今天我們要來為這個AI Agent接上工具,首先一定要接上的就是notion的工具,我想要讓這個助理可以查看和編輯我的待辦清單和知識庫,所以我新增了四個工具,分別是「get menu」「get TODO」「get page blocks」「add TODOs」。
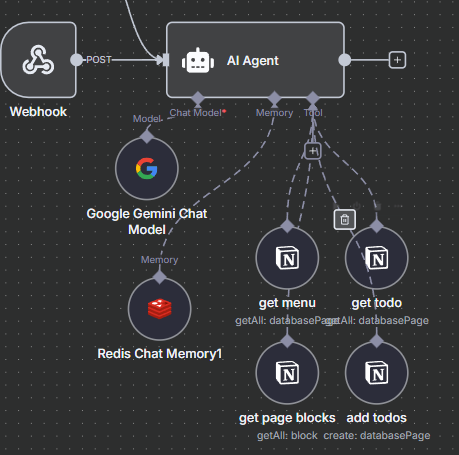
在設定好這些工具後,就可以接上他們,並且進行測試:
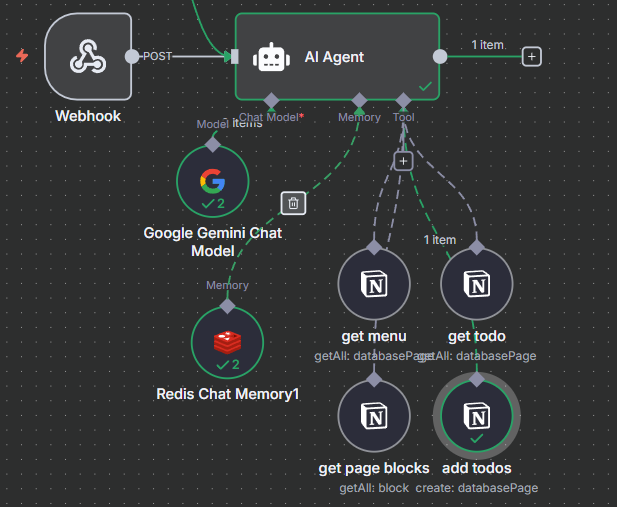

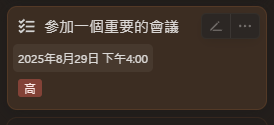
可以看到我跟助理對話之後,他成功的調用了add TODOs的工具,並且在我的notion中也出現了這項待辦事項,這就代表我們的工具是沒問題的,接下來我想要再新增一些Google的服務,讓這個助理可以做更多事情:
首先我想要讓這個模型可以有文生圖和圖生圖的能力,剛好google的gemini就有提供這個功能
(影片參考:https://youtu.be/Z-q-EuSaI64?si=pzuHaaKxbmiVbGVb)
我們到google的 google ai for developer(https://ai.google.dev/gemini-api/docs/image-generation?hl=zh-tw#rest)
複製這段程式碼:
curl -s -X POST
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}]
}'
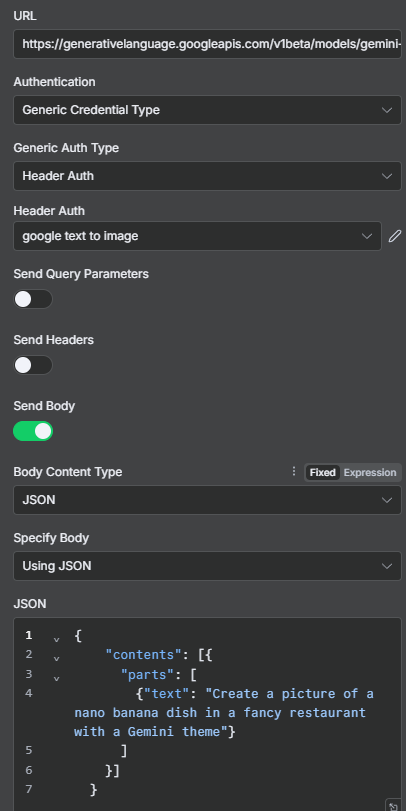
並且在n8n中使用http request將這個程式碼的Header跟Body輸入(先另外開啟一個工作流):
接著按下執行,就可以看到他回傳了以Base64編碼格式的一大串文字,我們利用n8n內建的轉換節點來將Base64轉換成圖檔:
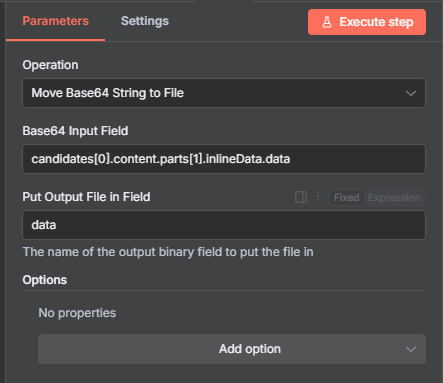
接著就能看到一張圖片出現了:

這麼一來我們就有了可以讓Agent生成圖片的功能了,今天的實作內容也是順利的完成了。
(後來發現其實現在的n8n中,tools節點就有用gemini生成圖片等功能,因此明天的流程將不會這麼複雜)
今天我們為AI Agent新增了notion的存取權限和生成圖片的功能,明天我們將會繼續為它新增更多功能,以及新增多模態的輸入方式,讓這個助理可以讀得懂語音、文字和圖像。


 iThome鐵人賽
iThome鐵人賽