
昨天我們討論了為什麼需要消息佇列——為了讓 API 變得俐落,並且將系統的寫入壓力轉移到後端。
今天,我們來實作生產者 (Producer)。
生產者的設計原則只有一個:快速地把訊息丟給佇列。
快速:API 的生命週期內不應該有任何延遲。
單純:它不需要知道這個訊息是什麼,也不需要知道如果發送失敗了該怎麼辦。
誠實:如果發送失敗,它必須立刻、誠實地向上層(API 處理函數)報告失敗。
先設計好資料結構。
package model
import "time"
// OrderMessage 是我們要發送到佇列的唯一資料結構。
// 它必須包含完成訂單所需的所有資訊。
type OrderMessage struct {
OrderID string `json:"order_id"`
UserID string `json:"user_id"`
TicketID string `json:"ticket_id"`
Quantity int `json:"quantity"`
TotalAmount float64 `json:"total_amount"`
CreatedAt time.Time `json:"created_at"`
RequestID string `json:"request_id"` // 這是最重要的欄位,沒有它日誌就是無效的了。
}
RequestID 是系統的黃金線索。確保它從 Gin 的 middleware 開始,一路被傳遞到這裡。
我們只需要一個能和 Redis 溝通的 struct。
package queue
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
// RedisProducer 負責將消息發送到 Redis Streams。
// 注意:它很笨,沒有重試邏輯。這是故意的。
type RedisProducer struct {
client *redis.Client
}
// NewRedisProducer 建立一個新的生產者。
func NewRedisProducer(client *redis.Client) (*RedisProducer, error) {
// 假設 client 已經被外部正確初始化和管理。
// 我們不應該在一個小小的生產者裡還要去管連線池、密碼這些破事。
if client == nil {
return nil, fmt.Errorf("redis client cannot be nil")
}
return &RedisProducer{client: client}, nil
}
// Send 將序列化後的訊息發送到指定的 stream (topic)。
// 它的邏輯很簡單:執行 XADD 命令,然後返回 Redis 給的 messageID 或一個錯誤。
func (p *RedisProducer) Send(ctx context.Context, topic string, message []byte) (string, error) {
// Redis Streams 的 Values 是一個 map。我們用一個固定的 key "data" 來儲存我們的 JSON 訊息。
// 消費者端也必須知道這個 key。
values := map[string]interface{}{
"data": message,
}
// "*" 讓 Redis 自動生成一個基於時間的、唯一的 ID。
args := &redis.XAddArgs{
Stream: topic,
ID: "*",
Values: values,
}
// 這就是生產者的全部工作。
// 如果 Redis 慢或者掛了,這個呼叫會返回錯誤,然後就沒它的事了。
messageID, err := p.client.XAdd(ctx, args).Result()
if err != nil {
return "", fmt.Errorf("failed to send message to redis stream %s: %w", topic, err)
}
return messageID, nil
}
// Health 檢查與 Redis 的連線狀態。
// PING 命令就夠了。簡單、有效。
func (p *RedisProducer) Health(ctx context.Context) error {
return p.client.Ping(ctx).Err()
}
這個生產者非常單純 (stupidly simple),這正是我們想要的。
它沒有內部狀態、沒有背景 goroutine,只是一個 Redis 命令的乾淨封裝。
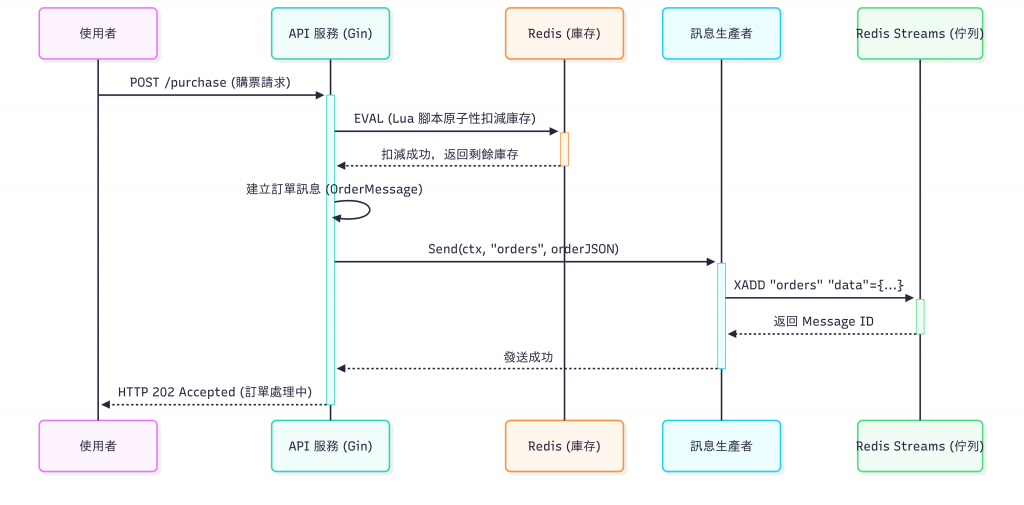
現在,我們來優化主要邏輯中的 purchaseTicket 函式。
package main
// ... (省略 main, init, and middleware 的部分,假設它們都已正確設定) ...
// purchaseTicket 處理購票請求。
// 這是系統中最重要的 hot path,它必須快。
func purchaseTicket(c *gin.Context) {
ctx := c.Request.Context()
requestID, _ := c.Get("RequestID").(string) // 我們信任 middleware
var req struct {
UserID string `json:"user_id"`
TicketID string `json:"ticket_id"`
Quantity int `json:"quantity"`
}
if err := c.ShouldBindJSON(&req); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "invalid request payload"})
return
}
// 1. 原子地扣減庫存
// 這一步是唯一需要鎖定資源的操作,我們用 Lua 腳本保證其原子性。
stockKey := "ticket:" + req.TicketID + ":stock"
decrScript := `
local stock = tonumber(redis.call("GET", KEYS[1]))
local requested = tonumber(ARGV[1])
if not stock or stock < requested then
return -1 -- 庫存不足
end
return redis.call("DECRBY", KEYS[1], requested)
`
result, err := redisClient.Eval(ctx, decrScript, []string{stockKey}, req.Quantity).Int64()
if err != nil {
log.Printf("Redis Eval error [req_id: %s]: %v", requestID, err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "internal system error"})
return
}
if result < 0 {
c.JSON(http.StatusConflict, gin.H{"error": "ticket sold out or not enough stock"})
return
}
// 2. 建立訂單訊息
// 庫存已成功扣減。從現在開始,我們必須成功地將訂單訊息發送出去。
orderID := uuid.New().String()
orderMsg := model.OrderMessage{
OrderID: orderID,
UserID: req.UserID,
TicketID: req.TicketID,
Quantity: req.Quantity,
TotalAmount: 100.0 * float64(req.Quantity), // 假設票價固定
CreatedAt: time.Now(),
RequestID: requestID,
}
orderJSON, err := json.Marshal(orderMsg)
if err != nil {
// 這是一個嚴重的內部錯誤,代表我們的 model struct 有問題。
// 它幾乎不應該發生。
log.Printf("Failed to marshal order message [req_id: %s]: %v", requestID, err)
// 注意:我們不會在這裡嘗試恢復庫存!那只會讓事情更糟。
c.JSON(http.StatusInternalServerError, gin.H{"error": "internal system error"})
return
}
// 3. 發送訂單到佇列
_, err = producer.Send(ctx, "orders", orderJSON)
if err != nil {
// 這是最關鍵的失敗場景!
log.Printf("FATAL: Failed to send order to message queue [req_id: %s]: %v. STOCK IS NOW INCONSISTENT.", requestID, err)
// 我們絕不能嘗試恢復庫存。你不能保證恢復操作本身會成功。
// 我們能做的唯一正確的事,就是誠實地告訴客戶端我們出錯了,
// 同時發出最高級別的告警,讓工程師立刻介入處理這個「不一致」的庫存。
c.JSON(http.StatusServiceUnavailable, gin.H{
"error": "The service is temporarily unavailable. Please try again later.",
})
return
}
// 4. 立即返回成功
// 訊息已進入佇列。API 的任務完成了。
log.Printf("Order enqueued successfully [req_id: %s, order_id: %s]", requestID, orderID)
c.JSON(http.StatusAccepted, gin.H{
"message": "Your order is being processed.",
"order_id": orderID,
})
}
當你看到上面那段 FATAL 等級的日誌時,代表系統進入了異常狀態,這時該怎麼辦?
告警 (Alerting):當你看到那條日誌時,你的監控系統(Prometheus, Datadog)應該立刻觸發 P1 等級的告警,通知值班的工程師 。
監控 (Monitoring):建立一個儀表板,專門追蹤「佇列發送失敗訂單數」。在正常情況下,這個數字必須是 0。
手動恢復 (Manual Intervention):收到告警後,工程師需要根據日誌中的 RequestID 與訂單內容,檢查 Redis 中的實際庫存。接著,判斷應該手動將訂單訊息重新送入佇列,或是將庫存加回去。在成熟的系統中,這通常會被做成一個內部維運工具。
我們不該期望程式碼能神奇地解決所有基礎設施等級的故障。
當資料庫或消息佇列服務中斷時,這就是一個系統性故障,需要人來介入。
今天,我們寫了一個簡單的生產者。
XADD。這樣我們就有了一個行為可預測的元件了。


 iThome鐵人賽
iThome鐵人賽