在微服務架構的世界裡,服務的獨立性與自治性是關鍵原則。服務要能夠獨立開發、部署、擴展與維護,而背後的資料庫設計則是影響這些特性的關鍵因素。微服務與傳統單體應用最大的不同之一,就在於「資料層」的處理方式。
本文將透過兩種主要的資料庫設計模式 —— Shared Database 與 Database per Service —— 來深入探討微服務架構下資料層的抉擇、挑戰與實務設計方式。
在傳統的單體式應用中,所有模組共享同一個資料庫,透過關聯式模型與 SQL Join 便能完成複雜查詢與交易邏輯。但在微服務架構中,以下幾個挑戰讓資料庫設計變得格外關鍵:
服務自治性
每個服務必須能夠獨立開發、測試、部署與擴展,資料庫若高度耦合,將破壞這種自主性。
跨服務交易
許多業務交易會跨越多個服務,例如「下單(Place Order)」需要同時檢查客戶的信用額度與新增訂單。
跨服務查詢
有些報表與查詢需求,會需要同時讀取多個服務的資料,例如「查詢特定區域的客戶及其近期訂單」。
多樣化儲存需求
有些服務適合使用關聯式資料庫,有些則需要文件型(MongoDB)、圖形資料庫(Neo4j)、搜尋引擎(Elasticsearch)。
資料一致性
在分散式架構下,如何確保跨服務資料的正確性與一致性,是設計的重大挑戰。
在這樣的前提下,兩種不同的模式出現了:Shared Database 與 Database per Service。
Shared Database 是指 多個微服務共用同一個資料庫實例,各服務可以自由存取彼此的資料表,並利用 ACID 交易來確保一致性。
這樣處理的好處是:
雖然,共享資料庫可以有上述的好處,但是在「微服務」的應用中卻經常將這個模式視為「反模式」。
主要被反對的原因如下:
開發耦合(Development-time Coupling)
不同團隊需要協調資料庫 Schema 的修改。例如 CustomerService 與 OrderService 都用到 CUSTOMER 表,任何修改都需要溝通。
執行耦合(Runtime Coupling)
若 CustomerService 執行一個長交易鎖住 ORDER 表,OrderService 也會受影響,降低可用性。
限制彈性
所有服務必須使用同一種資料庫技術,難以因應不同業務需求選擇最佳的儲存方式。
可擴展性不足
當資料庫規模成長,單一資料庫可能成為系統瓶頸。
在傳統保險系統或金融系統,常見透過 Shared Database 管理所有交易與帳務 (核心系統)。其原因在於必須確保交易一致性,並且既有系統歷史悠久,早期並未考量服務自治的需求。
Database per Service 指的是 每個微服務擁有自己的專屬資料庫,其他服務不可直接存取,只能透過該服務的 API 存取資料。
與共享資料庫相反,這樣的設計具備下列優勢:
低耦合、高自治性
每個服務對自己的資料庫負責,Schema 修改只影響自身,不需跨團隊協調。
技術多樣性
每個服務可依需求選擇最適合的資料庫。例如:
可擴展性
資料庫可依服務特性獨立水平擴展或分片
當然,採用 Database per service 也不是只有好處,當然有其缺點:
跨服務交易實作困難
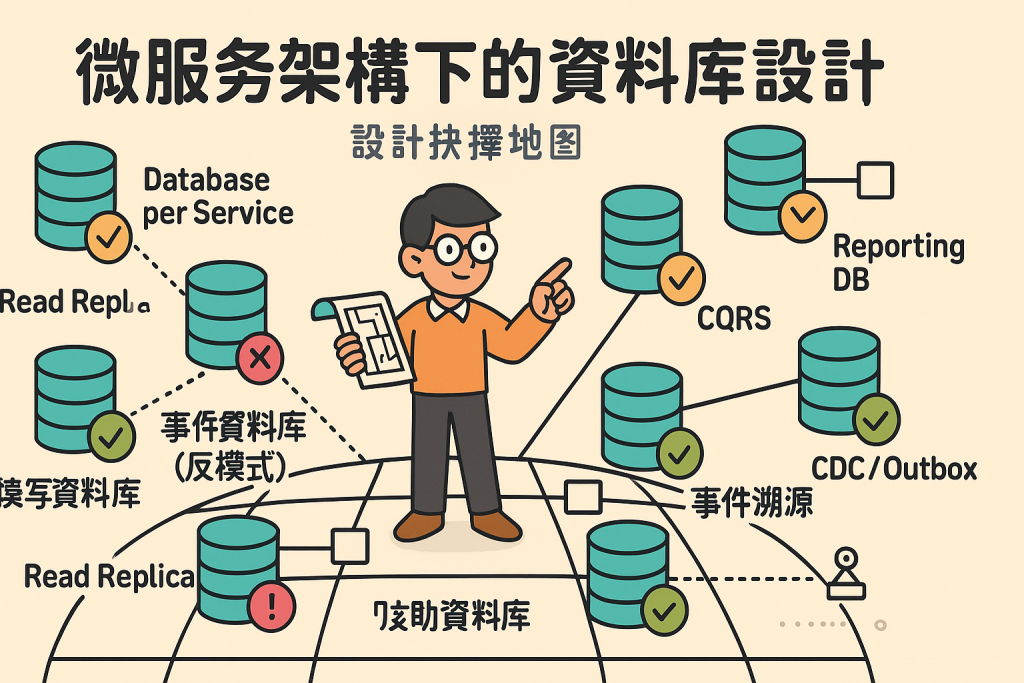
傳統的 ACID 跨庫交易不可行,需要透過 Saga Pattern 或事件驅動設計來確保「最終一致性」。
跨服務查詢困難
無法使用 SQL Join 直接跨庫查詢,需採取其他模式(如 API Composition 或 CQRS)。
維運複雜度高
需管理多種資料庫技術,包含備份、監控、容災。
但是,Database per service 很耗資料庫的商業授權,所以我們可以試著用底下幾個方式來逼近:
根據文獻的檢索,我們可以發現有許多大型的電商系統,如 Amazon、Netflix,廣泛使用 Database per Service。每個服務有獨立的資料存取權限,避免耦合,並能快速演進。
當然,如果流量瓶頸沒有像這些電商那麼大,則套用的方式本來就可以斟酌,找出一個最適合的方案。
在 Microservice Architecture Patterns 的指引當中,為了解決跨服務交易與查詢的問題,常見以下幾種設計:
| 維度 | Shared Database | Database per service |
|---|---|---|
| 服務自治 | 差,耦合度高 | 佳,完全自治 |
| 交易一致性 | ACID,簡單 | Saga/Eventual Consistency,複雜 |
| 查詢能力 | 強,SQL Join | 弱,需 API Composition 或 CQRS |
| 技術選型 | 受限於單一資料庫 | 可多樣化 |
| 開發維運 | 簡單,但耦合風險高 | 複雜,但獨立性強 |
| 擴展性 | 資料庫容易成瓶頸 | 可依服務獨立擴展 |
| 常見應用 | 傳統金融、政府系統 | 電商、SaaS、大型網路服務 |
在微服務架構中,資料庫不再只是「技術選型」的問題,而是架構設計的核心議題。
Shared Database 提供快速開發與簡單一致性,但犧牲了自治與演進性;Database per Service 則提供高度彈性與服務獨立,但帶來更高的設計與運維挑戰。
最終的抉擇,應取決於系統的特性、業務的複雜度,以及團隊是否具備管理分散式資料的一致性經驗。對於長期發展來說,Database per Service 更符合微服務的精神,但也必須搭配 Saga、CQRS、API Composition 等設計模式,才能真正落地。


 iThome鐵人賽
iThome鐵人賽