應用程式主流的佈署方式演進至k8s, 開關機(pod) 變得頻繁, 不像是vm 時期, 除非垂直擴展否則永不關機. VM 在不關機的情況下, 就算應用程式更新版本, 舊process 仍然可以持續執行, 直到程式結束或timeout; 而佈署在k8s 的應用程式單位是pod, 交由k8s 代為管理, 當pod 因任何因素需要被關閉時, process 面臨仍然在執行, 但宿主(即將) 停止的窘境
先快速且抽象地說, 便是讓process 將任務處理完/交接, 再讓它離開
1. 將收到payload 寫回關聯式資料庫
2. 發送付款成功事件(e.g. pub/sub)
3. Async Jobs
若process 中途被殺掉,結果可能是:
交給k8s 之後, 執行單位(pod) 掌控權已經不完全在你手上了
| 類型 | 說明 |
|---|---|
| Horizontal Pod Autoscaler | 離峰減少運算資源 |
| Rollout / Rollback | 發布新版/退回舊版 |
| OOMKilled | 記憶體抵達上線 |
| LivenessProbe Fail | 偵測失敗觸發重啟(非整個 pod, 會是以container 為單位) |
| Node Failure | 節點異常導致 Eviction |
| Manual Delete | 手動刪除 Pod |
回想管理VM 時, 若系統相當忙碌, 大多時候我們會用top 指令去找出最忙而且判斷可殺的process, 並且毫不留情地送它一個SIGKILL(編號9)的終止訊號
$ kill -9 $pid
但其實我們也可以改送SIGTERM(編號15) 這個終止訊號, 若該程式的作者當初有埋設SIGTERM 訊號的handler, 那代表程式的作者有考慮到這件事, 那便能讓這個process 有機會做到優雅關閉
$ kill -15 $pid
k8s 也採用同樣的手法, 刪掉pod 時, k8s 不會馬上送SIGKILL, 而是設計了一連串的終止流程讓process 有機會優雅關閉
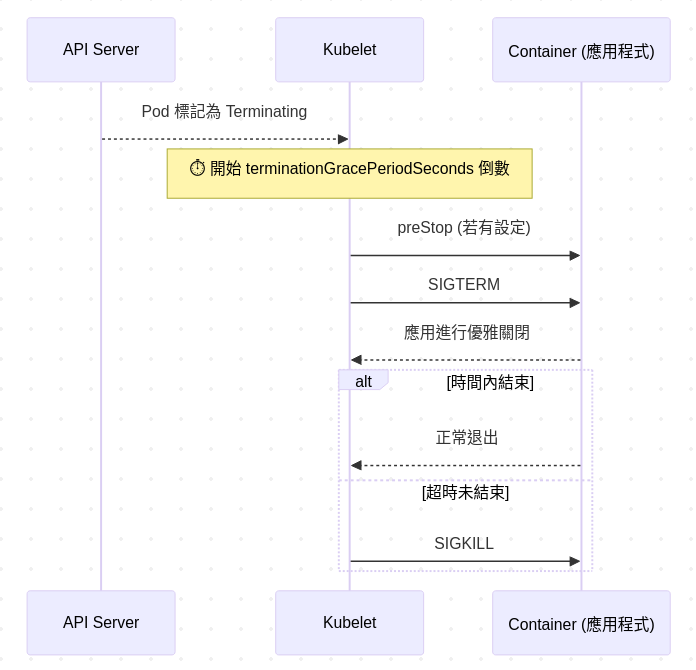
| 名稱 | 功能 | 說明 |
|---|---|---|
preStop |
container 關閉前的hook function | 如果這個container 無法註冊SIGTERM handler, 可使用preStop 實現優雅關閉, 並且這個hook 是在k8s 送出SIGTERM 之前執行的 |
SIGTERM |
優雅終止信號 | 由container 的PID 1 接收, 應用程式應處理此信號 |
terminationGracePeriodSeconds |
最大等待時間 | 預設 30 秒, 可依需要增減 |
筆者私心覺得terminationGracePeriodSeconds 的設計很像PM/EM 對RD 的靈魂拷問, "這張ticket 你還要做多久?" 有時候manager 問這個問題不一定是要壓時程, 只是單純想要透過估時, 更好地安排任務, 也許manager 希望別花太多時間在目前的任務, 趕緊往下個project 前進. 岔題了, 總之我們需要搞清楚程式還要跑多久, k8s 最多等 terminationGracePeriodSeconds 時間, 這個時間包含讓還在跑的程式得以繼續執行到正確結束, 若超過, k8s 就要真的停掉這個container 了
client -> cloudflare -> GCP Load Balancer -> k8s -> nginx -> php-fpm
p.s. GCP 與k8s 內部的連線管理相當複雜, 我們可以關注在能控制的連線即可, 以上四條 tcp 連線中, 實際可調整timeout 的是tcp3與 tcp4
p.p.s. 若cloudflare 作為CDN 用途時, 便是只有client 與cloudflare 進行tcp 連線而已
簡單說完了這個架構的TCP 連線的概念後, 便能來討論這些連線的timeout 設定
假設讓PHP worker 最多可以執行60 秒, 那nginx 與php-fpm 的連線可以設定成65 秒, 而LB backend 等待nginx 的回覆可以設定為70 秒
增加考慮優雅關閉: terminationGracePeriodSeconds 可以設定為 65~70 秒之間, 讓pod 的關閉在nginx 正確收到回傳之後
LB: 70s > Nginx: 65s > PHP: 60s
terminationGracePeriodSeconds: 67s
簡單地說, 這個架構下的所有服務並不是使用同一個時鐘, 若是設定成恰恰好都是60 秒, 實際上哪一條tcp 連線先斷沒有人說得準, 會演變成相當混亂的情況, 所以設定上應該讓外層皆略大於內層, 也就是外層要盡可能地等內層服務的回傳
一樣是那個靈魂拷問, 你還要做多久? 也就是api 還要執行多久?
實際去測量與統計是個不錯的辦法, 但太耗時費工了, 往infra 一點的層面思考, 只要知道整段request chain 的timeout 設定, 將terminationGracePeriodSeconds 定義在合理的數值便可, 以優雅關閉來說最極端的情況, 便是pod 剛標記為terminating 的前一刻, 時間花費最長的api 剛開始執行, 這支api 最久也就是執行到timeout 為止, 那麼為了要優雅地關閉, 便可將 terminationGracePeriodSeconds 設定為比timeout 再稍長一點的時間
php-fpm 是php 的process manager, 架構上會有一個master process 對應多個worker process, master 不負責處理程式, 而是與nginx 溝通, 接收nginx proxy 過來的請求, 轉派給worker
master process 通常會是container 的PID1, 但我們寫的php 程式碼是給worker process 執行的, 代表我們無法寫程式給PID1 註冊終止訊號處理SIGTERM
依照php 官方說明, 可以對fpm process 送QUIT 訊號即可優雅關閉master 與其worker process
$ kill -QUIT <php-fpm_master_pid>
筆者實測版本為php7.4, 認定有bug, 實際上php 會提早與nginx 斷連線*
若使用 php8.x 以上版本, 該問題雖部分修正, 但仍建議自控流程以確保穩定
註: 這是官方 issue(PHP Bug #76930, 原因是 QUIT signal 對 idle worker 行為不一致
故自定義了兩階段process 關閉的方法
執行程式碼的process (通常)就是PID1
pcntl_signal(SIGTERM, function () {
echo "Shutting down gracefully...\n";
finishPendingJobs();
exit(0);
});
執行程式碼的process (通常)就是PID1
框架內建 worker pool 管理, 可透過:
nodejs 的cluster 模式曾是處理高併發情境相當熱門的作法, 其概念大致上會是primary 程式中會依照執行單位有多少CPU 便啟動多少child process, 並且在primary 收到請求後將流量分配給child process 執行
當使用nodejs cluster mode 的程式要做優雅關閉時, primary 就是PID1, 可註冊終止訊號, 只要將終止訊號轉送給child 即可
// primary.js
process.on('SIGTERM', () => {
for (const id in cluster.workers) {
cluster.workers[id].process.kill('SIGTERM');
}
});
// child.js
process.on('SIGTERM', () => {
handleGracefulShutdown();
});
main.go (通常) 就是PID1, 可註冊終止訊號, 若有使用sub goroutine, 可用context.Context/chan 將終止訊號往goroutine 傳
// main goroutine
ctx, cancel := context.WithCancel(context.Background())
// 使用watiGroup 來等待sub goroutine
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
HandleWithContext(ctx)
}()
go func() {
if err := srv.ListenAndServe(); err != nil && err != http.ErrServerClosed {
fmt.Fprintf(os.Stderr, "listen: %s\n", err)
os.Exit(1)
}
}()
quit := make(chan os.Signal, 1)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM)
<-quit // 阻塞直到收到 signal
// main goroutine 執行到此處代表收到終止訊號
// 便可用cancel function 傳遞結束訊號給sub goroutine
cancel()
wg.Wait()
if err := srv.Shutdown(ctx); err != nil {
fmt.Fprintf(os.Stderr, "main: Server shutdown: %s\n", err)
} else {
fmt.Println("main: Server shutdown gracefully")
}
// sub goroutine
func HandleWithContext(ctx context.Context) {
i := 10
for {
select {
// 收到終止訊號, 做終止要做的事 e.g. 標出現在處理到哪
case <-ctx.Done():
fmt.Println("foo: shutdown received")
fmt.Println("foo: handling i")
fmt.Println(i)
return
// 正常情況下 e.g. 每秒處理一件事
default:
if i <= 0 {
return
}
i--
fmt.Println("foo: normal goroutine")
fmt.Println(i)
time.Sleep(1 * time.Second)
}
}
}
回頭檢視, 我們該如何確保程式真正理解自己的生命週期?
一起做個負責任的工程師吧😉
 fall1600
fall1600
