
HI!大家好,我是 Shammi 😊
昨天完成了 Embedding 模型的技術選擇,並決定最適合專案的模型作為我的機器人「大腦核心🧠」。今天要使用這個核心,將處理好的 SDGs 文字內容,轉化成 AI 能理解的語言—>向量。
這一步是 RAG 架構中,最關鍵的實作環節之一。此階段將會把 SDGs 知識庫,從一堆冰冷的文字,變成一個可以被 AI 機器人快速、精準檢索的「記憶中樞」。
電腦無法理解文字的語義和上下文。但透過 Embedding 技術,我將每一段文字(例如,SDGs 知識庫中的一個段落)轉換成一串獨特的數字向量。
這串數字向量在數學空間中,代表了這段文字的語義。
👉 語義相近的文字,它們的向量會非常靠近。
👉 語義不相關的文字,它們的向量會離得很遠。
這樣一來,當使用者提問時,我只需將問題也轉成向量,然後在向量空間中,找到距離最近的文字向量,就能快速地找出最相關的答案!
在正式開始向量化之前,需要先取得使用 Google 模型服務的通行證:API 金鑰。
請打開你的瀏覽器,前往 Google AI Studio 網站:
https://aistudio.google.com/app/apikey
登入 Google 帳號後,點擊「Create API key」按鈕,你的一串專屬金鑰就會生成。申請完後請在頁面中找到「API key」並點擊「Copy」,會是一串英數字的組合請將它複製並妥善保存,這將是你接下來使用模組的通行證。
text-embedding-004 進行向量化接著,我會使用 google-generativeai 套件,來實作將文字區塊(Day 5 從 PDF 提取的內容)轉換成向量的過程。
請確保 Colab 環境已經安裝好 google-generativeai。接下來,需先設定 Google API 金鑰。
強烈建議使用 Colab 的「金鑰管理員 (Secrets)」功能,這能確保金鑰不會被公開。
資安意識對於開發人員是非常重要的一環哦!
接著按照以下步驟操作:
Add new secret,Name 欄位中輸入 GOOGLE_API_KEY。Value 欄位中貼上金鑰,並勾選 Notebook access。參考畫面: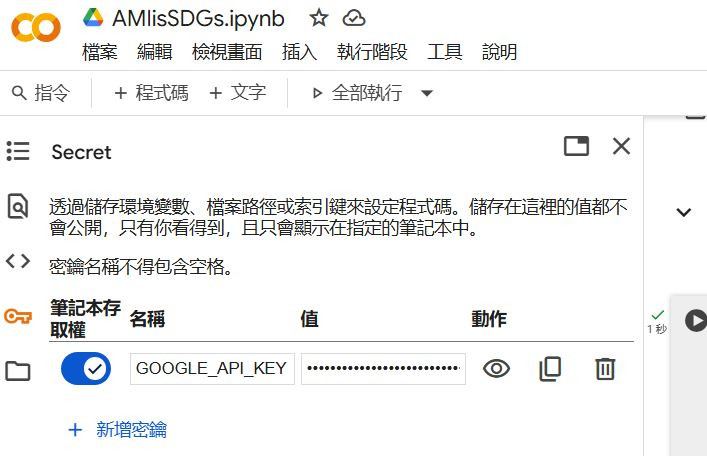
接著,請新增程式區塊,將以下程式碼新增上去並執行,就可以在程式碼中安全地呼叫API:
import google.generativeai as genai
from google.colab import userdata
#從金鑰管理員中取得金鑰
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)
再這裡我直接整合 Day 1-5 的流程,載入 PDF 並將其切分為文字區塊,以便後續向量化。(新增程式區塊)
!pip install pypdf
from pypdf import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
#請替換你在DAY5所上傳的檔案名稱並確認一致性!
pdf_path = "17sdgs.pdf"
reader = PdfReader(pdf_path)
pdf_text = ""
for page in reader.pages:
pdf_text += page.extract_text()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
stored_chunks = text_splitter.split_text(pdf_text)
print(f"成功將 PDF 內容切分為 {len(stored_chunks)} 個區塊。")
(新增程式區塊)將 stored_chunks 列表中的所有文字區塊進行向量化,並將結果儲存起來。
import numpy as np
def get_embedding(text, task_type="RETRIEVAL_DOCUMENT"):
response = genai.embed_content(
model="models/text-embedding-004",
content=text,
task_type=task_type
)
return np.array(response['embedding']).astype('float32')
all_embeddings = [get_embedding(chunk) for chunk in stored_chunks]
print(f"總共生成了 {len(all_embeddings)} 個向量。")
參考結果:
今天完成核心的步驟之一:將 SDGs 的知識庫文字,轉化成了 AI 能理解的向量。
這些向量,就像是 SDGs 知識的「指紋」,每一個指紋都獨一無二地代表了一段文字的語義。有了這些指紋,明天就可以開始打造一個高效的「指紋辨識系統」——也就是機器人的向量資料庫,讓機器人能夠在海量知識中精準搜尋!

 iThome鐵人賽
iThome鐵人賽