Hi大家好,
這是我參加 iT 邦幫忙鐵人賽的第 1 次挑戰,這次的主題聚焦在結合 Python 爬蟲、RAG(檢索增強生成)與 AI,打造一套 PTT 文章智慧問答系統。在過程中,我會依照每天進度上傳程式碼到 GitHub ,方便大家參考學習。也歡迎留言或來信討論,我的信箱是 gerryearth@gmail.com。
今天我們將擴充 API 功能,讓系統不只能列出文章清單,還能查詢單篇文章內容,並提供基本統計資訊,為後續智慧問答奠定資料基礎。
在前一天,我們已建立 /api/posts/ 的列表查詢 API。今天我們要擴充:
/api/posts/<id>/:查詢特定文章內容/api/statistics/:回傳整體統計資訊首先請在 article/urls.py 增加:
urlpatterns = [
...
path('posts/<int:pk>/', views.ArticleDetailView.as_view(), name='article-detail'),
]
接下來就要寫 article/views.py 的 ArticleDetailView 的內容:
class ArticleDetailView(APIView):
@extend_schema(
description="根據文章 ID 取得特定文章的詳細內容。",
responses={200: ArticleSerializer(),
404: OpenApiResponse(response={"type": "object", "properties": {"error": {"type": "string"}}})}
)
def get(self, request, pk):
if pk <= 0:
Log.objects.create(level='ERROR', category='user-posts_id', message='文章ID須為正數', )
return Response({"error": "文章ID須為正數"}, status=status.HTTP_404_NOT_FOUND)
try:
articles = Article.objects.get(id=pk)
except Article.DoesNotExist:
Log.objects.create(level='ERROR', category='user-posts_id', message='找不到文章,請輸入正確文章ID', traceback=traceback.format_exc())
return Response({"error": "找不到文章,請輸入正確文章ID"}, status=status.HTTP_404_NOT_FOUND)
return Response(ArticleSerializer(articles).data, status=status.HTTP_200_OK)
有了前面建立 API 的經驗後,這裡應該就簡單很多了!
比較不一樣的是 get(self, request, pk) 可以接收 URL 中的文章 ID(pk),我們就可以用這個 pk 取得對應文章。
我們再來新增一個新的 API 端點:/api/statistics/
urlpatterns = [
...
path('statistics/', views.ArticleStatisticsView.as_view(), name='article-statistics'),
]
比較敏銳的人可能發現這個 API 跟昨天的 API 一樣都要進行篩選,因此我們可以把篩選的部分寫成一個 function:
def articles_filter(article_list_request_serializer):
articles = Article.objects.all()
author_name = article_list_request_serializer.validated_data.get("author_name")
board_name = article_list_request_serializer.validated_data.get("board_name")
start_date = article_list_request_serializer.validated_data.get("start_date")
end_date = article_list_request_serializer.validated_data.get("end_date")
if author_name:
articles = articles.filter(author__name=author_name)
if board_name:
articles = articles.filter(board__name=board_name)
start_datetime = datetime.combine(start_date, time.min) if start_date else None
end_datetime = datetime.combine(end_date, time.max) if end_date else None
if start_datetime and end_datetime:
articles = articles.filter(post_time__range=[start_datetime, end_datetime])
elif start_datetime:
articles = articles.filter(post_time__gte=start_datetime)
elif end_datetime:
articles = articles.filter(post_time__lte=end_datetime)
return articles
昨天的 API 就可以寫得更精簡了:
class ArticleListView(APIView):
...
def get(self, request):
article_list_request_serializer = ArticleListRequestSerializer(data=request.query_params)
if not article_list_request_serializer.is_valid():
Log.objects.create(level='ERROR', category='user-posts', message='查詢參數不合法',
traceback=traceback.format_exc())
return Response(article_list_request_serializer.errors, status=status.HTTP_400_BAD_REQUEST)
articles = articles_filter(article_list_request_serializer)
paginator = LimitOffsetPagination()
paginator.default_limit = 50
paginated_queryset = paginator.paginate_queryset(articles.order_by('id'), request)
serializer = ArticleSerializer(paginated_queryset, many=True)
return paginator.get_paginated_response(serializer.data)
views.py 新增 ArticleStatisticsView:我們一樣使用 articles_filter 進行篩選,並統計數量就可以完成了!
class ArticleStatisticsView(APIView):
@extend_schema(
description="取得文章統計資訊,支援時間範圍、作者名稱和版面過濾",
parameters=[
OpenApiParameter("author_name", str, OpenApiParameter.QUERY, description="篩選特定發文者的文章"),
OpenApiParameter("board_name", str, OpenApiParameter.QUERY, description="篩選特定版面的文章"),
OpenApiParameter("start_date", str, OpenApiParameter.QUERY, description="篩選起始日期 (YYYY-MM-DD)", ),
OpenApiParameter("end_date", str, OpenApiParameter.QUERY, description="篩選結束日期 (YYYY-MM-DD)", ),
],
responses={
200: OpenApiResponse(response={"type": "object", "properties": {"total_articles": {"type": "integer"}}}),
400: OpenApiResponse(response={"type": "object", "properties": {"error": {"type": "string"}}}),
}
)
def get(self, request):
article_list_request_serializer = ArticleListRequestSerializer(data=request.query_params)
if not article_list_request_serializer.is_valid():
Log.objects.create(level='ERROR', category='user-posts', message='查詢參數不合法', )
return Response(article_list_request_serializer.errors, status=status.HTTP_400_BAD_REQUEST)
articles = articles_filter(article_list_request_serializer)
total_articles = articles.count()
return Response({"total_articles": total_articles})
全都準備好了就來測試 API 吧!
可以發現多了兩個我們新建立的 API :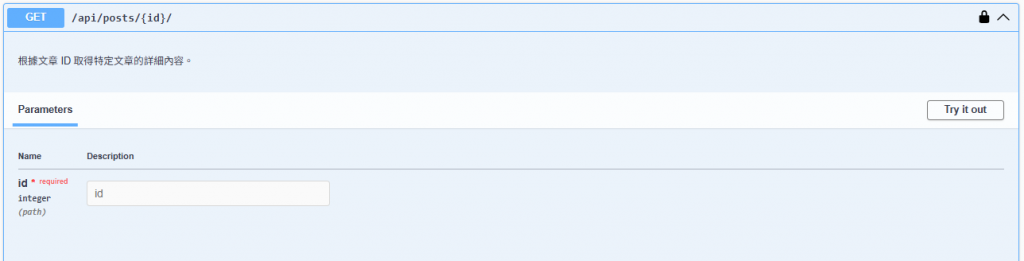
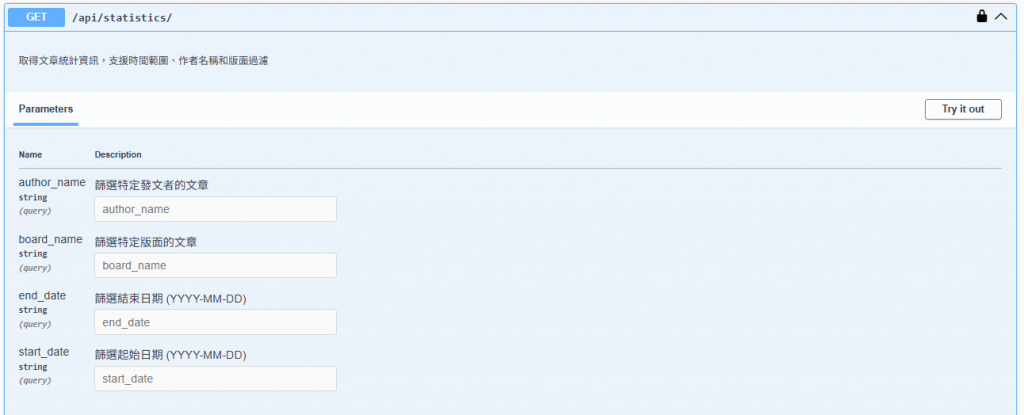
請大家自由測試。
明天【Day16】認識 RAG 與 向量資料庫 - 整合 RAG 與 Pinecone 的運作流程
我們將從概念出發,帶你了解什麼是 RAG、向量資料庫,以及 Pinecone 在本專案中的角色!


 iThome鐵人賽
iThome鐵人賽