
在微服務架構(Microservice Architecture)中,系統由許多小而獨立的服務組成,這些服務透過 API、事件、訊息佇列彼此交互合作。這種設計帶來了彈性與擴展性,但也讓問題診斷變得更加困難:一個使用者請求往往會穿越數十個服務,任何一個節點的延遲、錯誤、或資源瓶頸都可能影響最終體驗。
因此,「可觀測性(Observability)」便成為微服務實施中的關鍵指標。它不僅是「監控(Monitoring)」,而是提供足夠的資訊,讓開發者能理解應用的內部狀態、快速找出根因、並提升系統可靠性。
如何理解一個分散式應用的行為,並在發生問題時能夠快速定位與解決?
這件事情的困難度在於:
在微服務的架構中,每個服務都會輸出日誌,若僅存在於本地,將難以跨服務關聯問題。所以,為了排除這個問題,我們需要將日誌集中納管並且提供搜尋與分析的功能,於是有了 lasticsearch + Logstash + Kibana 的技術元件。
通常,我們會透過 Fluentd / Filebeat 作為 Log 收集器再透過 Elasticsearch 提供儲存與搜尋的能力,最後再由 Kiabana 做日誌探索的使用者介面或是拉出特定的 Dashboard。
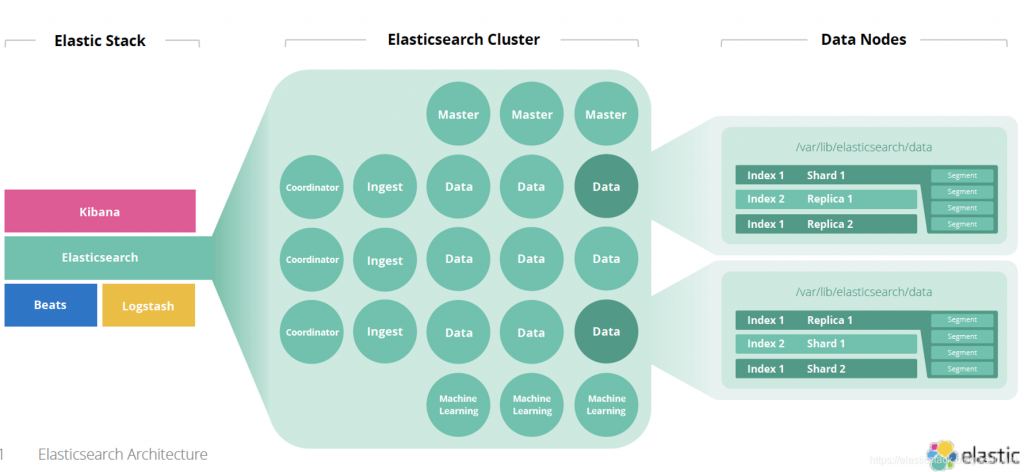
當然,還有其他類似的工具,我自己也蠻常使用跟 Elasticsearch 鬧分家後的 OpenSearch 版本。
在使用 Elasticsearch 的時候,需要注意的是「儲存與維護成本高」而且需要時時緊盯其索引與歸檔策略,做出最佳化的配置模式。
監控系統不僅需要日誌,還需要數據化指標。日誌是一種 Raw Data 的概念,而指標則是針對這些資訊淬鍊出一個可量化的數據,讓我們可以理解系統運作的狀況。
因此,為了完成這件事情,開發人員必須在服務程式碼中加入相關資訊的蒐集工作,再透過 Metric 平台來做整理 (通常可能是 Kiabana 或是 Grafana 中拉出來的 Dashboard)。
透過這個實踐,我們可以提供數字化趨勢分析,可設警示(如延遲 > 500ms 觸發告警)。但也隨著我們要滿足這些非功能性的需求導致這些蒐集資訊的程式與商業邏輯之間有很高的機率產生耦合。
除了技術指標,企業常需要追蹤「誰在什麼時間做了什麼事」,基本上我們會將這些資訊儲存在資料庫中,記錄使用者操作,例如登入、申請、交易等。
這樣的情境經常發生在「客服人員」操作(客服可回溯操作歷程)或是法律遵循需求(銀行、保險業的稽核追蹤)。
曾經,我們也討論過稽核日誌是否也就蒐集到 ELK 中去儲存,但在實際理解 Elasticsearch 的運作原理後會發現,該產品並不適合這種需要長期保存的合規性應用場景,最終會比較推薦採用資料庫 (RDB or NoSQL)會比較恰當一些。
單一請求可能跨越多個服務,傳統監控無法解析各步驟耗時。這時候,可能就需要為每個外部請求產生唯一 Request ID,並傳遞到各服務,將完整執行鏈路紀錄下來。
常見的實作程序:
透過這樣的模式,我們可以完整掌握請求鏈路,快速定位延遲來源。但是,開發者需要為這個部分預做鋪陳,且需要額外的基礎設施才能完成相關工作 (例如:Jaeger)。
系統常會拋出例外(Exception),若只出現在 Log,容易被忽略。為了能凸顯這些例外訊息,可以將例外訊息集中處理並進行分類、統計作為系統問題排查與優化的參考依據。通常,Exception Tracking 會搭配「警示」來實現,可以協助我們分析系統的錯誤率。
但,要注意的一點是,如果出現大量的警示,可能會導致維運人員通知疲勞的狀況。
你有遇過有些服務「還在跑」但已無法提供功能,例如 DB 連線耗盡,所以為了維持分散式系統的運作可靠度,有一個手法就是實作 /health API,回傳服務狀態,供 Load Balancer 與 Service Registry 使用。
通常我們會用 Spring Boot Actuator 來協助實作,這是一個簡單又快速完成 Health API 的方法,但是要注意不是直接回傳 HTTP 200 OK,而是要依據自己相依性套件確認自己是否處於可運作狀態。因為要檢查的東西與內容比較多,Health API 也不會是馬上回應的即時狀態,因此難免存在「瞬間故障」的風險。
看過「獨角獸專案」一書的人對於故事主人翁面對系統不穩定所採取的其中一個手段就是蒐集「部署與變更紀錄」,因為當問題發生時,往往與最近的部署有直接關聯。所以,為了方便於問題的追查「部署與變更記錄」同樣屬於可觀測性的一部分。
建議的做法:
| 模式 | 工具 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|
| Log Aggregation | ELK, OpenSearch | 搜尋與視覺化強大 | 成本高 | 問題追蹤 |
| Application Metrics | Prometheus | 數據化分析、警示 | 程式碼耦合 | 系統健康監控 |
| Audit Logging | DB 寫入 | Event Sourcing | 符合法規、可回溯 | 業務耦合 |
| Distributed Tracing | Zipkin, Jaeger | 快速定位瓶頸 | 數據量龐大 | 高併發系統 |
| Exception Tracking | Sentry | 錯誤通知即時 | 容易訊息過量 | 開發維運 |
| Health Check API | Spring Boot Actuator, K8s Probe | 輕量即時檢查 | 偵測不完全 | 負載均衡、服務發現 |
在本篇中,我們針對 微服務可觀測性六大核心模式 進行了介紹,這些模式提供了從 基礎日誌收集到分散式鏈路追蹤 的完整工具箱。它們不僅幫助團隊在故障發生時快速排查,更能建立起穩定、可靠的正式環境。在下一章節,我將透過 Pattern Language 的寫法試著描述「可觀測性」相關的模式如何被實現。


 iThome鐵人賽
iThome鐵人賽