405 Method Not Allowed 錯誤在開發 晶晶體 這個中英夾雜語音轉文字的個人專案時(可參考我的前一篇文章 👉 Agentic AI 開發實戰:我是如何設計 “Code + LLM” 混合架構,解決 AI品質不穩的問題?),我的目標非常明確:專注在練習 Agentic AI Workflow 的設計與實踐、以及對應所需的前後端開發。而 DevOps 並不是我優先想花心力進修的領域,設定 Nginx 反向代理、或是處理 Let’s Encrypt 的 SSL 憑證自動更新,不僅繁瑣,更讓我分心,偏離了鑽研 Agentic AI System 與 AI-based Application 的核心目標。
因此我心中最理想的方案,是一個能像前端的 Vercel 那樣簡單、直覺,最好能直接託管後端服務的平台。
為了找到這個理想的「後端版 Vercel」,我評估了市面上常見的幾個 PaaS (Platform as a Service) 選項,最後選擇 Render 的原因主要基於對「冷啟動」機制與成本的考量:
Render 的 Free Tier 有一個機制叫 Inactive Spin Down。只要我的 Web Service 在 15 分鐘內沒有流量,系統就會把我的後端 Application Shutdown。
這對我的語音轉文字小工具使用造成了很大的困擾,只要我使用間隔超過 15 分鐘,按下轉錄後 UI 的 Loader 會讓我以為正在轉錄中,實際上後端正在經歷幾十秒的 Startup 過程,而我這個轉錄的 POST Request 從來都沒有被接收到。
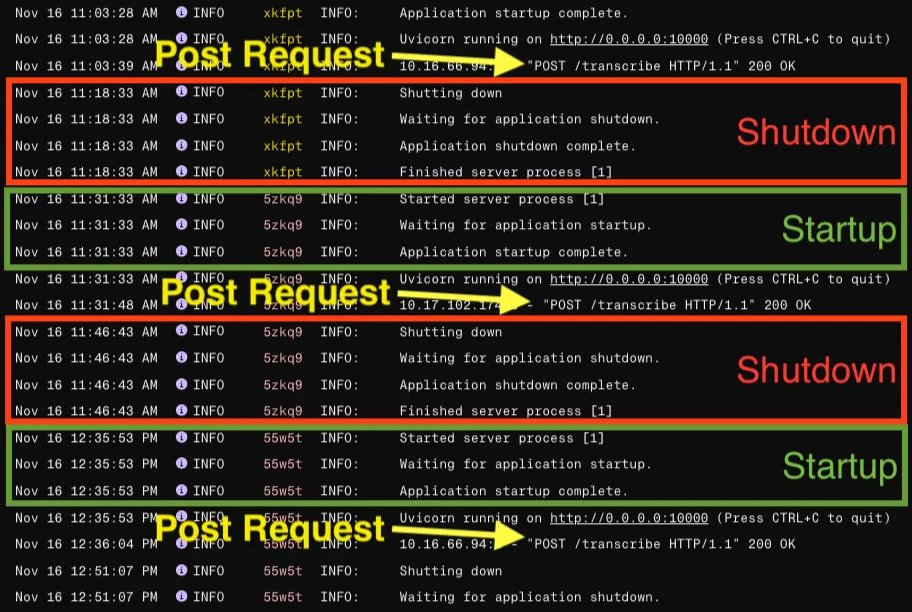
Render Free Tier 的 log,可以看到 service 持續 shutdown 再 startup。
看著 Log 裡滿滿的 Shutdown / Startup 紀錄,我意識到必須解決這個問題,否則這個小工具根本沒法順暢使用。
「既然 15 分鐘沒人理會睡著,那我就假裝一直有人在使用它?」 要實現這個想法,我不能直接定時去 Call 那個昂貴又耗時的「語音轉文字」API。於是我在後端(FastAPI)另外寫了一個 API /livez,這個 endpoint 只回傳簡單的 JSON,專門用來讓外部服務 Ping 一下,確認服務還活著。
一開始我使用了 Render 提供的 Cron Job 功能。我設定了一個排程,讓它每 5 分鐘執行一次 curl 指令去對我的 /livez 發一個 GET Request。
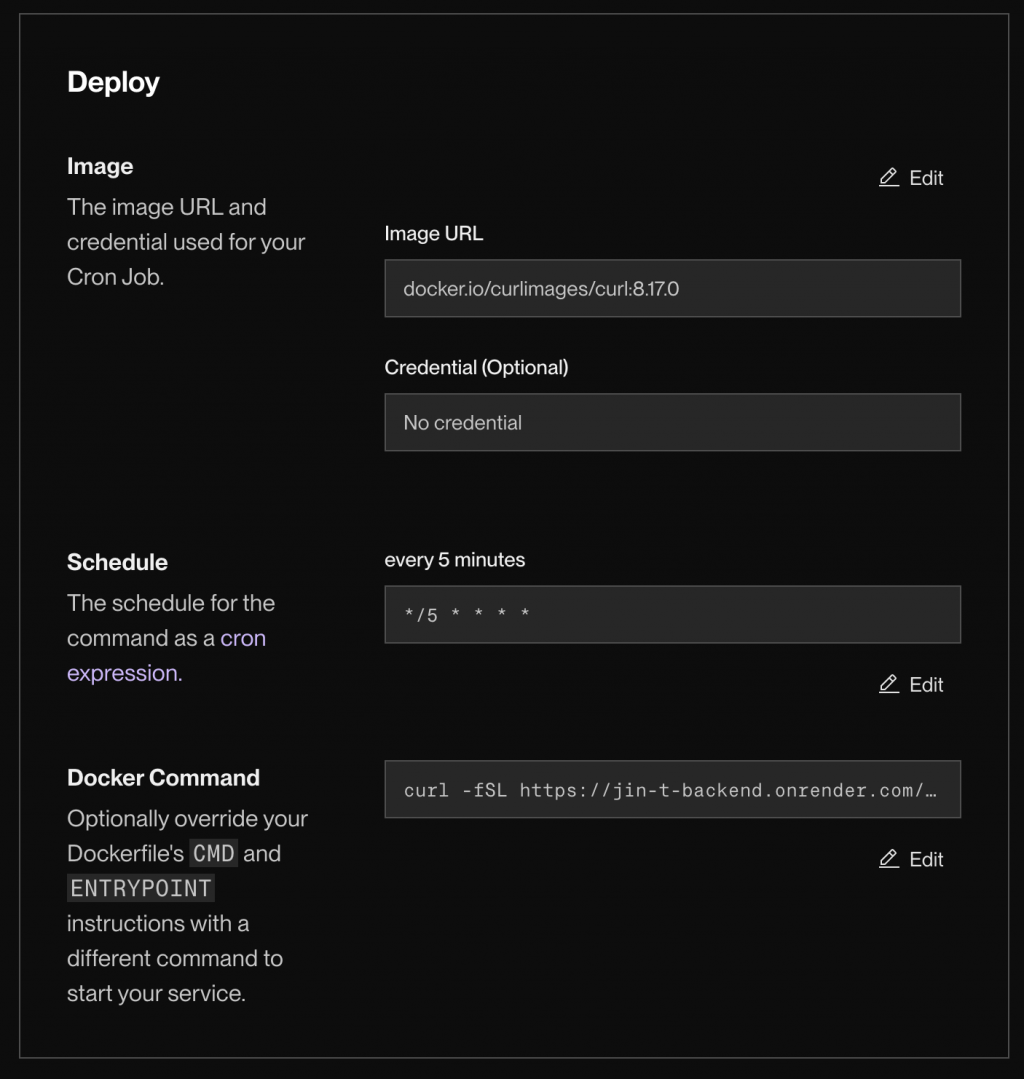
Render 上做的 cron job 設定
實驗結果證明,這個方法在技術上完全可行!服務真的沒有再休眠過。 但問題來了:Render Cron Job 起跳規格即為 0.5 CPU 與 512 MB RAM,每月需 6 美金。這對單純發送 GET Request 來說完全是殺雞焉用牛刀(Overkill),更違背了我「零成本部署」的初衷,所以我決定尋找替代方案。
為了尋求免費解法,我找到了 UptimeRobot。
UptimeRobot 是一個專門用來監控網站狀態的服務。它的主要功能是持續檢查你的網站是否正常運作(UP),如果發現網站掛了(DOWN),它能夠即時透過 Email 發送警報通知你,也提供了 Dashboard 讓你隨時查看網站的 Uptime 百分比統計,以及具體的 Error Log。
雖然它本質上是一個「監控工具」,但我可以利用它監控時固定頻率發出 Request,來達成 Keep Alive 的目的。 這樣我不僅解決了休眠問題,還額外獲得了一個免費的網站健康監控服務。
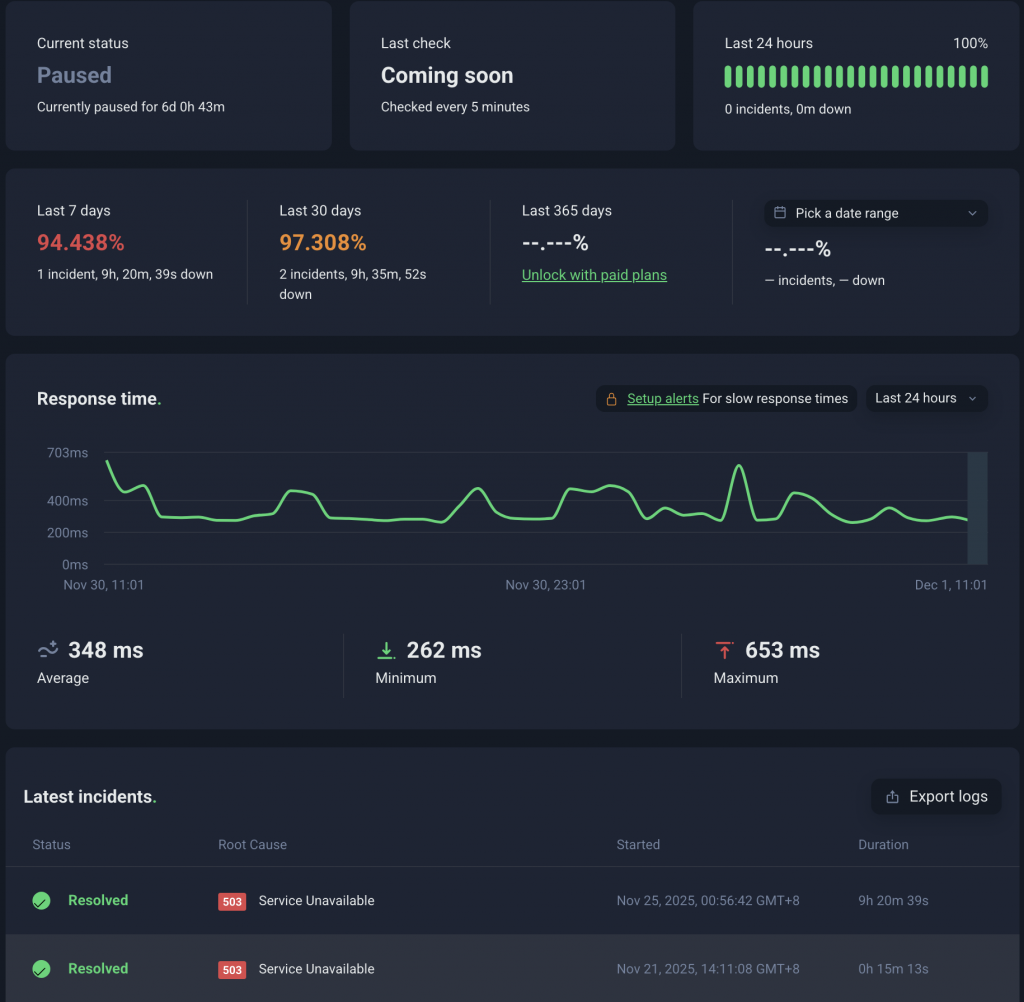
UptimeRobot 的 Dashboard
而且 UptimeRobot 的使用非常簡單,只要:註冊帳號 ⇒ Add New Monitor(Type 選 HTTPS)⇒ 填入要監控狀態的 URL (.../livez) 、設定檢查頻率。
但在這裡我踩到了一個技術性小坑。
設定好 UptimeRobot 後,我回去看 Backend 的 Log,發現雖然服務沒有 Shutdown 了,但紀錄全是紅字的 405 Method Not Allowed。

從 Cron Job 改成 UptimeRobot 的 Backend Service Log
經過排查發現,這只是一個 HTTP Method 的對應問題:
/livez API: 接收 GET Request。所以我只需要修改一下 FastAPI 的程式碼,讓 /livez 這個 endpoint 同時接受 GET、HEAD 兩種 Request Method 就可以了。
用 api_route 指定 methods :
from fastapi import FastAPI, Response
app = FastAPI()
# 同時允許 GET / HEAD
# GET:方便我自己在瀏覽器打開看 JSON
# HEAD:UptimeRobot Free Plan 預設會用 HEAD 來發出健康檢查請求
@app.api_route("/livez", methods=["GET", "HEAD"])
async def live_check(response: Response):
# 回傳一個簡單的 header,順便確保 FastAPI 有正常組出 Response
response.headers["X-Status"] = "Alive"
# Body 內容只會在 GET 請求時回傳,HEAD 會自動只回 header(這是 HTTP 的預期行為)
return {"status": "ok"}
改完部署上去後,Log 裡的 405 錯誤消失了,取而代之的是穩定的 200 OK,服務也終於達成了 24 小時在線。
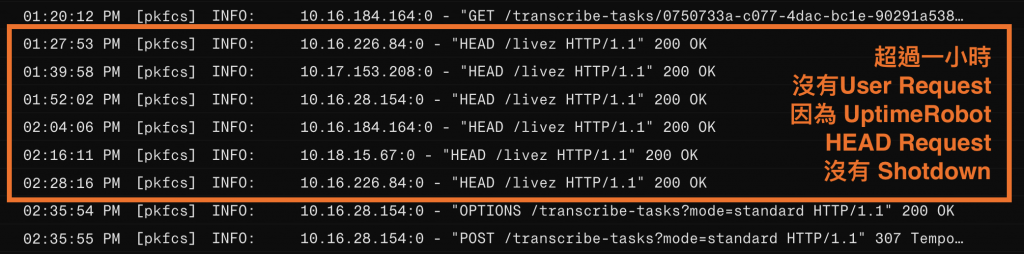
穩定 200 OK 的 UptimeRobot HEAD Request 讓後端服務永遠保持 Active
雖然「Render + UptimeRobot」成功以零成本解決了冷啟動問題,但這畢竟屬於「非常規」的變通手段。在採用前,有幾點限制與取捨必須誠實面對:
1. 避免濫用與合規意識
這套方法本質上是利用外部監控來繞過 Free Tier 的休眠機制。建議大家將此視為學習階段或 MVP 驗證的「過渡方案」,而非長期的營運架構。使用前請留意平台條款,避免刻意規避限制而違反規範。
2. 監控數據的污染 (Observability Noise)
目前我最有感的代價就是整個 Monitor — — 包含 Application Logs 與 System Metrics — — 都會變髒。就像上面的截圖所示,Log 上會充斥著規律的 Ping 訊號。
雖然我已將間隔調整為 12 分鐘(在滿足 Render 15 分鐘限制下盡量減少頻率),但這些並非真實使用者的流量依然存在。如果專案逐漸成熟,開始需要依賴這些 Metrics 來分析效能或追蹤用戶行為時,這些混入的雜訊就會造成數據失真。
3. 何時該選擇「正規」方案?
如果專案已經具備商業價值,或對穩定性(SLA)有要求,應該要改採正規且負責任的做法:
做完這套設定後,最大的差別其實是「心情」。
現在我要使用功能或是邀請其他使用者試用時,不需要再擔心第一次 Request 會失敗,也不用為此特別在前端設計 Timeout 重試邏輯。Render 幫我處理了 Docker 部署與 SSL,UptimeRobot 幫我處理了冷啟動,而這一切是零成本的。
雖然如前所述,針對商業需求或對 SLA 有嚴格要求的服務,直接付費或自架 Infra 絕對是更正規且穩定的選擇。但回歸到這個個人專案的初衷,我希望將時間專注在 Agentic AI Workflow 與 Full-Stack Application 的設計與開發,而非消耗心力在基礎維運的瑣事上,儘管「Render + UptimeRobot」這個組合看起來像是在拼湊資源,但它成功以「零成本」達成了我的核心需求:
因此,這無疑是我心中目前 CP 值最高的 Docker 部署方案,也是我下一個個人專案會優先採取的方式。當然,如果你有其他推薦的的低成本部署方案,也非常歡迎在留言區分享你的經驗!
這篇文章的初稿,其實就是用我的個人專案「晶晶體」口述生成初稿,在與 AI 協作潤飾產生的。
目前我正在建立 Evaluation 的 Golden Dataset,以練習完成整個 Agentic AI System Lifecycle。如果您剛好有語音轉文字的需求,歡迎試用並貢獻數據。若能收集到足夠樣本,我也會將「實作 AI Agent Evaluation」的過程整理成技術文章分享!
👉 立即試用晶晶體
 dong_wyt
dong_wyt

 iThome鐵人賽
iThome鐵人賽