在前幾天,我已經體驗過用GPT-2生成文字,也理解了大語言模型(LLM)的核心原理和Transformer架構。但如果仔細想,模型到底是怎麼讀懂我們輸入的文字呢?
這就要提到一個關鍵概念——Token。
Token 是什麼?
LLM 並不是直接看「字」或「詞」,而是先把文字轉換成模型能理解的最小單位:Token。
在英文裡,一個單字、甚至單字的一部分,都可能是一個Token。
在中文裡,常見的做法是一個字算一個Token。
換句話說,Token 可以理解成模型用來處理語言的積木。
為什麼要切Token?
如果我們把一句話「我愛AI」丟給模型,模型不會直接處理中文字,而是要先把它拆解成Token ID,然後再進行後續的運算。
這樣做有幾個好處:
實際操作
用Hugging Face提供的tokenizer來看看: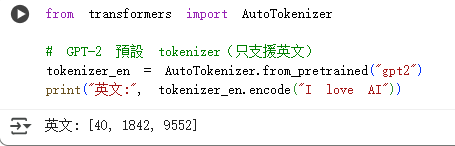
可以發現
I → 40
love → 1842
AI → 9552
模型並不是直接看到 "I love AI",而是看到一串數字[40, 1842, 9552]。
所以其實Token也沒那麼神祕啦,就是模型在看文字前要先把它切小塊,再用數字來代表。換句話說,我們腦袋裡想的是「I love AI」,但模型眼裡看到的就是[40, 1842, 9552]這串數字。想通這件事之後,我就覺得LLM的運作方式更好理解了。

