因為對Django蠻有興趣的,同時又很好奇上億級別的應用是怎麼使用Django的
在知道Instagram也是用Django開發後,就蠻有興趣了他們是怎麼做系統架構與優化的
而他們團隊在2011-2019年之間在Medium上有一系列的技術文章
我會針對一些我感興趣的主題去做導讀與添加一點點個人觀點
而今天來看一篇2012年,Instagram團隊寫有關PostreSQL的技術文章:
Ig開發團隊使用Django(基於python的Web框架)做開發,並且使用PostgreSQL做為資料庫。在2012年的Instagram每秒就需要處理25張照片上傳跟90個讚(2013年就成長到每秒破萬讚數請求,現在更不敢想)
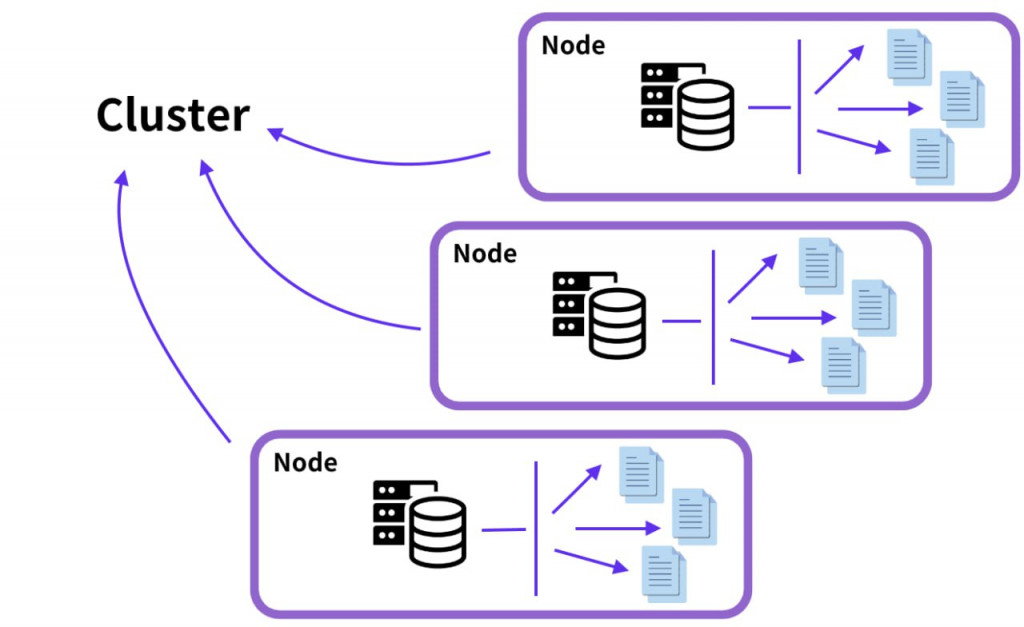
面對這樣大量的資料不可能使用單一資料庫做儲存,所以需要將資料進行Sharding(底下簡稱分片)
但這樣做的同時也代表:
Ig開發團隊有考慮過不同的NoSQL解決方案,像針對上述情境Elasticsearch就能很好的處理,但最終還是決定在PostgreSQL上繼續最為主力開發
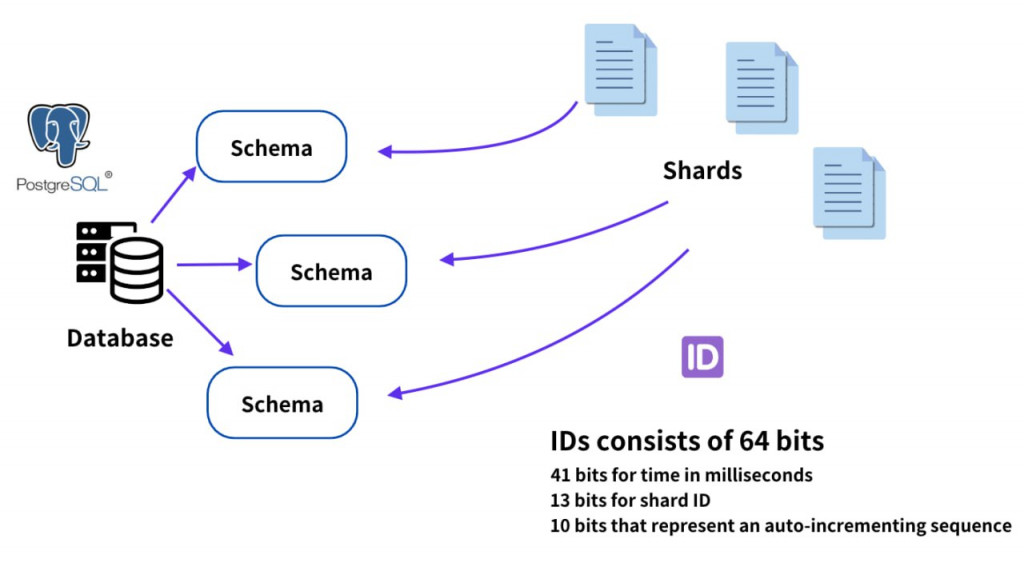
PostgreSQL具備Schema這個特性(不是SQL schema),通常在單一DB層級中,表名是唯一的
但是PostgreSQL可以在單一DB層級中建立多個Schema,每個Schema內則是可以建立表格。這就代表不同的Schema內可以有同表名的表格。在這個架構中,每一個Schema就相當於一個Shard
例如有一個表格名稱為photo,負責儲存用戶上傳的照片。大量的資料被分割成不同片段(Shard)
這些分片被存到不同的Schema中,並且都是存在名為photo的表格中
這樣的設計架構在處理多租戶模式時相當好用,因為資料隔離特性的緣故
而在這個架構中,就不需要建立多個DB,而是在單一DB中就能儲存多個分片
但是這時候回到開頭說的第一個問題:ID的問題
在多方匯入資料的情境下,需要有一個方式能夠維持資料的排序,又要不依賴太多額外套件(這是Ig開發團隊的核心宗旨之一),並且為了兼容性ID最好是64位元
最後Ig開發團隊選擇使用PL/PGSQL、Postgres 的內部程式語言以及 Postgres 現有的自動增量功能來進行實現,同時制定ID組成:
41 位用於毫秒級時間戳
13 位用於邏輯分片 ID
10 位用於自增序列號(每毫秒每分片最多 1024 個 ID)
這樣的作法有以下特點:
當然這是相當簡化的版本,實際上還要考慮許多問題:
但是可能當下Ig團隊考慮到其他需求,最終還是決定使用PostgreSQL最為主力,Elasticsearch等NoSQL為輔,而這樣的決定完全不影響他們家產品日後的成長與成功
原文連結:https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c
 blank
blank

 iThome鐵人賽
iThome鐵人賽