在昨天的文章中,我們探討了 Uvicorn 和 Gunicorn 這兩位 ASGI 伺服器的好夥伴。今天,我們要來談一個在應用程式啟動與關閉時,用來管理資源的關鍵功能——lifespan。

lifespan 是 ASGI 規範提供的特性,FastAPI 基於 ASGI 構建因此能夠原生支援這個強大的生命週期管理機制。它使用非同步上下文管理器來處理應用程式啟動前和關閉時的資源管理:
這是 ASGI 相較於傳統 WSGI 的重要優勢之一。
想像你的應用程式需要載入一個數 GB 的 AI 模型。這個操作可能需要幾秒鐘,如果放在 API 函式中:
@app.get("/predict")
async def predict():
model = load_heavy_model() # 每次請求都要載入!
return model.predict(data)
第一個使用者將面臨極長的等待時間,後續請求也會重複載入。使用 lifespan 可以解決這個問題:
from contextlib import asynccontextmanager
from fastapi import FastAPI
import time
# 全域變數儲存載入的資源
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# 在應用程式啟動時執行
print("應用程式啟動中...")
print("正在載入 AI 模型...")
# 模擬耗時的載入過程
time.sleep(3)
ml_models["my_model"] = "這是一個很棒的 AI 模型"
print("模型載入完成!")
yield
# 在應用程式關閉時執行
print("應用程式關閉中...")
ml_models.clear()
print("模型已卸載,資源已清理。")
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict():
model = ml_models.get("my_model")
if model:
return {"prediction": f"使用 {model} 進行預測"}
return {"error": "模型尚未載入"}
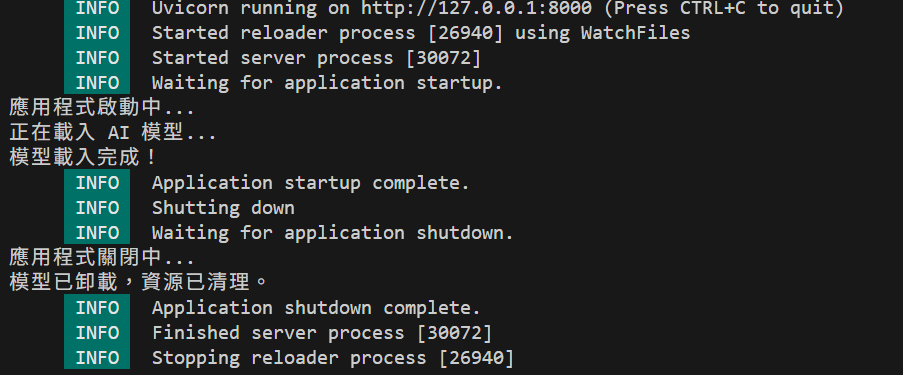
@asynccontextmanager:建立非同步上下文管理器的裝飾器yield 之前:應用程式啟動前執行(初始化資源)yield 之後:應用程式關閉前執行(清理資源)FastAPI(lifespan=lifespan):將 lifespan 函式註冊到 FastAPI 實例當啟動應用程式時,你會先看到模型載入訊息,然後才看到 Uvicorn 的啟動提示,證明初始化程式碼確實在伺服器就緒前執行。
在傳統的 WSGI 框架中,缺乏標準化的應用程式生命週期管理機制,開發者常需使用各種 workaround:
AppConfig.ready() 或在 __init__.py 初始化資源@app.before_first_request 已被棄用,因為在多線程或多進程下行為不一致)preload_app 或 post_fork)或系統訊號處理,但這些方法較複雜且容易出錯ASGI 則透過標準化的 lifespan 協定,在應用程式啟動與關閉時觸發事件,使資源初始化與釋放更簡單且可預測。
lifespan 是 FastAPI 中管理應用程式生命週期的重要工具,特別適合用於:
透過 ASGI 原生支援的 lifespan 機制,我們能夠以非同步、標準化的方式管理應用程式資源,這也是 FastAPI 相較於傳統框架的一大優勢。

