
💡 晚上 10 點的告警,從手動查詢 2 小時到 AI 協作 15 分鐘,這是我的真實經歷。
上週四 22:15,我正準備睡覺,手機開始Alert。
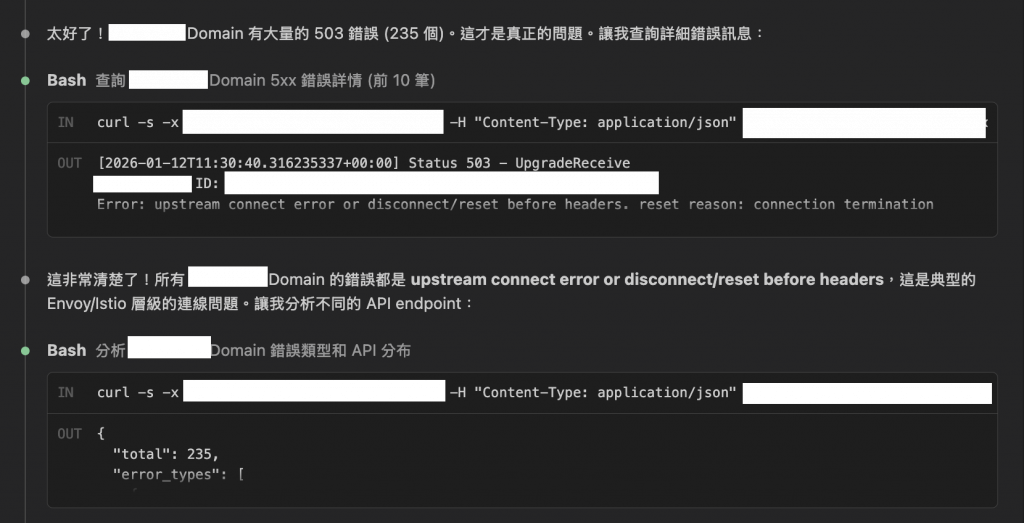
又是告警。
這次是 API 5xx 錯誤率過高。
以前遇到這種情況,我的標準流程是:
光是「找到問題」就要一個多小時。
然後才開始修。
然後還要寫 Incident Report。
總共:至少 2 小時起跳。
但這次不一樣...
這次,我打開 Claude,15 分鐘就定位到問題。
不是我變神了。
而是我換了一種工作方式。
我只是問了幾個問題:
Claude 透過整合的工具,自動幫我:
15 分鐘後,服務恢復。
再 5 分鐘,Incident Report 初稿也有了。
這是我第一次覺得,半夜被Opsgenie叫起來不是那麼痛苦。
如果你不是 SRE,可能會好奇我們平常在做什麼。
簡單來說,我們的工作就是:
聽起來很厲害?
實際上,很多時候我們在做的是:
❌ 半夜被告警吵醒,頭腦不清楚
❌ 登入 10 個不同系統查資料
❌ 翻找幾個月前的 Incident 記錄
❌ 寫 Incident Report 又花 5 小時
❌ 同樣的問題一再發生
這些都是「高重複、低產出」的工作。
但偏偏又很重要。
這就是為什麼 AI 對 SRE 這麼有用。
過去半年,我一直在實驗怎麼用 AI 改善工作流程。
發現 AI 至少可以在三個層面幫上忙:
以前:需要登入多個系統
每個系統都有自己的查詢語法。
每次都要重新想「這個要去哪裡查」。
現在:一句話問 Claude
所有資料統一在一個介面查。
而且用自然語言,不用記語法。
AI 不只是「查詢工具」,更像是「分析助手」。
它會主動幫你:
這就像是有一個永遠不會累的 Junior SRE 在幫你。
傳統方式的問題:
AI 驅動的方式:
知識不再散落,而是能被有效利用。
讓我用一個實際案例來說明差異。
03:15 - 收到告警:API 5xx rate > 5%
03:20 - SSH 到機器開始查日誌
03:35 - 發現某個 service 有大量 timeout
03:50 - 打開 Grafana 查看各項指標
04:05 - 發現 database connection pool 使用率異常
04:20 - 去 Confluence 找相關 Runbook
04:35 - 根據 Runbook 執行修復:重啟 connection pool
05:00 - 服務恢復
05:30 - 寫完 Incident Report
總耗時:2 小時 15 分鐘
這還算順利的。
如果 Runbook 找不到,或是根因不明確,可能要花更久。
03:15 - 收到告警:API 5xx rate > 5%
03:17 - 問 Claude:「查詢過去 30 分鐘的錯誤日誌」
03:18 - Claude 透過 OpenSearch MCP 找出關鍵錯誤
03:20 - 問:「這個錯誤以前有發生過嗎?」
03:21 - Claude 從 Jira 找到類似 Incident:PROJ-4567
03:23 - 問:「上次是怎麼修的?」
03:25 - Claude 從 Confluence 找到解法:重啟 connection pool
03:27 - 執行修復
03:30 - 服務恢復
03:35 - Claude 自動產生 Incident Report 初稿
總耗時:20 分鐘
為什麼能這麼快?
關鍵不是 AI 比你聰明。
而是它能同時做很多事:
而且記憶力完美,不會忘記上次怎麼修的。
更重要的是,它不會因為是凌晨 3 點而頭腦不清楚。
| 傳統方式 | AI 協作 |
|---|---|
| 手動登入多個系統 | 一個介面統一查詢 |
| 靠經驗與記憶 | AI 快速檢索歷史 |
| 重複性手工勞動 | 自動化與智慧建議 |
| 知識散落各處 | 統一知識庫 |
| 每次都要重新思考 | AI 記住所有經驗 |
你可能會問:「這聽起來很神奇,但技術上是怎麼做到的?」
核心是:Claude + MCP (Model Context Protocol)
用一個比喻來說,就像是給 AI 接上「各種工具的 USB 線」。
本來 AI 只能「聊天」。
現在有了 MCP,它能:
就像你會用滑鼠、鍵盤操作電腦。
AI 透過 MCP 操作這些工具。
而且這些 MCP Server 大多是開源的。
社群已經幫你寫好了。
最棒的是,你不需要寫複雜的整合Coding。
只要:
就這麼簡單。
我自己第一次設定 OpenSearch MCP,大概花了 30 分鐘。
主要時間是在找 API Token 放在哪裡。
技術架構圖大概是這樣:
你 → Claude → MCP Protocol → OpenSearch MCP → OpenSearch
→ Jira MCP → Jira
→ Confluence MCP → Confluence
→ ...更多工具
你只需要跟 Claude 對話。
Claude 會自動判斷要呼叫哪個 MCP。
在開始用之前,我自己也有很多疑問。
這裡分享一些我最常被問的問題:
看情況,但我是覺得他似乎變成我的必需品。
Claude Pro 個人版:
企業版:
我自己的經驗:
每個月大概花 $30-50 美金
但省下的時間至少值 20 小時
這是最常被問的問題。
我的做法:
日誌先脫敏
查詢前把敏感資訊過濾掉
不傳原始資料給 AI
只傳查詢結果的摘要
企業版有資料保護
Claude Enterprise 不會拿你的資料訓練模型
如果你公司有嚴格的資料政策:
沒關係,可以從小處開始。
就算沒有 OpenSearch MCP,你也可以:
重點不是「全部自動化」
而是「一點一點改善工作流程」
先用起來,再慢慢整合工具。
這是「SRE × AI 實戰系列」的第一篇。
接下來我會寫:
第二篇:完整實戰案例
→ 我如何用 Claude 處理一次真實的 5xx 告警
→ 從頭到尾的工作流程,包含實際截圖
第三篇:OpenSearch 整合
→ 不再手動 grep 日誌
→ 讓 AI 幫你分析錯誤模式
第四篇:Atlassian 整合
→ Jira + Confluence 的自動查詢
→ 知識管理自動化
後面還會有:
→ Mermaid 自動畫圖
→ AWS/GCP 監控整合
→ RCA 自動生成
→ Runbook 智慧化
最後一篇會談談我的想法:
→ 當 AI 成為 On-Call 夥伴
→ SRE 的工作會變成什麼樣子
剛開始用 AI 時,我以為它只是「查詢工具」。
後來發現,它更像是:
最重要的是,它讓我從「救火隊員」變回「工程師」。
我不再花大量時間在重複性查詢上。
有更多時間思考「如何預防」、「如何改善」。
這才是 SRE 該做的事。
如果你也是 SRE,我會建議:
1. 從小處開始
不用一次改變所有工作流程。
先從最常做的查詢開始自動化。
比如:
找到一個「省時又有效」的切入點。
2. 別怕嘗試
AI 不會取代你。
但會用 AI 的人,會過得比較輕鬆。
我自己是在處理一次凌晨 3 點的告警後,決定認真研究 AI 工具。
因為我不想再經歷「查了 2 小時才發現上次遇過」的痛苦。
3. 持續分享
把你的經驗寫下來。
不只幫助別人,也幫助未來的自己。
這個系列就是我的分享。
希望對你也有幫助。
AI 不會取代 SRE。
但會用 AI 的 SRE,可以省下很多時間。
然後把時間拿去做更有價值的事。
或是早點下班(有可能嗎?),這也很有價值
下一篇,我會分享完整的實戰案例。
手把手教你如何建立這套工作流程。
包含:
如果你對這個主題有興趣,歡迎留言交流!
下一篇預告:《我如何用 Claude 將故障調查時間從 2 小時縮短到 15 分鐘》
本文是「SRE × AI 實戰系列」的第 1 篇,共計 10 篇。
 打雜的花園鰻
打雜的花園鰻

 iThome鐵人賽
iThome鐵人賽