目前每套一個效果就回傳一個新的 Vec<u8>,三個效果就配三次、複製三次,跑 4K 圖片時 GC 和 allocator 會太多。今天不動前端呼叫方式,把 Rust 端的管線改成ping-pong buffer:整條管線一開始只準備兩塊一樣大的位元組陣列,第一個效果把結果寫到 B,第二個效果拿 B 當輸入寫回 A,如此來回交換,最後只還你其中一塊。好處是整趟只配置一次目的緩衝、複製一次來源,之後每個效果都是原地覆蓋另一塊,分配次數從 N 變 1。
先把每個效果多寫一個「into」版本,吃來源 slice、寫目的 slice,不分配、不回傳;管線入口把 input 先拷到 A,B 開成全零的同尺寸緩衝,然後照 ops 一步步把結果寫到另一側,下一步再交換。最後決定哪一個是最新結果,複製成 Vec<u8> 回 JS(這樣只做一次複製)。
下方是把 Day 7 的幾個效果改成 into 版本,加上一個新的 apply_pipeline_fast。原本的 apply_pipeline 你可以保留不動,兩個版本一起提供,方便對照。
#[derive(Deserialize)]
#[serde(tag = "kind")]
enum Op {
#[serde(rename = "grayscale")]
Grayscale,
#[serde(rename = "bc")]
BrightnessContrast { b: f64, c: f64 },
#[serde(rename = "blur")]
Blur { r: u32 },
#[serde(rename = "conv3x3")]
Conv3x3 { k: [f32; 9] },
}
#[wasm_bindgen]
pub fn apply_pipeline(input: &[u8], w: u32, h: u32, ops: &JsValue) -> Result<Vec<u8>, JsValue> {
let expected = (w as usize) * (h as usize) * 4;
if input.len() != expected {
return Err(JsValue::from_str("input length mismatch"));
}
let ops: Vec<Op> = swb::from_value(ops.clone())
.map_err(|e| JsValue::from_str(&format!("bad ops: {e}")))?;
let mut buf = input.to_vec();
for op in ops {
buf = match op {
Op::Grayscale => grayscale(&buf, w, h),
Op::BrightnessContrast { b, c } => brightness_contrast(&buf, w, h, b, c),
Op::Blur { r } => box_blur_rgba(&buf, w, h, r),
Op::Conv3x3 { k } => convolve3x3(&buf, w, h, &k),
};
}
Ok(buf)
}
fn grayscale_into(src: &[u8], dst: &mut [u8]) {
let mut i = 0usize;
while i < src.len() {
let (r, g, b, a) = (src[i], src[i + 1], src[i + 2], src[i + 3]);
let y = ((77u16 * r as u16 + 150 * g as u16 + 29 * b as u16) >> 8) as u8;
dst[i] = y; dst[i + 1] = y; dst[i + 2] = y; dst[i + 3] = a;
i += 4;
}
}
fn brightness_contrast_into(src: &[u8], dst: &mut [u8], brightness: f64, contrast: f64) {
let b = brightness.clamp(-255.0, 255.0);
let c = contrast.clamp(-255.0, 255.0);
let factor = (259.0 * (c + 255.0)) / (255.0 * (259.0 - c));
let mut i = 0usize;
while i < src.len() {
for k in 0..3 {
let v = src[i + k] as f64;
let y = (factor * (v - 128.0) + 128.0 + b).round().clamp(0.0, 255.0) as u8;
dst[i + k] = y;
}
dst[i + 3] = src[i + 3];
i += 4;
}
}
fn box_blur_rgba_into(src: &[u8], dst: &mut [u8], w: u32, h: u32, r: u32) {
if r == 0 { dst.copy_from_slice(src); return; }
let w = w as usize;
let h = h as usize;
let win = (2 * r + 1) as usize;
let mut tmp = vec![0u8; src.len()];
// 水平:src -> tmp
for y in 0..h {
let mut sr: u32 = 0; let mut sg: u32 = 0; let mut sb: u32 = 0;
for dx in 0..win {
let x = clamp_i(dx as isize - r as isize, 0, (w - 1) as isize) as usize;
let i = (y * w + x) * 4;
sr += src[i] as u32; sg += src[i + 1] as u32; sb += src[i + 2] as u32;
}
let mut i0 = (y * w) * 4;
tmp[i0] = (sr / win as u32) as u8;
tmp[i0 + 1] = (sg / win as u32) as u8;
tmp[i0 + 2] = (sb / win as u32) as u8;
tmp[i0 + 3] = src[i0 + 3];
for x in 1..w {
let x_add = clamp_i(x as isize + r as isize, 0, (w - 1) as isize) as usize;
let x_sub = clamp_i(x as isize - 1 - r as isize, 0, (w - 1) as isize) as usize;
let i_add = (y * w + x_add) * 4;
let i_sub = (y * w + x_sub) * 4;
sr = sr + src[i_add] as u32 - src[i_sub] as u32;
sg = sg + src[i_add + 1] as u32 - src[i_sub + 1] as u32;
sb = sb + src[i_add + 2] as u32 - src[i_sub + 2] as u32;
let i = (y * w + x) * 4;
tmp[i] = (sr / win as u32) as u8;
tmp[i + 1] = (sg / win as u32) as u8;
tmp[i + 2] = (sb / win as u32) as u8;
tmp[i + 3] = src[i + 3];
}
}
// 垂直:tmp -> dst
for x in 0..w {
let mut sr: u32 = 0; let mut sg: u32 = 0; let mut sb: u32 = 0;
for dy in 0..win {
let y = clamp_i(dy as isize - r as isize, 0, (h - 1) as isize) as usize;
let i = (y * w + x) * 4;
sr += tmp[i] as u32; sg += tmp[i + 1] as u32; sb += tmp[i + 2] as u32;
}
let mut i0 = x * 4;
dst[i0] = (sr / win as u32) as u8;
dst[i0 + 1] = (sg / win as u32) as u8;
dst[i0 + 2] = (sb / win as u32) as u8;
dst[i0 + 3] = src[i0 + 3];
for y in 1..h {
let y_add = clamp_i(y as isize + r as isize, 0, (h - 1) as isize) as usize;
let y_sub = clamp_i(y as isize - 1 - r as isize, 0, (h - 1) as isize) as usize;
let i_add = (y_add * w + x) * 4;
let i_sub = (y_sub * w + x) * 4;
sr = sr + tmp[i_add] as u32 - tmp[i_sub] as u32;
sg = sg + tmp[i_add + 1] as u32 - tmp[i_sub + 1] as u32;
sb = sb + tmp[i_add + 2] as u32 - tmp[i_sub + 2] as u32;
let i = (y * w + x) * 4;
dst[i] = (sr / win as u32) as u8;
dst[i + 1] = (sg / win as u32) as u8;
dst[i + 2] = (sb / win as u32) as u8;
dst[i + 3] = src[i + 3];
}
}
}
fn convolve3x3_into(src: &[u8], dst: &mut [u8], w: u32, h: u32, k: &[f32; 9]) {
let w = w as usize;
let h = h as usize;
for y in 0..h {
for x in 0..w {
let mut acc = [0f32; 3];
for ky in 0..3 {
for kx in 0..3 {
let sx = clamp_i(x as isize + kx as isize - 1, 0, (w - 1) as isize) as usize;
let sy = clamp_i(y as isize + ky as isize - 1, 0, (h - 1) as isize) as usize;
let s = (sy * w + sx) * 4;
let kv = k[ky * 3 + kx];
acc[0] += kv * src[s] as f32;
acc[1] += kv * src[s + 1] as f32;
acc[2] += kv * src[s + 2] as f32;
}
}
let i = (y * w + x) * 4;
dst[i] = acc[0].round().clamp(0.0, 255.0) as u8;
dst[i + 1] = acc[1].round().clamp(0.0, 255.0) as u8;
dst[i + 2] = acc[2].round().clamp(0.0, 255.0) as u8;
dst[i + 3] = src[i + 3];
}
}
}
#[wasm_bindgen]
pub fn apply_pipeline_fast(input: &[u8], w: u32, h: u32, ops: &JsValue) -> Result<Vec<u8>, JsValue> {
let expected = (w as usize) * (h as usize) * 4;
if input.len() != expected {
return Err(JsValue::from_str("input length mismatch"));
}
let ops: Vec<Op> = swb::from_value(ops.clone())
.map_err(|e| JsValue::from_str(&format!("bad ops: {e}")))?;
// A: 來源(先複一份 input);B: 目的(只配置一次)
let mut a = input.to_vec();
let mut b = vec![0u8; expected];
let mut toggle = false; // false: 下一步寫 b;true: 寫回 a
for op in ops {
match op {
Op::Grayscale => {
if !toggle { grayscale_into(&a, &mut b); } else { grayscale_into(&b, &mut a); }
}
Op::BrightnessContrast { b: br, c } => {
if !toggle { brightness_contrast_into(&a, &mut b, br, c); }
else { brightness_contrast_into(&b, &mut a, br, c); }
}
Op::Blur { r } => {
if !toggle { box_blur_rgba_into(&a, &mut b, w, h, r); }
else { box_blur_rgba_into(&b, &mut a, w, h, r); }
}
Op::Conv3x3 { k } => {
if !toggle { convolve3x3_into(&a, &mut b, w, h, &k); }
else { convolve3x3_into(&b, &mut a, w, h, &k); }
}
}
toggle = !toggle;
}
let out = if toggle { &b } else { &a };
Ok(out.to_vec()) // 回 JS
}
rm -rf pkg
wasm-pack build --target web --out-dir pkg --out-name rustwasm_test
前端什麼都不用動,只是把呼叫的名字從 apply_pipeline 換成 apply_pipeline_fast,其他都一樣:
import init, { apply_pipeline_fast as apply_pipeline } from 'rustwasm-test'
cd demo
pnpm remove rustwasm-test
pnpm add file:../pkg
pnpm dev
哈哈沒什麼變 :(´□`」 ∠):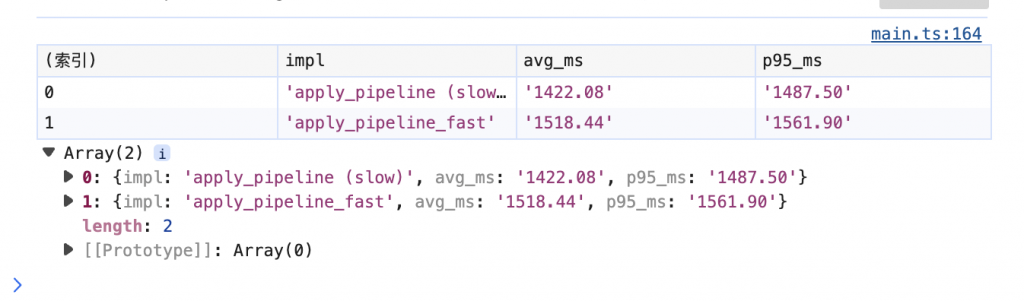
因為 ping-pong buffer 解決的是「分配次數」問題,不是「資料搬運量」問題。
現在的影像處理屬於 memory-bound 工作:每套一個效果,整張圖就要讀一次、寫一次。無論用單純 Vec::to_vec(),還是用 A/B 緩衝乒乓交換,每個 pass 的讀寫流量完全一樣,所以總時間幾乎不會變。
更細一點的原因:
tmp = vec![0u8; len] 每次都建,等於仍然做了一次大配置。所以我們看到的結果是:fast 版 vs slow 版平均時間幾乎一樣,頂多 p95 穩定性稍微改善(allocator/GC 壓力少一點)。
今天颱風來,我覺得應該要放颱風假。今天一整天吃一個麥當勞優惠套餐,兩塊薯餅兩個漢堡跟四塊雞塊還有兩杯飲料 159 元,一日三餐十分超值,還只要出門一次就好,不用淋到雨。
乒乓緩衝感覺不太能用在這裡,要減少複製量才是根本解決之道。


 iThome鐵人賽
iThome鐵人賽