昨天說完 agent 的需求和架構之後,今天就可以一個步驟一個步驟設定 agent ,總共會有六個步驟。
要讓 Agent 去觸發 Lambda 幫你做事情,甚至是分析資料,需要使用 Bedrock 的 Mode ,所以第一步需要打開指定的 Model 權限。到 Bedrock 的 Console 按下 Modify model access ,即可選擇要使用的 Model 。
接著就可以來設定 Agent。到 Agent 的頁面,按下 Create agent 就可以新增 Agent。
首先需要設定 Name ,並決定要不要讓這個 Agent 有跟其他 Agent 合作的能力。
新增完 Agent 之後,還不能使用,需要選擇要搭配的 Model ,而且這個 Model 是要在 Step 1 有開啟存取權限的。

這一步還有一個非常重要的地方, Instructions for the Agent 一定要填,沒有填會無法讓 Agent 的狀態變成 Prepared ,填的內容也會影響使用者說的內容會不會觸發後面設定的 Action 。
這一步,就可以來新增一個 Action Group 。
設定 Agent group 的時候需要選擇 type ,要想一下是要使用 function 的方式觸發背後的 Lambda?還是要以 API 的形式觸發 Lambda?也要決定要使用既有的 Lambda,還是要新增一個 Lambda 。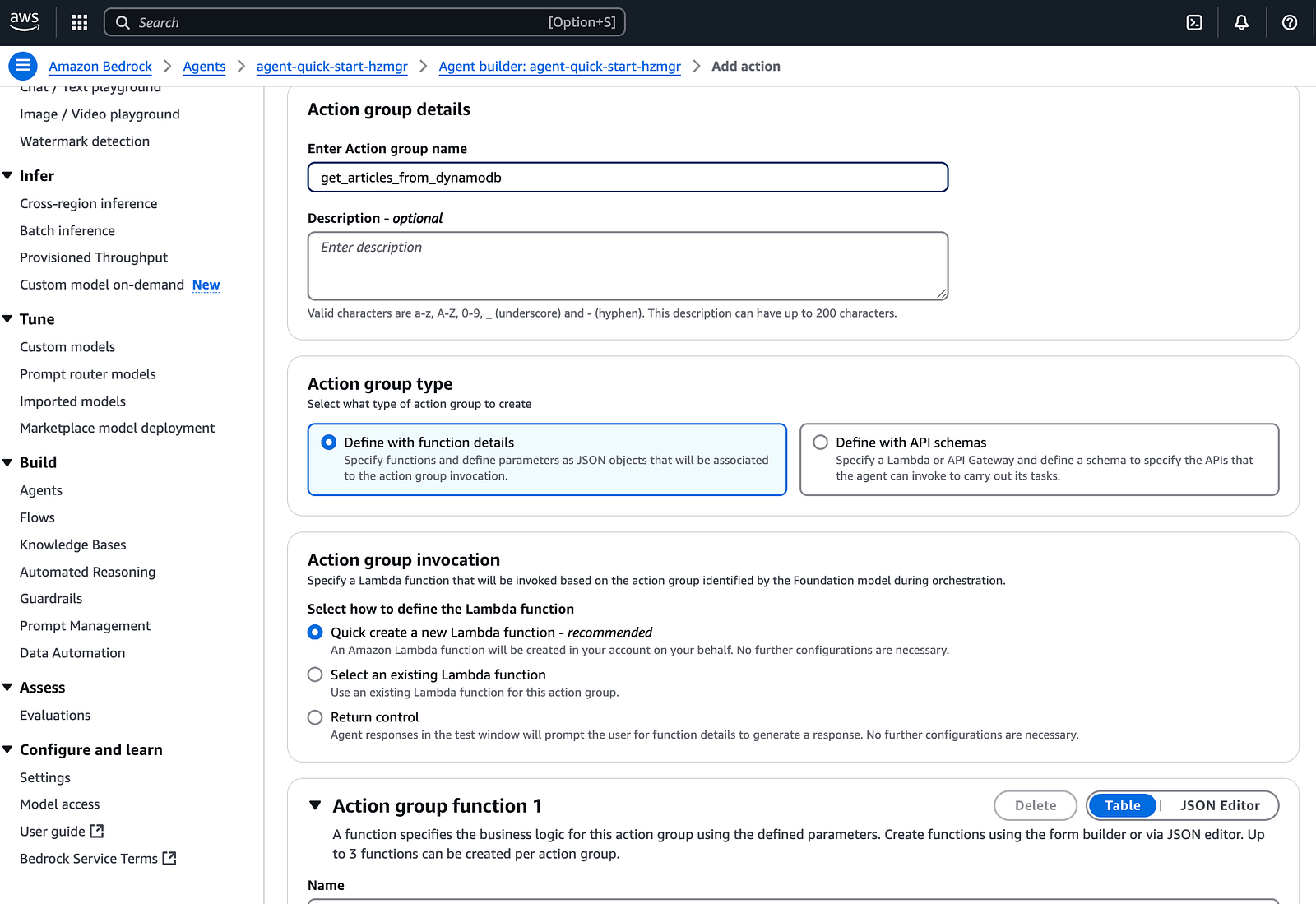
如果 type 選擇使用 function ,接著就需要設定 Agent group function ,決定觸發 Lambda 的時候,要不要送 parameter 給 Lambda 。
上一個步驟設定好了 Action 之後,就可以到對應的 Lambda 撰寫程式開發需要的功能,也就是查詢 DynamoDB 資料。
import json
import boto3
from decimal import Decimal
from datetime import datetime
class DecimalEncoder(json.JSONEncoder):
"""Helper class to convert Decimal objects to serializable types"""
def default(self, obj):
if isinstance(obj, Decimal):
return float(obj)
return super(DecimalEncoder, self).default(obj)
def lambda_handler(event, context):
print(f"Received event: {json.dumps(event)}")
try:
# Initialize DynamoDB resource
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Articles')
# Get optional parameters from event
limit = event.get('parameters', {}).get('limit', None)
status_filter = event.get('parameters', {}).get('status', None)
print(f"Starting scan of Articles table with limit: {limit}, status filter: {status_filter}")
# Set up scan parameters
scan_kwargs = {}
if limit:
try:
scan_kwargs['Limit'] = int(limit)
except ValueError:
scan_kwargs['Limit'] = 100 # Default fallback
# Add filter if status is specified
if status_filter:
from boto3.dynamodb.conditions import Attr
scan_kwargs['FilterExpression'] = Attr('status').eq(status_filter)
# Perform the scan
response = table.scan(**scan_kwargs)
items = response['Items']
# Handle pagination for complete data retrieval (up to a reasonable limit)
total_scanned = len(items)
max_items = 1000 # Prevent infinite loops and timeouts
while 'LastEvaluatedKey' in response and total_scanned < max_items:
print(f"Found {total_scanned} items so far, continuing scan...")
scan_kwargs['ExclusiveStartKey'] = response['LastEvaluatedKey']
response = table.scan(**scan_kwargs)
new_items = response['Items']
items.extend(new_items)
total_scanned += len(new_items)
print(f"Total items retrieved: {len(items)}")
# Prepare the response data
result_data = {
'success': True,
'total_count': len(items),
'articles': items,
'scan_info': {
'table_name': 'Articles',
'timestamp': datetime.utcnow().isoformat() + 'Z',
'has_more_data': 'LastEvaluatedKey' in response,
'applied_filters': {
'status': status_filter,
'limit': limit
}
}
}
# Log sample data for debugging
if items:
print(f"Sample article: {json.dumps(items[0], cls=DecimalEncoder)}")
# Return in Bedrock Agent format
return {
'messageVersion': '1.0',
'response': {
'actionGroup': event.get('actionGroup', ''),
'function': event.get('function', 'get_all_articles'),
'functionResponse': {
'responseBody': {
'TEXT': {
'body': json.dumps(result_data, cls=DecimalEncoder, ensure_ascii=False, indent=2)
}
}
}
}
}
except Exception as e:
print(f'Error scanning Articles table: {str(e)}')
error_data = {
'success': False,
'error': str(e),
'error_type': type(e).__name__,
'message': 'Failed to retrieve articles from DynamoDB table',
'timestamp': datetime.utcnow().isoformat() + 'Z'
}
return {
'messageVersion': '1.0',
'response': {
'actionGroup': event.get('actionGroup', ''),
'function': event.get('function', 'get_all_articles'),
'functionResponse': {
'responseBody': {
'TEXT': {
'body': json.dumps(error_data, ensure_ascii=False, indent=2)
}
}
}
}
}
這邊要注意的是, Lambda 需要回傳對的格式,不然 Agent 會無法分析結果。
{
'messageVersion': '1.0',
'response': {
'actionGroup': event.get('actionGroup', ''),
'function': event.get('function', 'get_all_articles'),
'functionResponse': {
'responseBody': {
'TEXT': {
'body': json.dumps(result_data, cls=DecimalEncoder, ensure_ascii=False, indent=2)
}
}
}
}
}
因為這篇文章的需求需要存取 DynamoDB ,所以 Lambda 綁定的 role ,需要加上存取 DynamoDB 的 Policy。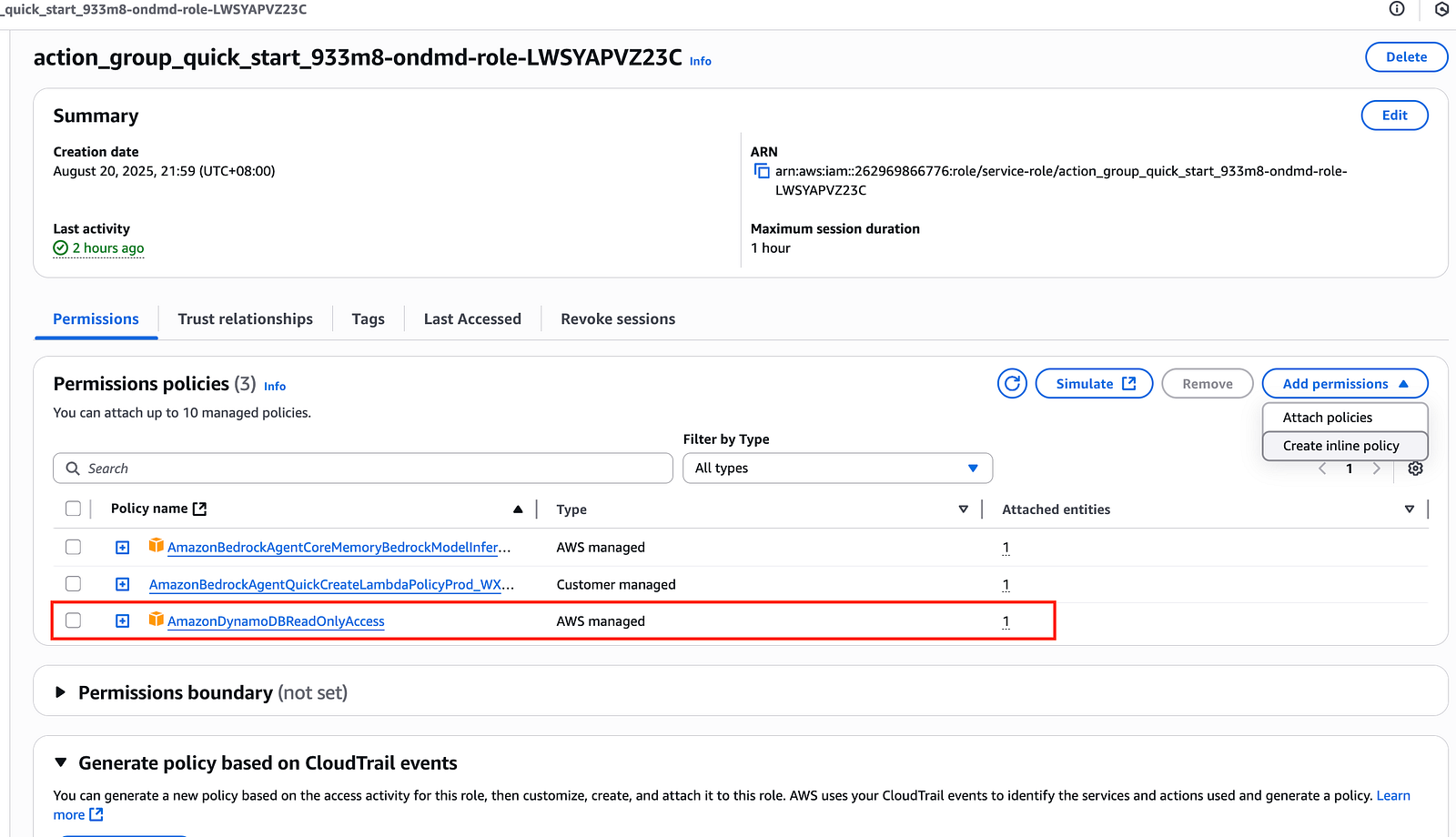
最後,就可以來測試機器人,測試之前還需要完成最後一個步驟 - Prepare 。
Prepare 完成之後,就可以開始測試機器人, AWS 提供一個快速測試的方法,可以透過右手邊的對話視窗進行簡單的測試。
從下面圖片可以看到,我想要撈取 Article 的資料, Agent 觸發了 Action ,並取得所有資料。
雖然在 Lambda 裡面寫的邏輯是取得所有 Article 的資料,但是 AI Model 分析完 Lambda 回覆的內容之後,可以幫你做更近一步的處理,只抓出 hjoru 的部分,這就是 AI 可以簡化工作流程的地方。
從 Lambda 的 log 可以清楚看到, Lambda 確實有被觸發,並取出 DynamoDB 裡面的兩筆資料。
因為有對 Agent 設定了 Instructions ,所以如果跟撈取資料不相關的問題,不會觸發背後的 Lambda ,並且有可能會被 AI Model 無情的拒絕 XD
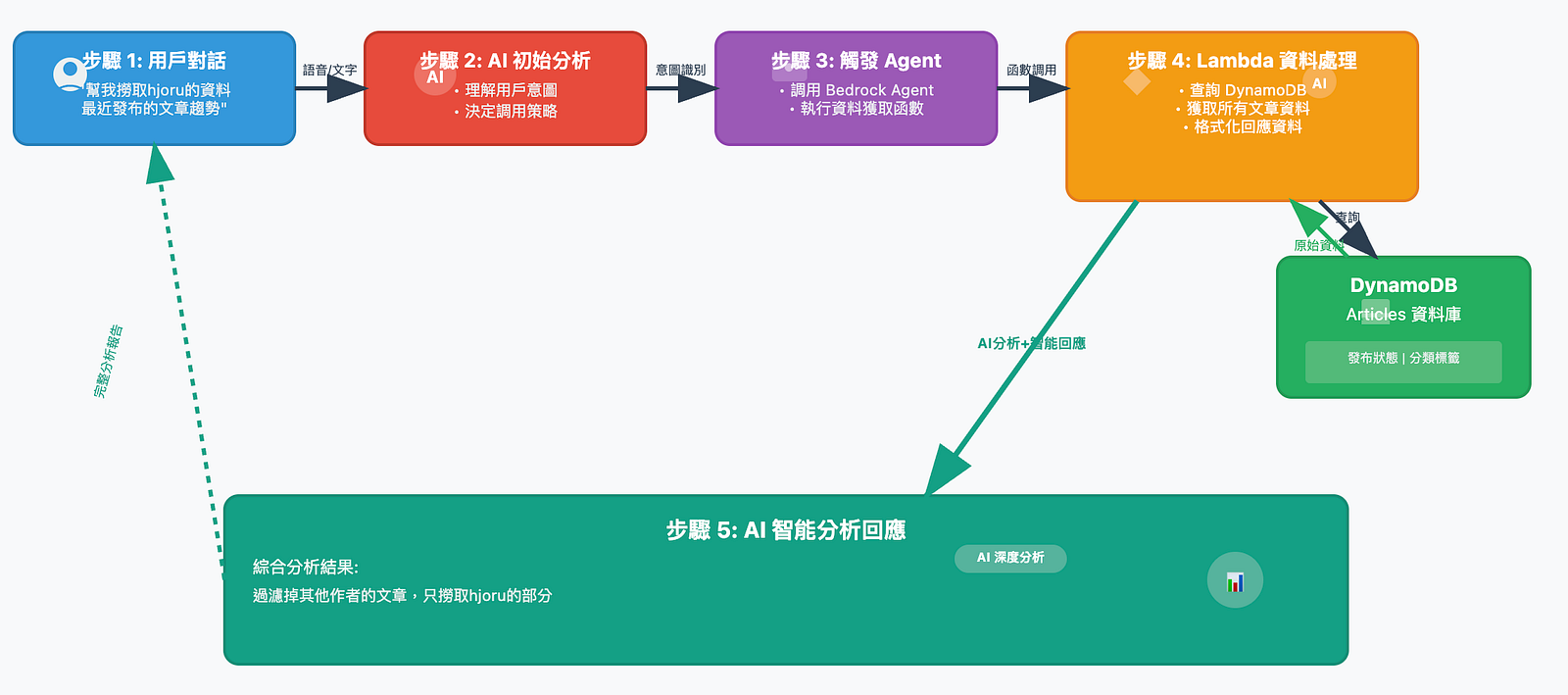
在完成這個系統並測試後發現, Bedrock Agent 的整個流程不只是協助觸發其他功能,還能夠把其他功能的回傳結果再進一步的分析,並回覆使用者想要的資訊,體會到了 AI 簡化工作的方便之處。
medium: 如何使用 AWS bedrock agent 查詢 DynamoDB 資料

