在自動化流程中,處理來自 PDF 或影像檔的文字內容是一項常見需求。Power Automate Desktop 提供了實用的 PDF 擷取文字和 OCR 功能,幫助使用者將非結構化的數據轉換為可操作的文本。
簡單補充 OCR(Optical Character Recognition,光學字元辨識)這項技術的簡介供參考,次技術可以從圖片或文件中自動識別並提取文字,讓這些被提取的文字可以進一步被數位化處理。
在本文中,我們會簡介 Power Automate Desktop 中 PDF 擷取文字與 OCR 這兩項功能的差異,以及 OCR 引擎的運作方式及不同情境中的應用。
Power Automate Desktop 的 PDF 擷取文字功能可以有效地從可選擇文字的 PDF 檔案中擷取文字內容。這適用於那些 PDF 中的文字屬於“數位文字”(如來自 Word 文件生成的 PDF),使用者能夠直接選取並複製文字。
然而,這個功能的限制在於它僅能處理那些可以被選取的文字。如果 PDF 是掃描版本,或其中的文字被轉換為圖片,這時候就無法使用 PDF 擷取文字功能,需要使用其他方法來進行文字處理。
OCR(Optical Character Recognition,光學字元辨識)功能是為了處理那些無法直接選擇文字的文件。OCR 能從圖片或掃描的 PDF 中自動辨識出字元,並將其轉換為文本資料。這使得無論文件是掃描影像還是圖片,都能被處理成可供自動化流程使用的文字。
兩者的應用差異:
PDF 擷取文字:適合處理數位格式的 PDF 檔案,運行速度快且結果準確。
OCR 辨識文字:適合處理掃描版的 PDF 或圖片檔案,處理較慢,但能涵蓋更多無法選擇文字的場景。
目前 Power Automate Desktop 內建提供的免費 OCR 引擎有兩種,以下會簡介兩款 OCR 引擎的使用情境,可依照自身需求選用不同的引擎。
Power Automate Desktop 提供的 Windows OCR 引擎是一個簡單、快速的工具,適合處理常見的文字辨識任務。Windows OCR 通常在處理英文或一些常見語言的文字時,能達到不錯的效果。目前也有支援繁體中文,如有繁體中文的辨識需求,以 Power Automate Desktop 內建的 OCR 引擎來說,目前僅能使用 Windows OCR 引擎來達成需求。
另一個可選擇的引擎是 Tesseract OCR,一個 Google 建立的 OCR 引擎,在 Power Automate Desktop 的使用中,有支援德文、西班牙文或是法文……等語言的辨識情境,如有需要可測試看看,有機會能有不錯的辨識程度。
常用到 OCR 的情境有很多,像是發票、報表以及各種單據都很適合透過 OCR 處理。此次會採用 MOMO 購物網的電子發票作為舉例,另外也分享一個小知識給大家參考,以台灣的發票來說,因為電子發票的文字解析度較高,使用下來會比傳統發票的辨識成功度更高,建議若能統一採用電子發票,會比傳統紙本發票更為理想。同樣,如若可以選擇,建議盡可能避免手寫,電子文字的辨識度會來得更好一些。
目標讀取電子發票
RPA 讀取結果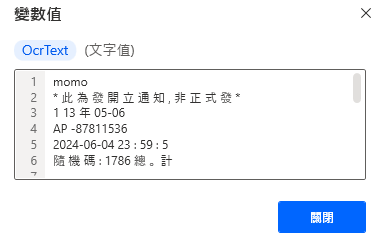
這次用到的功能很單一,僅使用「使用 OCR 擷取文字」此動作。此動作共有 2 區塊可進行設定,第一個是「一般」,第二個是「OCR 引擎設定」。
OCR 引擎類型的設定,此次選擇的是 Windows OCR 引擎,另一個 Tesseract 引擎目前無支援繁體中文,故先不使用。
接著 OCR 來源選擇磁碟上的影像,接著會跳出「影像檔路徑」的欄位,接著填寫檔案位置即可。如有其他需求想直接在畫面或是前景視窗進行選取,也可視需求彈性修改。
搜尋模式在此情境中選擇「整個指定來源」,代表 RPA 會直接讀取整個檔案,如想局部搜尋的話,也可使用僅限特定子區域,藉由 X, Y 的方式框出;又或是透過影像辨識的方式讓系統知道這次的目標抓取區域為何。
因此次圖檔有包括繁體中文的內容,故選擇「中文(繁體)」的選項即可,其餘兩個欄位不需調整。
此處比較須注意的是假設我們要採用的是英文內容,那就要注意 Windows 電腦的介面是否已安裝英文的語言,可以進到一般->時間與語言->語言與地區,確認使用的語言使否包含英文(美國),如無,建議可透過「新增語言」來確保此功能可順利使用。
接著我們就能讓流程跑一下測試,測試後可檢視右邊流程變數所生成的內容,可發現發票文字已被截取至變數中,其中有部分文字缺漏,不過最重要的發票號碼的確有成功抓取。
參考功能畫面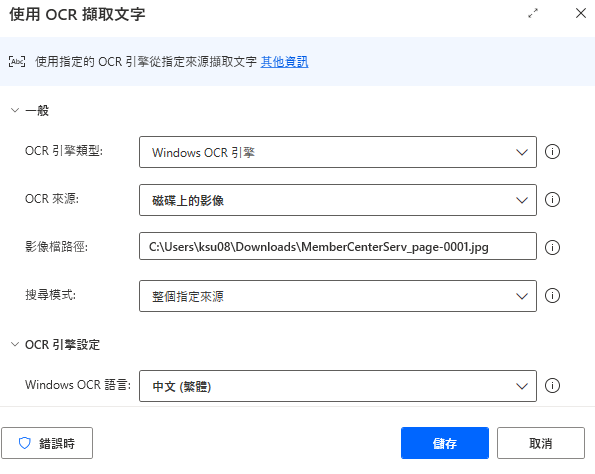
Power Automate Desktop 提供了多樣化的工具來處理來自 PDF 和影像的文本資料。針對可選擇文字的 PDF,PDF 擷取文字功能提供了高效的解決方案;而對於無法選取的文字,OCR 功能則提供了強大的支援。根據具體的文檔格式與語言情境,Windows OCR 與 Tesseract OCR 兩種引擎各有優勢,使用者可以根據需求靈活選擇。
無論是處理中文發票還是多語言的報表,適當運用這些工具將大大提升自動化流程的效率。希望本篇文章能夠幫助你了解這些功能的差異與應用,讓你的自動化流程更加順暢!


 iThome鐵人賽
iThome鐵人賽