Day 12 我們已經把影像管線搬進 Web Worker,讓主執行緒只管 UI,所有運算交給 Worker,不卡 UI。但單工有個問題:如果你在 UI 快速連續拖動亮度滑桿,主執行緒會一直丟任務進 Worker,而 Worker 只能一個一個跑完,導致前幾筆運算白白浪費(算完結果早就過期),UI 反而延遲。
今天要升級成 多工 + 佇列:
這樣狂按 UI 的時候,前面不會堆積;如果電腦有多核心,也能更快出結果。
id。// demo/src/workerPool.ts
export class WorkerPool {
private workers: Worker[]
private idle: Worker[] = []
private queue: { id: number; w: number; h: number; ops: unknown[]; bytes: Uint8Array; resolve: (out: Uint8Array)=>void; reject:(err:any)=>void }[] = []
private lastId = 0
constructor(size: number) {
this.workers = Array.from({ length: size }, () => new Worker(new URL('./worker.ts', import.meta.url), { type: 'module' }))
this.idle = [...this.workers]
// 每個 worker 設置 listener
this.workers.forEach(w => {
w.onmessage = (ev: MessageEvent<any>) => {
const data = ev.data
if (data?.ok) {
const job = this.queue.shift() // 拿對應任務
job?.resolve(data.bytes as Uint8Array)
} else {
job?.reject(data?.error)
}
this.idle.push(w)
this.schedule() // 看還有沒有排隊任務
}
w.postMessage({ type: 'init' })
})
}
run(w: number, h: number, ops: unknown[], bytes: Uint8Array) {
return new Promise<Uint8Array>((resolve, reject) => {
const id = ++this.lastId
this.queue.push({ id, w, h, ops, bytes, resolve, reject })
this.schedule()
})
}
private schedule() {
if (this.idle.length === 0 || this.queue.length === 0) return
const wkr = this.idle.pop()!
const job = this.queue[0]! // 取第一筆
wkr.postMessage({ type: 'run', w: job.w, h: job.h, ops: job.ops, bytes: job.bytes })
}
}
// demo/src/main.ts
import { WorkerPool } from './workerPool'
const pool = new WorkerPool(2) // 開 2 個 worker
async function runPipeline(ops: unknown[]) {
if (!w || !h) return
const img = ctx.getImageData(0, 0, w, h)
const input = new Uint8Array(img.data.buffer)
try {
const out = await pool.run(w, h, ops, input)
img.data.set(out)
ctx.putImageData(img, 0, 0)
} catch (e) {
showWasmError(e)
}
}
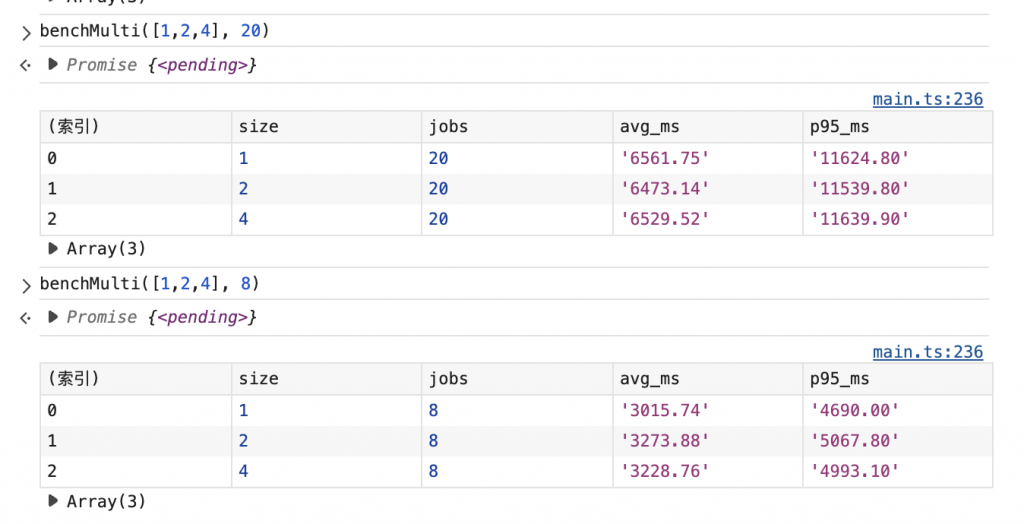
我用同一張大圖、同一組管線 { grayscale → bc(40,60) → blur(r=3) } 做兩組量測:丟 8 個任務與 20 個任務,分別測 pool size = 1 / 2 / 4。以 avg_ms(平均單次耗時)與 p95_ms(95 百分位)觀察:
jobs=8
size=1:avg ≈ 3.0–4.8s,p95 ≈ 4.7–6.6s
size=2:avg 降到 ≈ 2.9–3.1s,p95 也略降(≈ 4.5–4.8s)
size=4:有時反而變慢(avg 可飆到 8s+,p95 10s+)
推測從 1→2 條 Worker 有助益,但再擴到 4 條時,排程與傳輸開銷抵銷了平行效益。
jobs=20
size=1/2/4 三組幾乎同速:avg 都落在 ≈ 6.5s,p95 ≈ 11.6s
粗估這組工作是 memory-bound(每個 pass 都要全圖掃一遍),瓶頸是記憶體頻寬與資料搬運,新增 Worker 對總時間的幫助有限;多工主要提升「主線不卡」與「尾延遲穩定度」,不是線性加速。


 iThome鐵人賽
iThome鐵人賽