在關鍵字搜尋中,系統只會單純的查找題目和答案中有沒有包含關鍵字,但我希望可以搜尋到和這個關鍵字相關的內容,並且依照相關度來排序。那這又有了另一個問題,要怎麼判斷相關程度?這時候就需要用到向量搜尋。
向量搜尋是什麼?不同於前幾天做的關鍵字搜尋,向量搜尋會透過把文字轉換為向量,來判斷文字之間的關聯性。在開始之前,我們需要先生成所有題目的向量。
def embeddings():
import os
import json
from mistralai import Mistral
api_key = os.environ.get("MISTRAL_API_KEY")
# 載入題目 JSON 檔案
json_path = os.path.join( "題目檔案路徑" )
try:
with open(json_path, 'r', encoding='utf-8-sig') as f:
questions = json.load(f)
print("成功載入題目檔案。")
except FileNotFoundError:
print(f"錯誤: 找不到題目檔案於 {json_path}")
return
except json.JSONDecodeError as e:
print(f"解析 JSON 檔案時發生錯誤: {e}")
return
client = Mistral(api_key=api_key)
model = "mistral-embed"
# 提取所有題目,存到一個列表中
questions_text = [item.get("題目", "") for item in questions if "題目" in item]
if not questions_text:
print("錯誤: 題目列表中沒有找到任何題目。")
return
# 為所有題目生成嵌入向量
try:
embeddings_batch_response = client.embeddings.create(
model=model,
inputs=questions_text,
)
# 從回應中提取嵌入向量
embeddings_list = [item.embedding for item in embeddings_batch_response.data]
print("成功生成所有題目的嵌入向量。")
except Exception as e:
print(f"生成嵌入向量時發生錯誤: {e}")
return
# 將題目及其嵌入向量儲存為 JSON 檔案
output_data = []
# 遍歷原始題目和新生成的向量,將它們組合起來
for i, item in enumerate(questions):
if i < len(embeddings_list):
item["embedding"] = embeddings_list[i]
output_data.append(item)
output_path = os.path.join( "存檔路徑" )
try:
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(output_data, f, ensure_ascii=False, indent=4)
print(f"成功將嵌入向量儲存至 {output_path}")
except IOError as e:
print(f"寫入檔案時發生錯誤: {e}")
Mistral Embed模型是什麼?
Mistral Embed模型是一個專門設計來把文字轉換成向量的模型。文字會被轉換為一個高維度的向量,能夠應用在分群、語意比對等方面。
生成後找到檔案會發現,embedding欄位內容多的看不到底,這是因為Mistral Embed模型會將文字轉換為一個1024維的向量,排起來就是一條看不到底的超長陣列。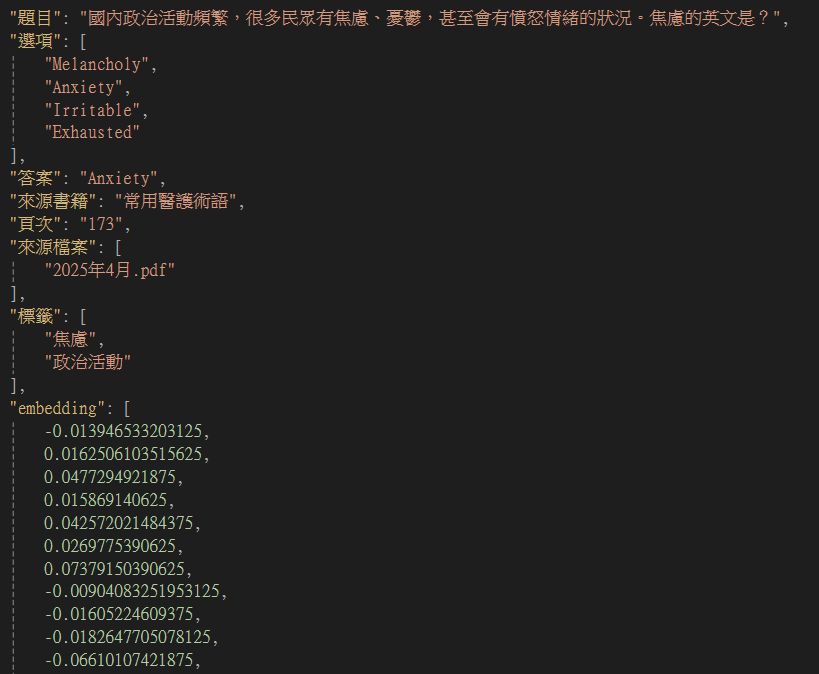
今天成功把題目的向量都生成好了,明天來加入向量搜尋。

