我們在看一些機器學習、人工智能、數據倉庫方面的資料時,經常會出現「神經網絡」、「深度學習算法」、「非監督學習」、「大模型」、「邏輯模型」等高頻詞彙。這些詞語有時會在同一篇文章中交叉出現,看似描述的是同一件事情,但所要表達的意思似乎又不盡相同,初學者很容易就被搞混了。
如果僅僅作爲宣傳報道或日常交流,並沒有太大問題,但若作爲專業人士,則要把概念的內涵和上下文搞搞清楚,否則很容易鬧出笑話。
我這裏先給出「模型 、算法、模型結構、數據模型、訓練」5個概念的精簡定義:
但即使你看懂了這五個概念的簡明定義,也不代表真正的理解其中的內涵,這裡我先問你一個問題:「支持向量機到底是指什麼?模型、算法亦或其它?」
接下來,就讓我詳細展開講講,答案會在最後揭曉~
算法的定義有許多版本,但其核心思想是一致的。算法可以被定義爲:一個明確的、有序的、有限的步驟集合,用於解決一個特定的問題或執行一個特定的任務。這個定義是非常通用的,適用於從最簡單的日常生活任務(例如烹飪食譜)到複雜的計算機科學問題的算法。
讓我們詳細分析這個定義:
事實上,我們可以把任何使計算機能夠按照我們預定目標運行的方法稱爲「算法」,不僅僅包括上面的舉例,在計算機領域常見的「冒泡排序」等基礎算法都可以算作「算法」的範疇,以下是冒泡算法的步驟流程: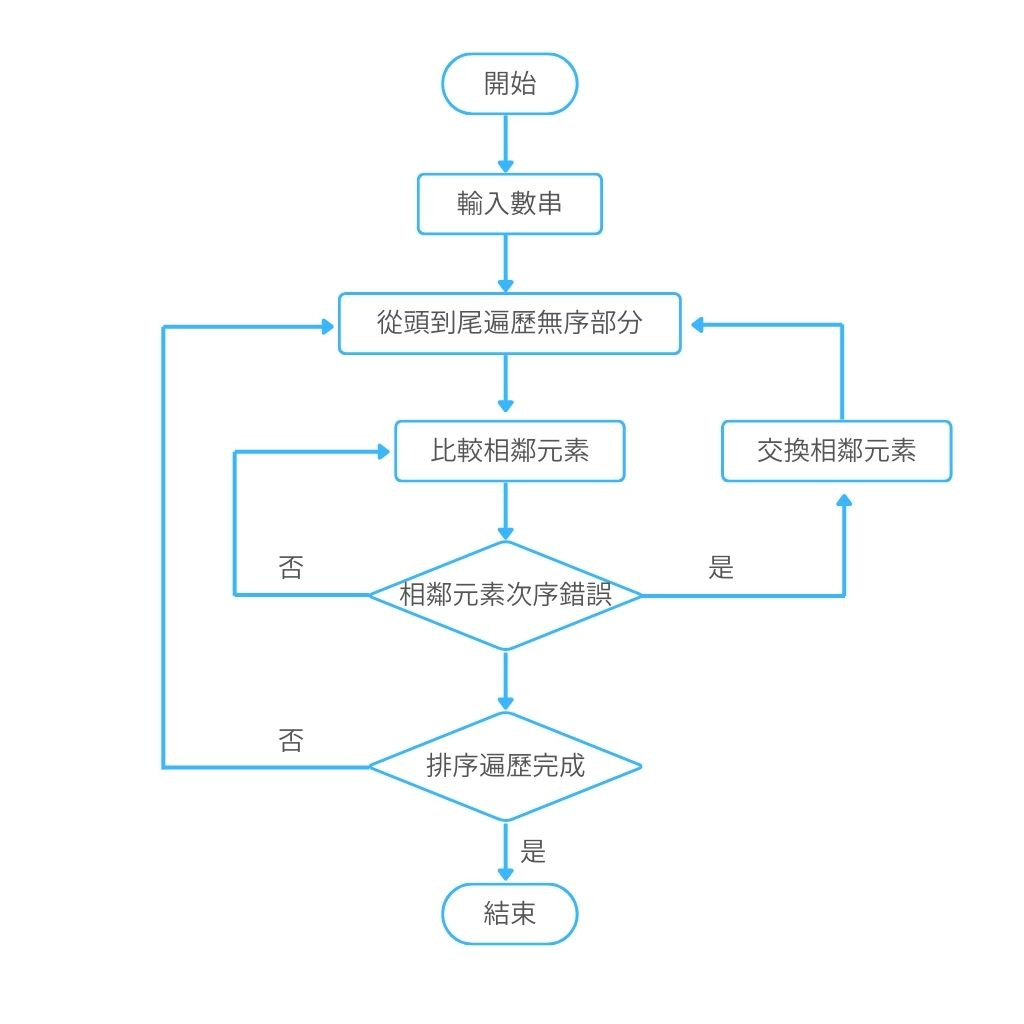
在機器學習和人工智能領域,「算法」這一詞語通常具有特定的含義和上下文。在這些領域,算法通常指的是:一種通過數據或經驗自動改進性能或逐漸適應某一任務的方法。
這個算法定義相對於傳統算法的特殊之處在於”學習”和”適應”。讓我們詳細分析這個定義:
在機器學習和AI的上下文中,算法可能包括決策樹算法、神經網絡算法、遺傳算法等。每種算法都有其特定的學習方法和適用的任務類型。下面示例了決策樹ID3算法的實現步驟: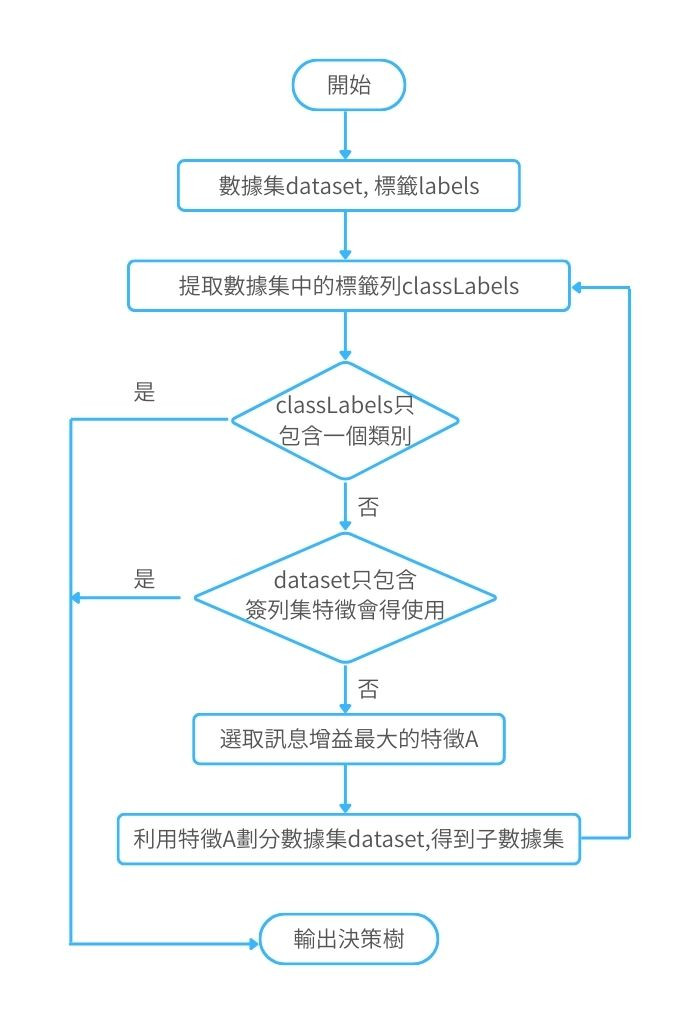
爲了更快更好地實現自己的算法,很多時候,人們喜歡把已經實現的、效果良好的算法做一些封裝,這樣,下次編寫算法的時候就可以直接拿來用了。我們常用的TensorFlow、PyTorch、MindSpore都是。
現在大模型中很熱的Transformer 可以被認爲是一種算法,因爲Transformer 描述瞭如何執行自注意力計算、如何結合輸入數據、如何通過神經網絡層傳遞數據等等,這個意義上的 “算法” 是描述模型在前向傳播和反向傳播期間所採取的計算步驟。
在更廣泛、跨學科的背景下,模型可以被定義爲:對現實世界某一部分的簡化和抽象表示,用於模擬、描述、預測或理解該部分的行爲或現象。這個定義的關鍵點包括:

數據模型和一般意義上的模型都是對現實世界事物的簡化和抽象表示,但數據模型體現的是現實世界或業務邏輯在數據層面的投影,是將數據元素以標準化的模式組織起來,用來模擬現實世界的信息框架和藍圖。比如通過抽象,數據模型可以爲世界的系統交互提供一個更易於理解和操作的視圖,可以專注於對特定任務或目標至關重要的實體和關係,從而忽略不相關或不重要的細節。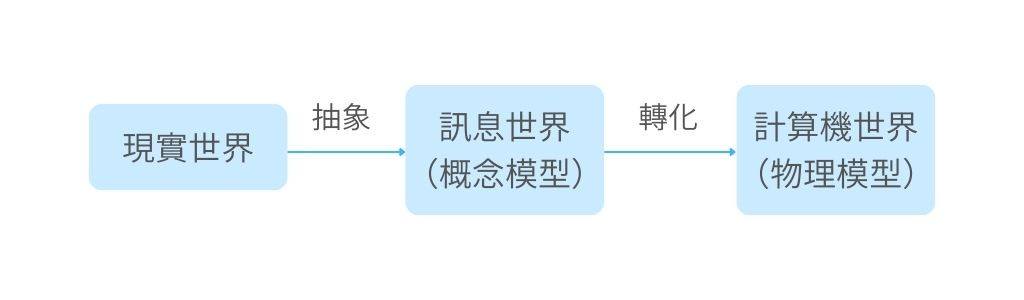
更具體的說,數據模型是對數據、數據關係、數據語義和數據約束的抽象描述和組織。它爲數據的結構化提供了一個框架,並確定了數據如何存儲、組織和處理。數據模型可以幫助確保數據的完整性、準確性和可用性。數據模型可以分爲不同的級別或類型,包括概念數據模型、概念邏輯模型及物理數據模型。下面是反映運營商業務的概念模型。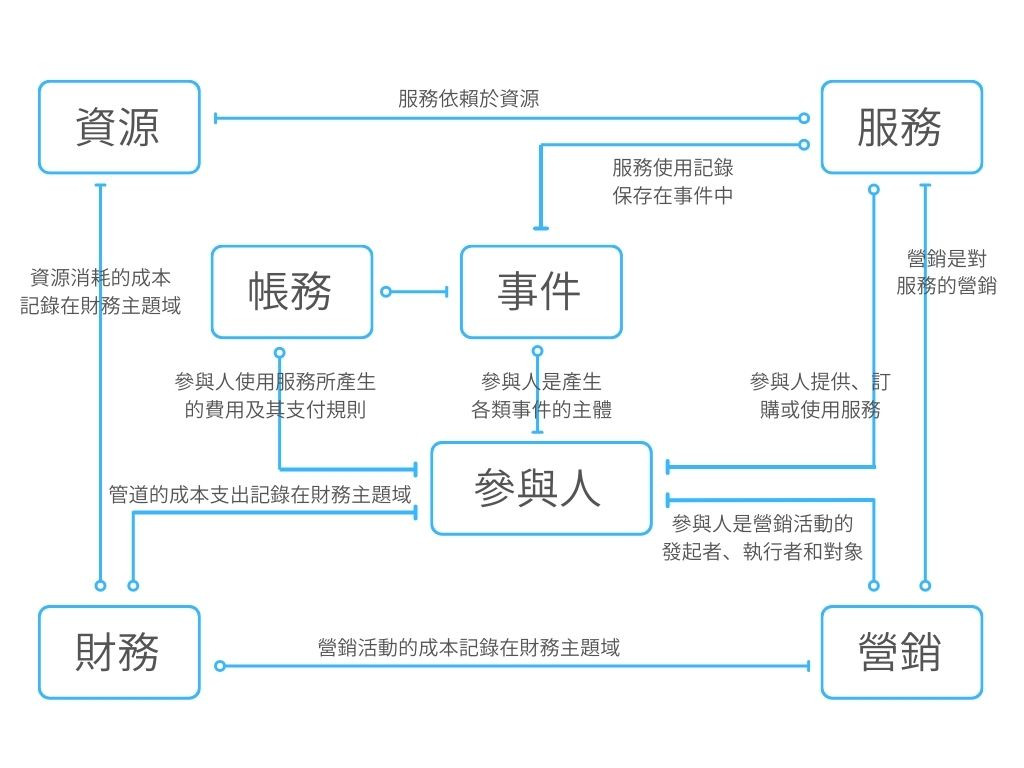
機器學習模型也是對某種現象或數據的描述和抽象,與一般的基於某種理論、原則或經驗建立的模型不同,機器學習模型通過利用數據進行訓練得到某種數學結構,它旨在捕捉和代表數據間的模式或關係,以便對新的、未見過的數據進行預測或決策,它的關鍵點在於:
邏輯迴歸模型的一個示例:
邏輯迴歸模型通常是通過一組特徵權重來定義的。它在某些軟件或庫中可能會保存爲特定格式的文件,例如在Python的scikit-learn中,可以使用joblib庫來保存模型。在更廣泛的範圍內,邏輯迴歸模型可以簡單地表示爲一個權重向量。假設我們有一個模型,用於根據兩個特徵(例如年齡和薪水)來預測一個人是否會購買某產品。我們的模型文件內容可能有以下結構:
Model: Logistic Regression
w1: 0.05
w2: -0.03
b: 2
w1對應年齡的權重,w2對應薪水的權重,b代表偏置,通過這些參數就可以基於輸入的數據進行預測了。但在真實環境中,這個文件會包含更多的元數據和附加信息,並且通常會以二進制或特定格式保存,以方便快速加載和使用。
決策樹模型的一個範例:
下面示例了一個鳶尾花數據集上訓練的決策樹模型,這個模型以二進制文件的形式存儲,我將它轉化成了文本描述,如下: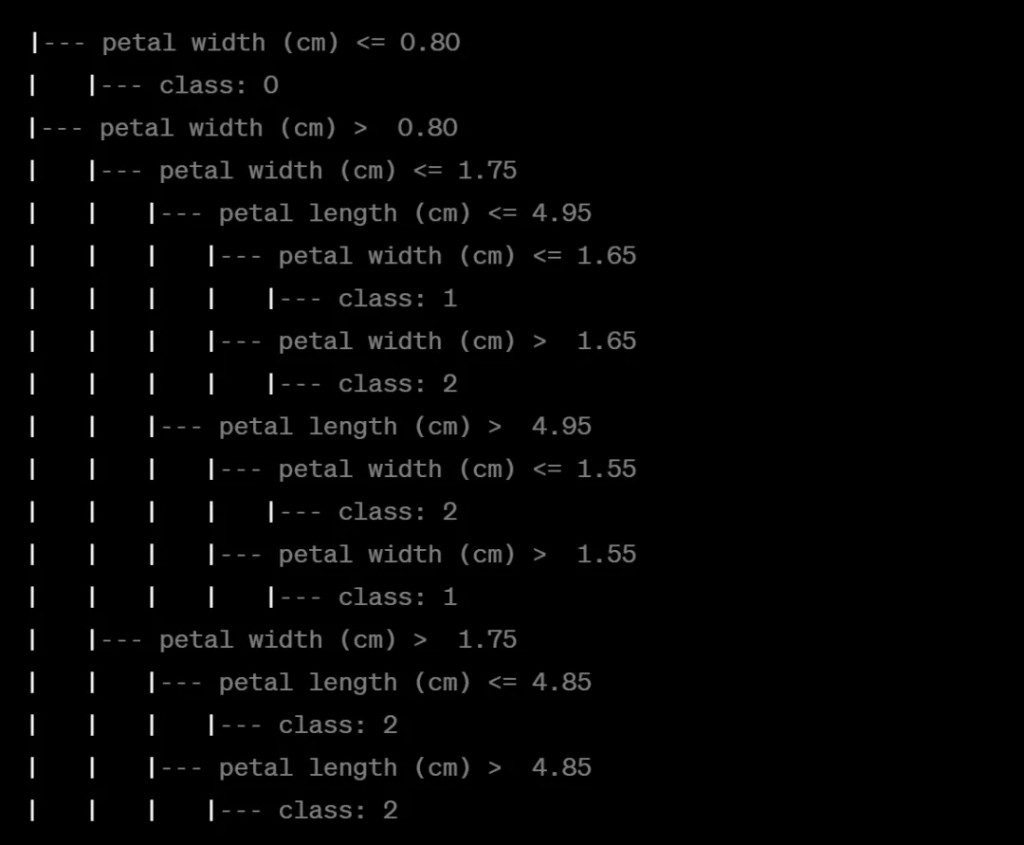
可以看到,決策樹首先查看”petal width (cm)”特徵。如果其值小於或等於0.80,則該樣本屬於類0。如果大於0.80,它將進一步檢查該特徵與其他特徵的值來決定樣本的類別。
模型結構,通常在機器學習和深度學習的上下文中提及,指的是模型的設計或框架,它定義了模型的核心組件以及它們是如何相互連接的。模型結構包括模型的各個層、節點、權重、連接等元素,以及它們的佈局和組織。
以下是對模型結構的一些進一步解釋:
模型結構提供了模型的概覽,併爲模型的訓練和應用提供了框架。一旦定義了模型結構,您可以使用數據和算法來“訓練”模型,即找到模型參數的最優值。以下是一些常用的模型結構:
線性迴歸(Linear Regression)
邏輯迴歸(Logistic Regression)
K最近鄰(K-Nearest Neighbors, K-NN)
決策樹(Decision Trees)
隨機森林(Random Forests)
梯度提升樹(Gradient Boosting Trees)
線性支持向量機(Linear Support Vector Machines, SVM)
非線性支持向量機(Non-linear SVM)
Bagging
Boosting(例如:AdaBoost,GBM,XGBoost, LightGBM)
多層感知機(Multilayer Perceptrons, MLP)
卷積神經網絡(Convolutional Neural Networks, CNN)
循環神經網絡(Recurrent Neural Networks, RNN)
長短時記憶網絡(Long Short-Term Memory, LSTM)
Transformer Networks
GANs(生成對抗網絡, Generative Adversarial Networks)
樸素貝葉斯(Naive Bayes)
高斯過程(Gaussian Processes)
K-means
高斯混合模型(Gaussian Mixture Model, GMM)
DBSCAN
主成分分析(Principal Component Analysis, PCA)
t-SNE (t-distributed Stochastic Neighbor Embedding)
強化學習模型(Reinforcement Learning Models)
時間序列模型(例如:ARIMA,Prophet)
關聯規則學習模型(例如:Apriori,FP-Growth)
這些模型結構具有不同的應用領域和優勢。例如,CNN通常用於圖像處理任務,RNN和LSTM常用於序列數據如時間序列和自然語言處理任務,決策樹和其集成版本(如隨機森林)則在許多分類和迴歸任務中表現良好。
選擇哪種模型結構通常取決於問題的性質(例如,是分類、迴歸、聚類還是其他類型的問題),數據的類型(例如,是表格數據、圖像、文本還是序列數據)以及項目的需求(例如,解釋性、實時性、準確性等)。
在機器學習中,訓練是一個核心概念,指的是利用數據來“教”機器學習模型,從而使模型能夠爲特定的任務做出預測或決策的過程。
以下是訓練的詳細解釋:
簡而言之,訓練就是使用數據來“教”模型,使其能夠根據輸入做出有意義的預測。這通常通過調整模型的參數來實現,直到模型在訓練數據上的性能達到滿意的水平。
從前面的定義可知,在機器學習中,算法是一種過程或方法,用於從數據中學習模式,而模型是這種學習的結果,它封裝了從數據中學到的知識,也是後期用於推理預測的基礎,是一套推理“規則”,它們的主要區別可以總結如下:
因此,在我們說決策樹這個概念的時候,到底是指算法和模型,其實取決於上下文和你想表達的重點:
當我們談論到一個特定的決策樹(例如,一個經過訓練的決策樹,用於分類某種數據),我們通常是在將其視爲一個模型。這個模型可以對新的數據進行預測或分類。
這種意義下的決策樹是一個表示決策規則和路徑的結構。
當我們談論如何從數據中構建決策樹時,我們是在描述一個算法過程。例如,ID3、C4.5和CART等都是決策樹學習的算法。
這些算法爲如何根據數據集選擇合適的特徵、如何進行分裂、以及如何構造樹提供了明確的步驟。
因此,決策樹既可以被認爲是一種模型(當描述其代表的決策規則時)也可以被認爲是算法(當描述如何從數據中構建決策樹時),一般來講,我們說決策樹模型的時候,如果沒有特別指定,應該指的是決策樹模型結構,如果有實例,那一般指用決策樹算法實現的某個具體的業務模型,比如鳶尾花決策樹模型。而當我們在說決策樹算法的時候,除非特別指明,往往是指決策樹的算法集,包括ID3、C4.5、CART等等。
從模型視角看,模型是算法的輸出和訓練過程的產物。算法定義瞭如何從數據中更新模型的參數,而訓練則是這一過程的實際執行。從算法視角看,算法是訓練模型的指導策略。通過不斷地調整模型的參數,算法努力使模型更好地擬合訓練數據。從訓練視角看,訓練使用某種算法作爲指導,根據訓練數據調整模型的參數。訓練結束後,我們獲得了一個調整過的、用於預測或分類的模型。
讓我們以一個常見的例子來說明:手寫數字識別(例如,識別0–9的手寫數字)進行說明。
1. 選擇或設計模型結構
2、選擇一個算法來調整模型的參數
3、開始訓練過程
使用MNIST數據集(一個手寫數字的標準數據集),我們將每個手寫數字圖片的像素值輸入到我們的CNN模型中。
在訓練過程中,算法(例如Adam)反覆調整模型的權重和偏置,使其更好地擬合訓練數據。
經過這三個步驟後,我們就有了一個訓練好的CNN模型,可以用於識別新的手寫數字圖片。
最後,讓我們回到前面提出的問題,支持向量機到底是是指什麼?
這其實是要看上下文的。當你想表達”試圖找到一個超平面(在高維空間中)來分割數據,使得該超平面到兩個類別的距離(即間隔)最大化“這個意思的時候,它是指SVM模型。當你想表達”爲了找到這個最優的超平面,需要解決一個凸優化問題,通常使用例如序列最小優化(SMO)算法“這個意思的時候,它是指SVM算法。當我們沒有特指,僅僅說“使用SVM”時,通常意味着我們使用了SVM定義的模型(最大間隔超平面)以及與之相關的優化算法(如SMO)來進行訓練。
看到這裡,相信你已經對「模型、算法、模型結構、數據模型、訓練」之間的差異有更清晰的概念了。這些基礎名詞不只是用在 AI 技術本身,在企業實務中也與日常資料分析、報表自動化與商業決策密切相關。
如果你想更進一步了解 AI 如何真正落地在企業中的資料分析流程,或想看看目前市場上有哪些工具能把「模型 × 數據 × 實際應用」串起來,推薦你延伸閱讀:
ChatBI:讓企業以對話方式完成資料分析的 AI × BI 工具
 groots
groots

 iThome鐵人賽
iThome鐵人賽