
呼~昨天成功將所有 SDGs 知識的向量,存入了一個高效的 FAISS 向量索引中。這個索引,就是我的 AI 機器人的「記憶中樞」。
接下來,將要實作 RAG 架構中最有趣的部分:檢索機制(Retrieval)。我會在此階段設計一個功能,讓機器人能夠根據使用者的問題,從這個向量索引中,快速且精準地找出最相關的 SDGs 內容。這一步,就是賦予我的 AI 聊天機器人「查閱能力」的關鍵。
整個檢索過程其實非常直觀:
1️⃣ 使用者提問:例如,使用者問「氣候變遷有什麼應對措施?」
2️⃣ 問題向量化:使用與知識庫相同的 Embedding 模型(text-embedding-004),將這個問題轉換成一個向量。
3️⃣ 向量搜尋:接著,我將這個問題向量,送進 FAISS 索引中進行搜尋。FAISS 會找出與問題向量最接近(即語義最相似)的 k 個知識向量。
4️⃣ 取出原始內容:找到最相似的向量後,我就能透過這些向量的索引,取出對應的原始文字內容。
這些被找出來的文字內容,就是機器人接下來將會參考的「參考資料」。
接下來,我將使用 FAISS 來實作這個檢索功能。
首先,需要載入必要的套件,並讀取我在 Day 8 儲存的 FAISS 索引。
import faiss
import numpy as np
import google.generativeai as genai
from google.colab import userdata
#載入金鑰
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)
#載入儲存的FAISS索引檔案
index = faiss.read_index("sdgs_faiss.index")
接下來將定義一個函式,它將負責整個檢索流程:將使用者問題向量化,然後在 FAISS 索引中進行搜尋。
def get_embedding(text, task_type="RETRIEVAL_QUERY"):
"""
使用 text-embedding-004 進行向量化。
注意:搜尋問題的 task_type 應設為 "RETRIEVAL_QUERY"。
"""
response = genai.embed_content(
model="models/text-embedding-004",
content=text,
task_type=task_type
)
return np.array(response['embedding']).astype('float32').reshape(1, -1)
def search_faiss_index(query, k=3):
"""
將查詢問題轉換為向量,並在 FAISS 索引中搜尋最相似的 k 個向量。
"""
query_vector = get_embedding(query)
distances, indices = index.search(query_vector, k)
return distances, indices
indices 傳回的是向量在我原始向量列表中的位置。透過這個索引,找到它對應的原始文字內容。
#執行搜尋範例
query = "永續利用海洋資源的方法有哪些?"
distances, indices = search_faiss_index(query, k=3)
#根據搜尋結果的索引,找出對應的原始文字
retrieved_chunks = [stored_chunks[i] for i in indices[0]]
print("從知識庫中檢索出的最相關內容:")
for chunk in retrieved_chunks:
print("---")
print(chunk)
參考結果: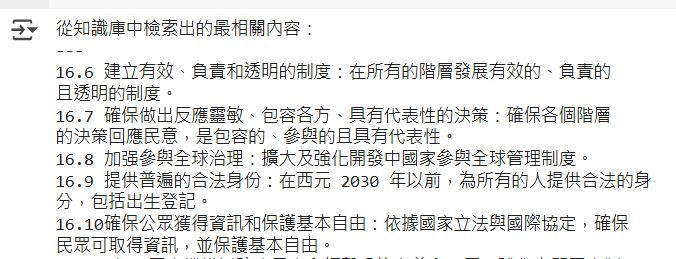
注意:進行「全部執行」的功能時,要記得重新上傳PDF檔案哦。
完成此階段的時候,執行最後的步驟會發現內容很亂,因為現在機器人還沒有「說人話」的能力,但也完成了 RAG 架構中的重要「檢索」機制,這樣一來,我的 AI 對話機器人現在已經具備了「查閱」知識庫的能力囉!
這些被檢索出來的內容,將會在明天的步驟中,作為「上下文(Context)」傳遞給大型語言模型(LLM),讓它能夠根據這些參考資料,生成一個精準、可靠的答案。這將是專案最重要的一步,也是 RAG 架構最獨特的核心所在!

 iThome鐵人賽
iThome鐵人賽