這篇文章紀錄了解決軟體工程師常見的「中英夾雜」語音輸入痛點的過程。 專案架構從單純的 API 串接,演進為 「Code + Prompt + 條件式修復 LLM」的三層架構 。本文將探討如何利用確定性程式碼 (Deterministic Code) 來輔助不確定性的 LLM,在成本、速度與品質之間取得最佳平衡,並包含實際的錯誤率分析與架構決策 。
也邀請大家協助我累積真實數據來優化這個開源專案 👉 立即試用晶晶體
本文原載於 Medium,若是對 AI Engineering 與 Agentic AI 開發有興趣,歡迎關注 我的 Medium 以獲得最新文章。
身為軟體工程師,我在與 AI 協作開發時,「中英夾雜」的溝通是常態。然而,當我試圖實現「用講的寫 Code」時,結果往往不如預期,例如我對著電腦講了這句話:
“Backend transcribe 這支 API 的 Response Schema 需要調整。”
結果,市面上的語音轉文字工具(Siri、Whisper 甚至是 Gemini)卻給了我這樣的災難現場:
“杯墊 transcribe 這支 API 的回應斯基馬需要調整。”
在中英夾雜的語音輸入情境中,多數工具(如 Siri、Gemini、Cursor 內建工具、SuperWhisper… 等)普遍存在兩個問題 :
在我的測試與使用經驗中,ChatGPT 的語音輸入功能最能保留「中英夾雜」的文字,不過有以下的問題:
與 AI 協作的過程我經常需要給予較詳盡的 Context ,若可以將一個保留中英文的語音輸入工具整合進我的工作流,將大幅提升我的工作效率,因此我決定利用 OpenAI API,動手做我的第一個迷你 Agentic AI Workflow 練習專案。
我將它命名為「晶晶體」—— 這個詞原先帶有貶義,用來形容那些說話中英夾雜、聽起來有點做作的風格。但在這裡,它精確地描述了我要處理的問題。
最初,我使用 gpt-4o-mini-transcribe 這個專門的 Speech-to-Text 模型,搭配一段簡單的 Prompt,透過 FastAPI 做出 API:
@app.post("/transcribe")
async def convert_audio_to_text(
audio_file: Annotated[UploadFile, File()],
openai_api_key: Annotated[str, Form()],
model_name: Annotated[ModelName, Form()],
):
client = AsyncOpenAI(api_key=openai_api_key)
response = await client.audio.transcriptions.create(
model=model_name.value,
file=(audio_file.filename, audio_file.file),
prompt="""語音中的中文語句可能夾雜英文,
保留英文部分不需翻譯直接轉換為英文文字,
中文部分用台灣使用的繁體中文呈現。
中英交錯時英文開始前與結束後應各加上一個空格,例如“這是 Speech to Text 工具”。
應加上合適的標點符號。""",
)
transcript = response.text
return {"transcript": transcript}
用 Next.js 做出一個方便我自己使用的 UI:
圖:晶晶體的簡易 Web 介面,可錄音或上傳音檔,轉錄後可再編輯文字結果。
透過簡單的 Prompt 與 API 串接加上前端介面,我得到了一個轉錄結果優於 ChatGPT 語音輸入工具:
然而雖然 AI 能夠聽懂並轉錄出文字,但對於「人類閱讀」來說,體驗非常糟糕,主要有三個問題 :
雖然把目前品質的轉錄結果直接丟給 AI 作為 Context ,AI 完全能夠閱讀理解我的原意,但是如果我想要自己先讀過或是稍作修正再丟給 AI,那麼目前的品質常常是難以閱讀的。
我最近開始上 Andrew Ng 的 Agentic AI 和 Google 的 5-day AI Agents Intensive 課程,兩者都極度強調 Quality(品質)的重要性,於是我開始思考如何優化我的晶晶體的 Response Quality。
目前的品質:
我正在學RAG然後現在教到那個embedding model它的用途是將text轉成vector表示
希望達到的品質:
我正在學 RAG,然後現在教到那個 embedding model,它的用途是將 text 轉成 vector 表示。
一開始思考如何解決上述品質問題時,我參考了 Andrew Ng 在 Agentic AI 課程中的觀點:
「有時候,品質問題不一定只能靠 LLM 解決,用傳統的 Code 處理反而更有效。」課程中舉例:一個客服 AI Agent 在回覆客戶 Email 時,可能會夾帶攻擊競爭對手的言論(例如:「沒問題,我們不像 XX 公司,我們的退款手續非常簡單」)。這時可以做的是用 Code 寫一個 Post-processing:明確列出競爭對手的名稱列表,用
string.include()檢查 AI 的回應。
LLM 擅長處理邏輯規則較為抽象的任務,但對於「加空格」或「簡繁轉換」這種邏輯固定的任務,傳統程式碼(Deterministic Code)不僅成本低,而且 100% 準確 。
我將這兩項任務從 LLM 的職責中剝離:
使用 Regular Expression 替中英文、數字交界處加上空格 :
def add_spacing_between_chinese_english(text: str) -> str:
# Pattern 1: Chinese followed by English/numbers
text = re.sub(r"([\u4e00-\u9fa5])([a-zA-Z0-9])", r"\1 \2", text)
# Pattern 2: English/numbers followed by Chinese
text = re.sub(r"([a-zA-Z0-9])([\u4e00-\u9fa5])", r"\1 \2", text)
# Pattern 3: English punctuation marks followed by Chinese
text = re.sub(r"([.,!?;:)\]}'\"])([\u4e00-\u9fa5])", r"\1 \2", text)
return text
使用 zhconv 套件,透過預先建立好的簡繁體 dictionary 對照,完整處理繁簡轉換,確保每次轉錄結果都以繁體輸出 。
將這些「雜事」交給 Code 後,LLM 就能更專注在它需要處理的非確定性難題 —— 標點符號與語意斷句。
解決了格式問題,我回頭進行 Prompt 的迭代,透過兩個方向的調整更優化 LLM Response 品質:
我把要求「加上標點符號」的 Prompt 寫得更具體,明確要求「依據語氣和語意,使用合適的標點符號,使斷句恰當容易閱讀」。
單純要 LLM 處理中英夾雜不做翻譯的 Prompt,仍會導致一整句英文(如 “Does it work?” 被翻譯成中文 ”它能運作嗎?” )。
我用 Few-Shot Prompting 技巧,在 Prompt 中給予了幾個關鍵範例:
Audio: "這個 test"-> "這個 test" (展示了單詞的保留)
Audio: "Okay, let's start the meeting." -> 輸出: "Okay, let's start the meeting." (展示了完整英文句子的保留)
Audio: "我們開始吧" -> 輸出: "我們開始吧。" (展示了中文的正常輸出)
Few-Shot Prompting 的效果非常好,後續測試都沒有再明顯出錯。
在我優化了 Prompt 之後,轉錄品質明顯提升了。但是,我發現它仍然會隨機產生完全沒有標點符號的結果,這引出了兩個架構調整方案:
架構 A(更換為通用模型)
改用 gpt-4o-mini 通用模型。對於通用模型來說,寫出斷句順暢標點恰當的語句很容易,加上多模態的特性,有可能可以一次搞定轉錄與標點符號;缺點是通用模型 Speech-to-Text 的能力沒經過特別調校,可能對語音掌握較弱,且成本與延遲可能較高 。
架構 B(專用模型 + LLM 修復)
維持 Speech-to-Text 專用模型 gpt-4o-mini-transcribe,但在「錯誤」時觸發第二次 LLM 呼叫來修補 。
我將「轉錄結果完全沒有標點符號,或標點比例過低缺乏斷句」視為一次錯誤 。
在測試中,我發現錯誤率雖然與音檔長度有關(長音檔較易失敗),但更明顯的特徵是連續性。如果品質不好,它往往會「連續」不好一段時間(例如 10-20 分鐘)。我推測這可能與系統當下的資源調配與負載平衡有關 。
經過數十次的測試,我得到的結果是錯誤率約為 1/4 。這意味著如果選擇專用模型 + Fallback LLM,我有 75% 的請求能享受專用模型的快速與低成本,只在少數情況需付出額外代價。因此,我決定採用架構 B 。
在決定架構後我開始思考該如何實作這個機制,循著 Agentic AI 課程中的 Research Agent 的 Workflow 範例(Draft → Review → Revise),最直覺的對應作法是:Transcribe (LLM 1) → Review Quality (LLM 2) → Fix (LLM 3)。但這樣成本太高,Review 和 Fix 都是 Roundtrip。
於是我思考:能不能用單純的「Code」來取代 LLM 2 完成品質檢查?
我觀察分析那些被我判定為「錯誤」的轉錄結果,發現可以透過檢測標點符號的頻率與位置,來判斷轉錄結果的斷句是否「健康」(是否易於閱讀):
短句豁免
若總字數非常少( < 10 字),直接通過,因為短句本來就可能不需要標點。
結尾檢查
檢查最後一個字元是否為合法的結尾標點(如 。, ,, ?, 、, .)。若否,判定為不健康。
標點比例檢查(核心規則)
計算 總字數 / 標點總數 的比例。若比例高於特定 Threshold ,代表句子過長未斷句,判定為不健康。(註:Threshold 的訂定涉及 Observability,將於另篇文章探討)。
品質法官檢驗
針對已經過 code 做 post-processed 的文字,以上述規則定義的 function 來判斷是否健康,免除用 LLM 來做 Quality Review 會造成的延遲與費用。
條件式 LLM 修復
只有當法官判定不健康時,才觸發 gpt-4o-mini 進行修復,依照先前錯誤率的統計,約 1/4 的轉錄,會需要經過通用 LLM 再次修復,Prompt 要求 「依據語意和上下文加上通順標點」,並嚴格限制「不修改原文任何字詞」。
在實作條件式 LLM 修復機制的過程中,我發現通用 LLM 其實可以是個很好的編輯,若不嚴禁它修改任何文字,它除了修復標點符號以外,會順手修掉口語贅字,不可否認修掉 誒…、 那個… 這樣的贅字似乎很加分,這讓我陷入了新的兩難:我該追求「忠實度 (Fidelity)」還是「精煉度 (Refinement)」?
身為前端工程師,我決定將這個選擇權交給使用者,設計了三種模式 :
Speedy (速度模式):
Standard (標準模式 - 預設):
Refined (潤稿模式):
這個三模式的設計,把一個棘手的「主觀品質」兩難,轉化成了一個清晰、由使用者情境驅動的「產品選項」。
優化後的 Agentic AI Workflow,結合 Code 與條件式二次 LLM ,包含了三種使用者模式:
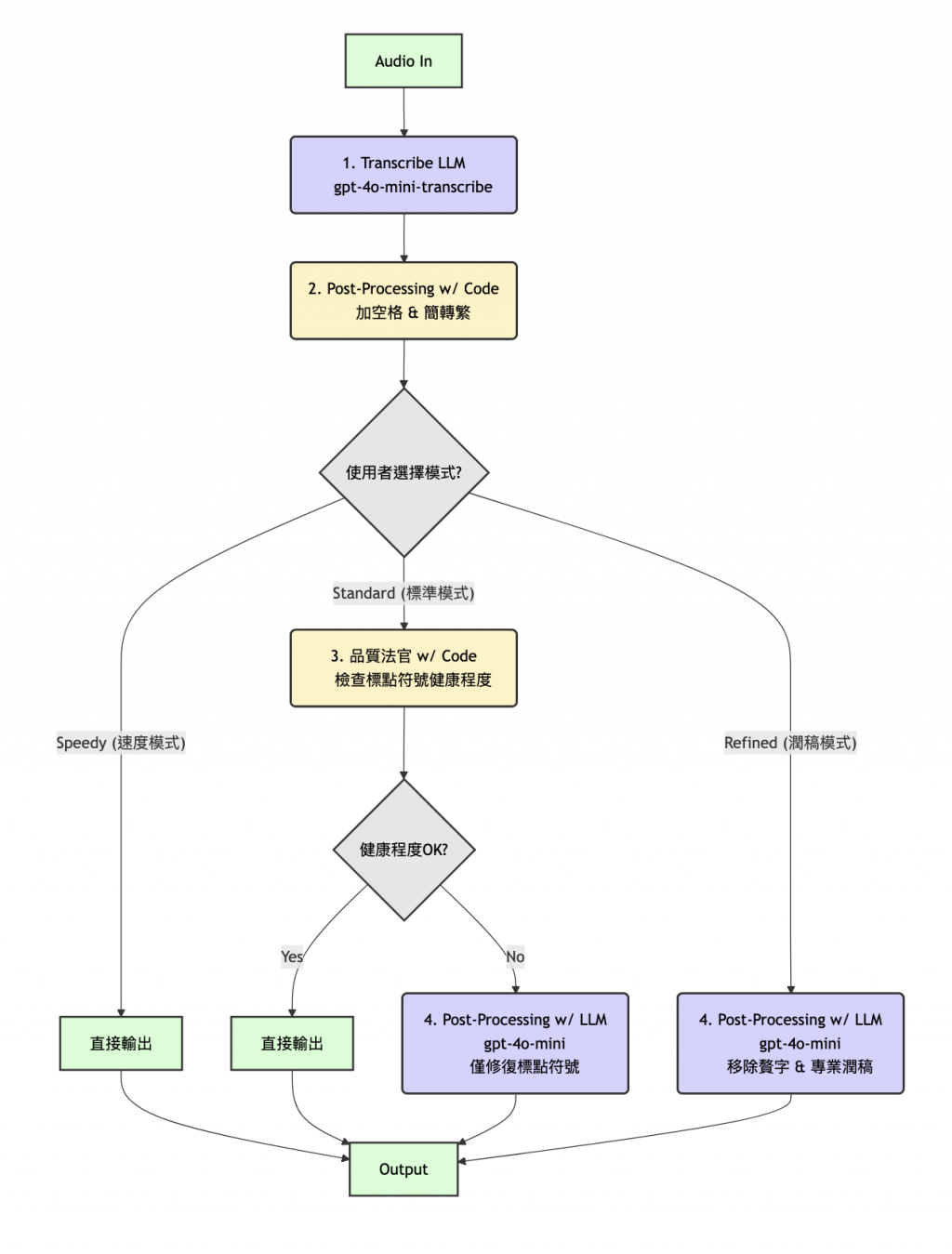
圖:結合 Code 與條件式 LLM 修復、三種使用模式的 Agentic AI Workflow
透過實戰,從單純的串接 Speech-to-Text API 到發展出這個架構,是一個非常有收穫的過程,它讓我更知道怎麼像個務實的工程師去做取捨,也把課堂上學到的抽象概念,真正在一個具體的場景中實踐出來。
在整個過程中,我深刻體會到 AI Engineering 的「成本效益考量」,以及在不同優化階段的「出手」時機。
這次的品質優化過程,經歷數次成本效益的權衡取捨,整合成最後的 Pipeline。
由於 AI 的回應有隨機性,為了評估優化效果,改動後我時常需要做 10-20 次測試才能統計出錯誤率的變化,並研判品質是否有所提升。
這讓我體會到兩個在課堂與書本上學到、但直到現在才真正體會其重要性的主題:
建立一套有效的測試集(例如 20 個在不同地方容易產生錯誤的錄音檔)、 Evaluation 標準,用客觀數據來衡量品質變化(例如「失敗率從 20% 降到 10%」、在長音檔的標點符號錯誤率降低 25 %),而不是「憑感覺」。
有了 Tracing、Monitoring,觀測每個 Response 的延遲、花費,分析轉錄結果(未修復 / 修復後)...等等,才能讓我持續監控與優化品質。
目前「晶晶體」已經正式上線,並且有免費版可以使用。我誠摯邀請各位開始在真實情境中使用它 — — 無論撰寫文字訊息、與 AI 協作、或快速筆記。您的每一次使用,都能幫助我累積有效的 Golden Dataset,練習建立評估流程,並透過這個迷你專案,分享更多實作一個基本 Agentic AI System 的各個環節。
👉 立即試用晶晶體
轉錄品質真的不錯,可以語音輸入跟 AI 對話真的很方便耶,打字中英切換真的好麻煩哈哈
不過剛剛試著上傳長音檔好像只會轉錄大約前面的15分鐘的內容~ ,
,
但還是謝謝你的分享~
長音檔轉錄在某個時長以後表現不理想,是因為 Timestamp Shift 的關係,這是 Speech-to-Text LLM model 的限制,因為這個專案一開始設定的主要用途是語音輸入,所以我沒有優先處理這個問題。
接下來我會透過 Chunking 的方式解決長音檔品質不佳的問題,到時也會把開發經驗分享上來~
謝謝你給我使用上的回饋,有發現什麼其他問題也都歡迎提出喔~
感謝你嘗試使用它,讓我獲得寶貴的真實使用者數據!
 dong_wyt
dong_wyt

 iThome鐵人賽
iThome鐵人賽