延續前幾天我們有 links.csv、crawler.db 的連結資料。今天做一個超實用的小工具:
一次檢查一堆網址的可用性,記錄 HTTP 狀態碼、是否成功、最終跳轉網址、延遲(ms),輸出成 CSV;也可把結果寫回 SQLite 做歷史記錄。
需要的套件
(前面 Day 4 已裝過 requests,沒裝就裝一下)
pip install requests
檔名:link_check.py
# link_check.py — Day 13:批次網址健檢器
from __future__ import annotations
import argparse, csv, sqlite3, time, datetime as dt
from pathlib import Path
from typing import List, Tuple, Iterable
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
UA = ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0 Safari/537.36")
def load_from_csv(path: Path, limit: int | None) -> List[Tuple[int, str]]:
urls: List[Tuple[int, str]] = []
with path.open("r", encoding="utf-8", newline="") as f:
r = csv.DictReader(f)
for i, row in enumerate(r, 1):
u = (row.get("url") or "").strip()
if not u:
continue
rid = int(row.get("id", i))
urls.append((rid, u))
if limit and len(urls) >= limit:
break
return urls
def load_from_db(db: Path, limit: int | None) -> List[Tuple[int, str]]:
con = sqlite3.connect(str(db))
con.row_factory = sqlite3.Row
cur = con.execute("SELECT id, url FROM links ORDER BY id DESC " + (f"LIMIT {int(limit)}" if limit else ""))
rows = [(int(r["id"]), str(r["url"])) for r in cur.fetchall() if r["url"]]
con.close()
return rows
def check_one(url_id: int, url: str, timeout: float, insecure: bool) -> dict:
headers = {"User-Agent": UA}
verify = not insecure
t0 = time.perf_counter()
try:
# 先 HEAD,405/403 等再退回 GET
resp = requests.head(url, allow_redirects=True, timeout=timeout, headers=headers, verify=verify)
if resp.status_code in (405, 403, 400, 501) or resp.status_code >= 400:
resp = requests.get(url, allow_redirects=True, timeout=timeout, headers=headers, verify=verify, stream=True)
elapsed_ms = int((time.perf_counter() - t0) * 1000)
ok = 200 <= resp.status_code < 400
return {
"id": url_id,
"url": url,
"status": resp.status_code,
"ok": 1 if ok else 0,
"final_url": resp.url,
"elapsed_ms": elapsed_ms,
"error": "",
"checked_at": dt.datetime.now().isoformat(timespec="seconds"),
}
except requests.exceptions.SSLError as e:
elapsed_ms = int((time.perf_counter() - t0) * 1000)
return {"id": url_id, "url": url, "status": "", "ok": 0, "final_url": "",
"elapsed_ms": elapsed_ms, "error": f"SSL: {e}", "checked_at": dt.datetime.now().isoformat(timespec="seconds")}
except Exception as e:
elapsed_ms = int((time.perf_counter() - t0) * 1000)
return {"id": url_id, "url": url, "status": "", "ok": 0, "final_url": "",
"elapsed_ms": elapsed_ms, "error": str(e), "checked_at": dt.datetime.now().isoformat(timespec="seconds")}
def write_csv(rows: Iterable[dict], out_path: Path):
out_path.parent.mkdir(parents=True, exist_ok=True)
cols = ["id", "url", "status", "ok", "final_url", "elapsed_ms", "error", "checked_at"]
with out_path.open("w", encoding="utf-8", newline="") as f:
w = csv.DictWriter(f, fieldnames=cols)
w.writeheader()
for r in rows:
w.writerow(r)
def save_to_db(db: Path, rows: Iterable[dict]):
con = sqlite3.connect(str(db))
con.execute("""
CREATE TABLE IF NOT EXISTS link_checks(
id INTEGER PRIMARY KEY AUTOINCREMENT,
url_id INTEGER,
status INTEGER,
ok INTEGER,
final_url TEXT,
elapsed_ms INTEGER,
error TEXT,
checked_at TEXT
)
""")
con.executemany("""
INSERT INTO link_checks(url_id, status, ok, final_url, elapsed_ms, error, checked_at)
VALUES(:id, :status, :ok, :final_url, :elapsed_ms, :error, :checked_at)
""", list(rows))
con.commit()
con.close()
def main():
ap = argparse.ArgumentParser(description="批次網址健檢器:狀態碼/跳轉/延遲 -> CSV,可選擇寫回 SQLite")
src = ap.add_mutually_exclusive_group(required=True)
src.add_argument("--csv", type=Path, help="來源 CSV(需含 url 欄,最好加 id)")
src.add_argument("--db", type=Path, help="來源 SQLite(讀取 links 表)")
ap.add_argument("--out", type=Path, default=Path("check_result.csv"), help="輸出 CSV 路徑")
ap.add_argument("--limit", type=int, default=0, help="最多檢查幾筆(0=全部)")
ap.add_argument("--timeout", type=float, default=6.0, help="逾時秒數(預設 6)")
ap.add_argument("--workers", type=int, default=8, help="同時併發數(預設 8)")
ap.add_argument("--insecure", action="store_true", help="忽略 SSL 憑證(除非必要,不建議)")
ap.add_argument("--save-db", action="store_true", help="把結果寫回 SQLite(需同時使用 --db)")
args = ap.parse_args()
limit = args.limit if args.limit and args.limit > 0 else None
if args.csv:
items = load_from_csv(args.csv, limit)
else:
items = load_from_db(args.db, limit)
total = len(items)
if total == 0:
print("沒有可檢查的網址。")
return
print(f"開始檢查,共 {total} 筆,timeout={args.timeout}s,workers={args.workers} …")
results: List[dict] = []
with ThreadPoolExecutor(max_workers=args.workers) as ex:
futs = [ex.submit(check_one, uid, url, args.timeout, args.insecure) for (uid, url) in items]
for i, fut in enumerate(as_completed(futs), 1):
r = fut.result()
results.append(r)
status = r["status"] if r["status"] != "" else "ERR"
print(f"[{i:>4}/{total}] {status:>3} {r['elapsed_ms']:>5}ms {r['url'][:80]}")
# 輸出 CSV
write_csv(results, args.out)
print(f"✅ 已輸出 CSV:{args.out}")
# 可選:寫回 DB
if args.save_db:
if not args.db:
print("⚠️ 需搭配 --db 才能寫回資料庫")
else:
save_to_db(args.db, results)
print(f"✅ 已寫入 SQLite:{args.db} 的 link_checks 表")
if __name__ == "__main__":
main()
使用方式
python link_check.py --csv links.csv --out check_links.csv --limit 50
python link_check.py --db crawler.db --out check_db.csv --limit 100
python link_check.py --db crawler.db --out check_fast.csv --workers 16 --timeout 5
python link_check.py --db crawler.db --save-db --out check.csv
實作: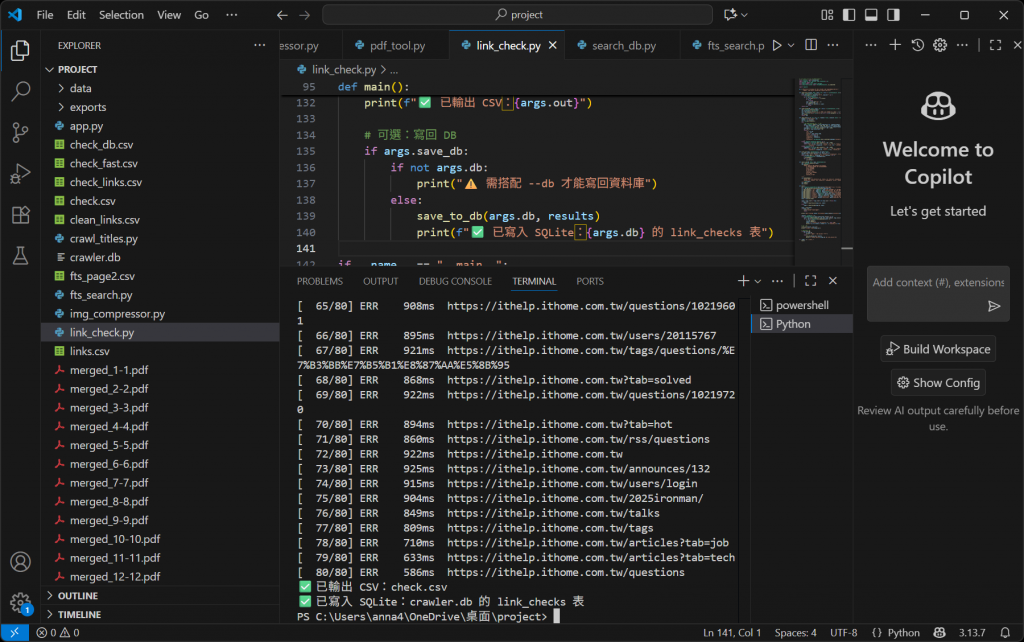
小提醒
SSL: 相關錯誤:環境的 CA 憑證驗證失敗,可先加 --insecure 測試(不建議長期使用)。
太多 403/429:網站可能擋爬;把 --workers 調小、--timeout 調高,或改時段再試。
CSV 沒有 url 欄:請確認來源 CSV 至少有 url 欄位,id 欄可選。
DB 模式沒資料:確定 crawler.db 裡有 links(text, url) 表。
 eyeyeyeye
eyeyeyeye

 iThome鐵人賽
iThome鐵人賽