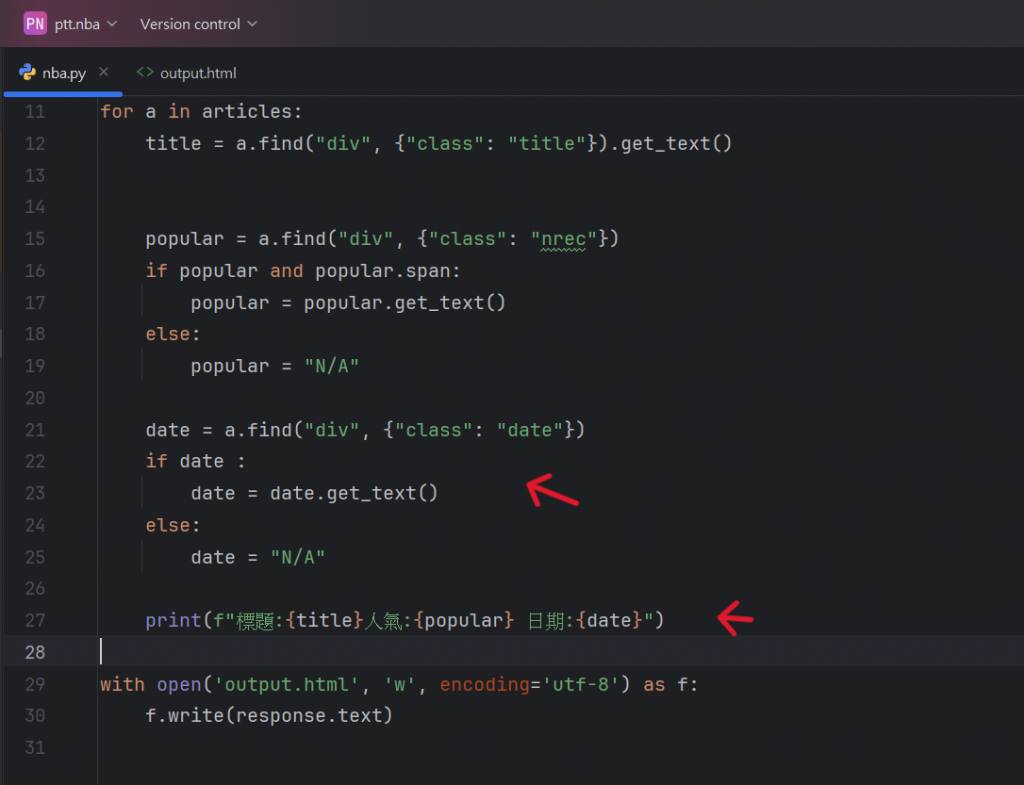
跟新增人氣的內容大致一樣,同樣使用了if/else 機制,並且在最後的
輸出環節將全部的內容結合在了一起,
最後得到我們要的結果: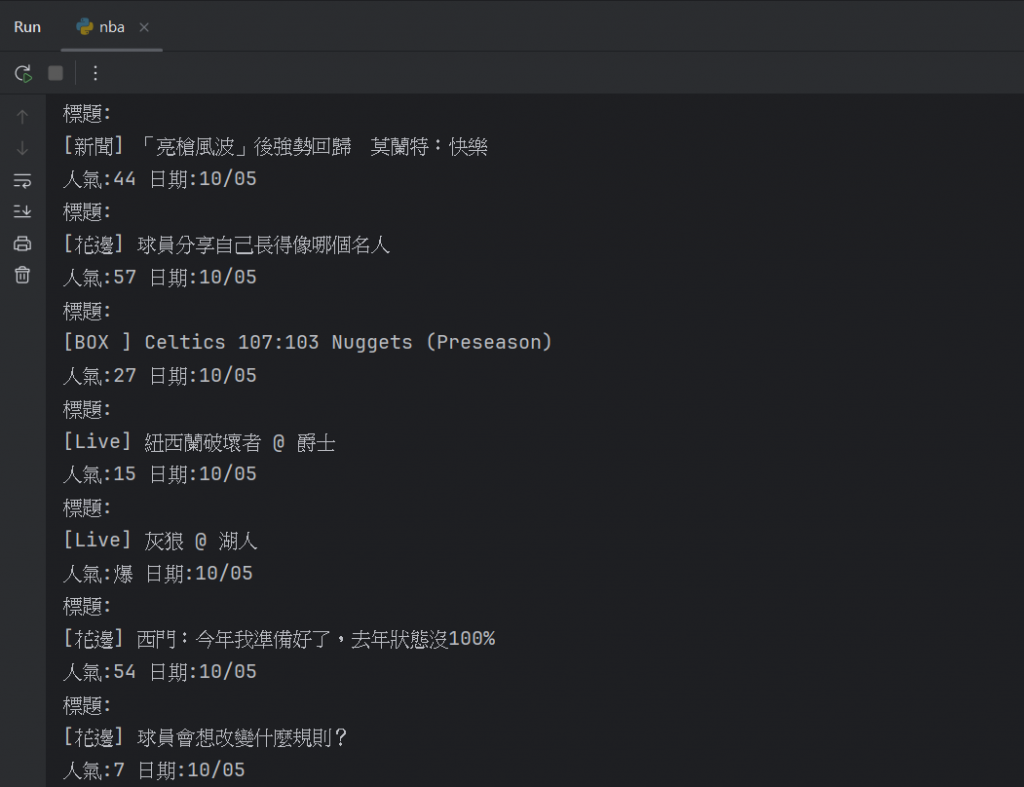
可以特別拿出來講的我想是
print(f"標題: {title} 人氣: {popular} 日期: {date}") 裡面的「小寫f」,
因為我在撰寫的當下有思考一段時間,不太清楚怎麼把三個元素合併在一起呈現。
而 f 其實就是表示這是一個格式化字符串,也稱為 「f-string」。
f-string 是在 Python 3.6 才引入的一種字符串格式化方法,
就是允許你在字符串中直接插入變量的值。
所以我們就可以利用這個方法,來把上面用到的字串合併在一起呈現了。
.
.
.
.
.
.
但,等等,鳩都媽得,我覺得這樣的呈現還是不太好看(對,就是不知足),
我想把一整篇的文章資料改成只呈現在一排裡面。
因此我新增了以下的程式碼:
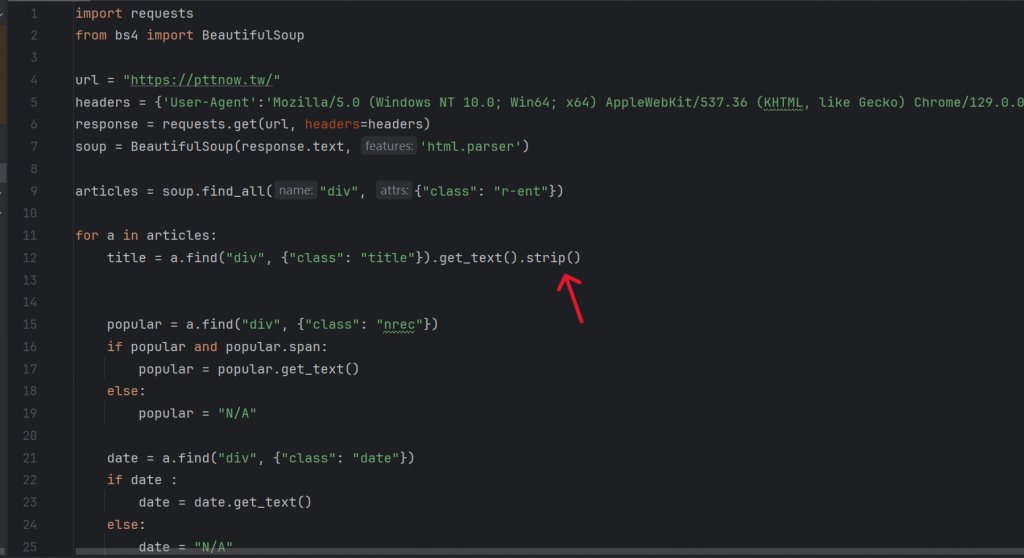
在上面的程式碼中,我其實只新增了strip()方法,
它的功用主要是把一些多餘的換行或空白符號移除,
特別是在網頁元素中經常會有一些不可見的字符,我們就可以用這種方法解決。
(參考資料:
https://www.runoob.com/python/att-string-strip.html)
修改過後,我們就來看看最後的呈現:
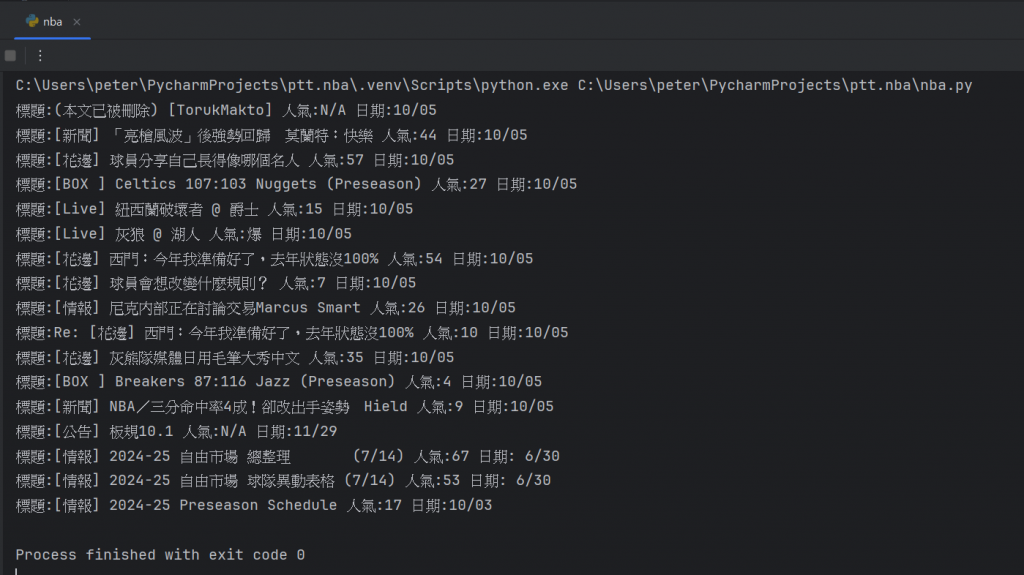
這就是爬取到三個目標後的完整結果了。
(資料轉換...下篇續...)

