當任務不再只是人類的心理概念,而成為系統的原生 Primitive。
你有沒有注意到,當你反覆使用 LLM 的時候,會自然而然地開始做一件事整理、保存、重複使用你的 Prompt?
一開始,Prompt 只是一段文字。說完就消失了。
但當你發現某個 Prompt 特別好用,你會開始:
這個瞬間,Prompt 就不再是 Prompt 了。
它變成了一個任務(Task)。
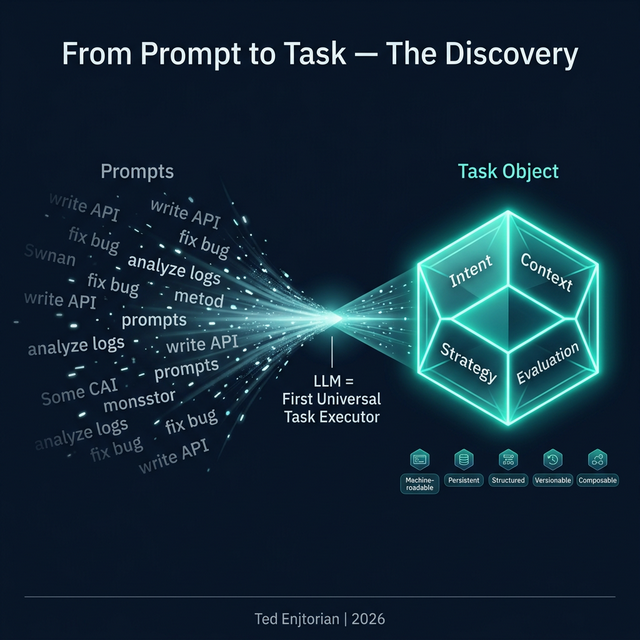
想想看:「幫我分析 API 效能」「幫我寫登入模組」「幫我重構這段程式碼」這些都是任務。但在 LLM 出現以前,它們只能存在於人腦中,或者散落在 Todo List、Slack 訊息、會議記錄裡。
它們是非結構化的心理概念。
沒有人覺得這有什麼問題,因為過去只有人類能夠「執行」任務。人類可以接受模糊指令,自動補全缺失的背景知識。
但 LLM 改變了一切。
在 LLM 出現之前,「執行器」只有兩種:人類,或特定軟體。
現在,LLM 可以執行幾乎任何認知任務:分析、撰寫、規劃、轉換、設計、除錯。不需要針對每個任務寫特定程式碼。
這意味著,任務第一次可以被機器直接讀取與執行。
但前提是任務必須變得結構化。
Task Ontology Kernel(任務本體核心) 解決的就是這個問題。它定義了:
TOK 不是工具,不是系統,也不是框架。它是理論基礎就像 Lambda Calculus 之於程式語言、Relational Model 之於資料庫。
TOK 之於 Task-native 系統,就像 Relational Model 之於關聯式資料庫。
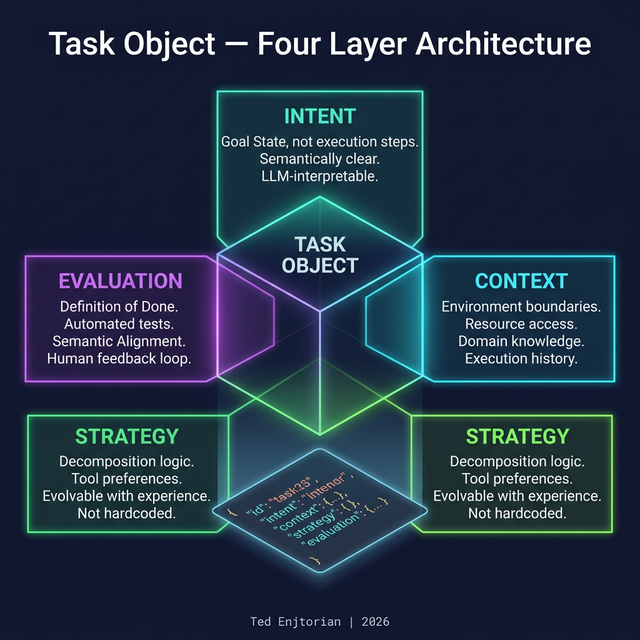
在 TOK 中,每個任務由四個層級組成:
描述「要達成什麼」,不是「怎麼做」。
執行所需的環境、權限、歷史紀錄。
任務分解邏輯與工具偏好。可以隨經驗演化,不是寫死的流程。
任務成功的驗證協議Definition of Done。
看一個具體例子:
{
"id": "task-001",
"intent": "分析 API 執行效能日誌,產生摘要報告",
"context": {
"domain": "backend",
"resources": ["DB read access"]
},
"strategy": {
"steps": ["彙整日誌", "計算百分位指標", "產生摘要"],
"tools": ["Python script", "LLM"]
},
"evaluation": {
"definitionOfDone": "摘要與日誌指標吻合",
"tests": ["unit test", "semantic alignment check"]
}
}
這不再是一段模糊的文字描述。它是一個可被 AI 直接解析、執行、驗證的結構化物件。
「Ontology」這個詞聽起來很學術,但它的核心非常直覺:定義一個系統中「存在什麼東西」以及「它們之間的關係」。
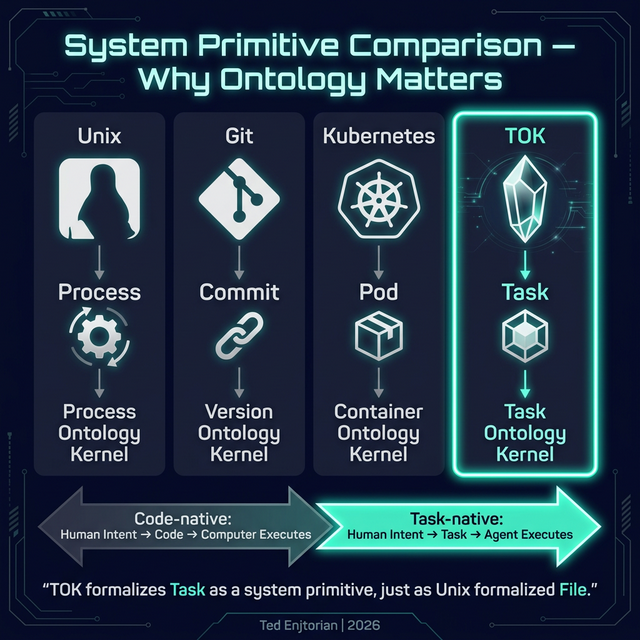
每個成功的系統都有其核心 Primitive:
| 系統 | Primitive | 本質 |
|---|---|---|
| Unix / Linux | Process | Process Ontology Kernel |
| Git | Commit | Version Ontology Kernel |
| Kubernetes | Pod | Container Ontology Kernel |
| TOK | Task | Task Ontology Kernel |
Unix 並沒有「發明」檔案的概念。但 Unix 第一次把「檔案」變成系統的原生 Primitive。
TOK 也不是發明「任務」。而是第一次把任務形式化為可被 AI 原生執行的系統 Primitive。
這代表軟體工程正在經歷一次根本的範式轉移:
Code-native 時代:人類意圖 → 翻譯為程式碼 → 電腦執行
Task-native 時代:人類意圖 → 結構化為任務 → Agent 執行
程式碼不是消失了,而是從「核心資產」變成「衍生工具」。就像你用 Git 時,「commit」才是核心單位,file 只是 commit 的附屬品。
在 Task-native 系統中,任務成為執行、治理與演化的最小原生單位,而程式碼則成為由任務生成或協調的衍生產物。
好的抽象發現總是讓人覺得「這不是本來就這樣嗎?」。File、Object、Function、Container它們都不是新東西,只是第一次被形式化。
TOK 也是如此。
任務一直存在。但在 LLM 出現後,任務第一次有機會成為可執行的系統單位而 TOK 就是為這一刻定義的本體結構。
👉 下一篇:TOCA 是什麼?任務導向認知架構的核心循環
最完整的內容:https://enjtorian.github.io/task-ontology-kernel/zh-tw/
 enjtorian
enjtorian

 iThome鐵人賽
iThome鐵人賽