最近因為除了自己買的 claude pro 方案之外,也有公司的帳號提供 teams 方案,所以嘗試在開發中多開幾個 agent window 來進行開發,而我目前開發時都會依照 openspec -> gherkin -> pytest-bdd -> code -> ruff, pyright -> code review 的方式去開發(詳情請見:靠 Skills 補齊從需求到程式碼之間遺失的資訊)。
但是我在多 agent 的開發下,開始遇到幾個問題:
先說前者,在新開一個 agent 時,撇除 hotfix 小 bug 之外,可能大部分都是需要開發一個 feature,然後跟 claude code 討論一下實作面向後進到 openspec 流程。而我覺得重點就是在一開始的討論上,當我其實對於專案沒有一開始做一次 deep dive,沒有了解可能需要抽象的點,對於資料流沒有做好的規劃,很容易出現見樹不見林的窘境。而這也連帶導致第二點,缺乏全盤一致的 mindset,在 code review 不是在 review 應該實作的驗證流程,反而更像是在開驚喜包,或是依賴 agent 給出適合的解方。
所以我也才意識到為什麼開發這麼消耗精力,因為我一開始就沒有規劃清楚,讓各種決策壓力延遲到開發中才一一爆發。但是好的開發流程應該是先訂好方向,了解什麼是要做,哪些事情不要做,探討外部與資料交互的介面,理解系統可能的瓶頸點,最重要的事情是什麼?哪些事情是有缺陷但是可以接受的。當這些問題都有了答案,那程式碼就只是實踐的一種工具。
這邊引用 advanced-context-engineering-for-coding-agents 中提到的概念:
bad research 導致多個 bad plans,而一個 bad plan 會生出一堆 bad code
而我也從該篇文章得到一個很好的啟發,文中是使用 research.md 與 plan.md 來作為專案中高槓桿的人工審查。而我覺得這樣跟 agent 深刻進行討論的結論,應該記錄下來,做為專案中的 single source of truth 橫跨整個開發的生命週期。
現在我知道我有了新的方向:
而為了了解如何在專案開始前做品質高的規劃,我參考了 91 APP 首席架構師安德魯的 skills 之中的架構。不過我覺得蠻多概念對我來說難度還是太高了,在好好閱讀相關文章之前,我只能對於如何規劃這件事情,有一個模糊的骨幹與認知。
因此我與 agent 根據該 skills 為導師,去討論在我能理解的層次之中,我能夠先做什麼事情來讓規劃這件事情變得有意義。
同時也去參考安德魯提過的開發方式,其中強調了使用 code 本身來作為骨架,去讓實作不會歪到哪裡去。
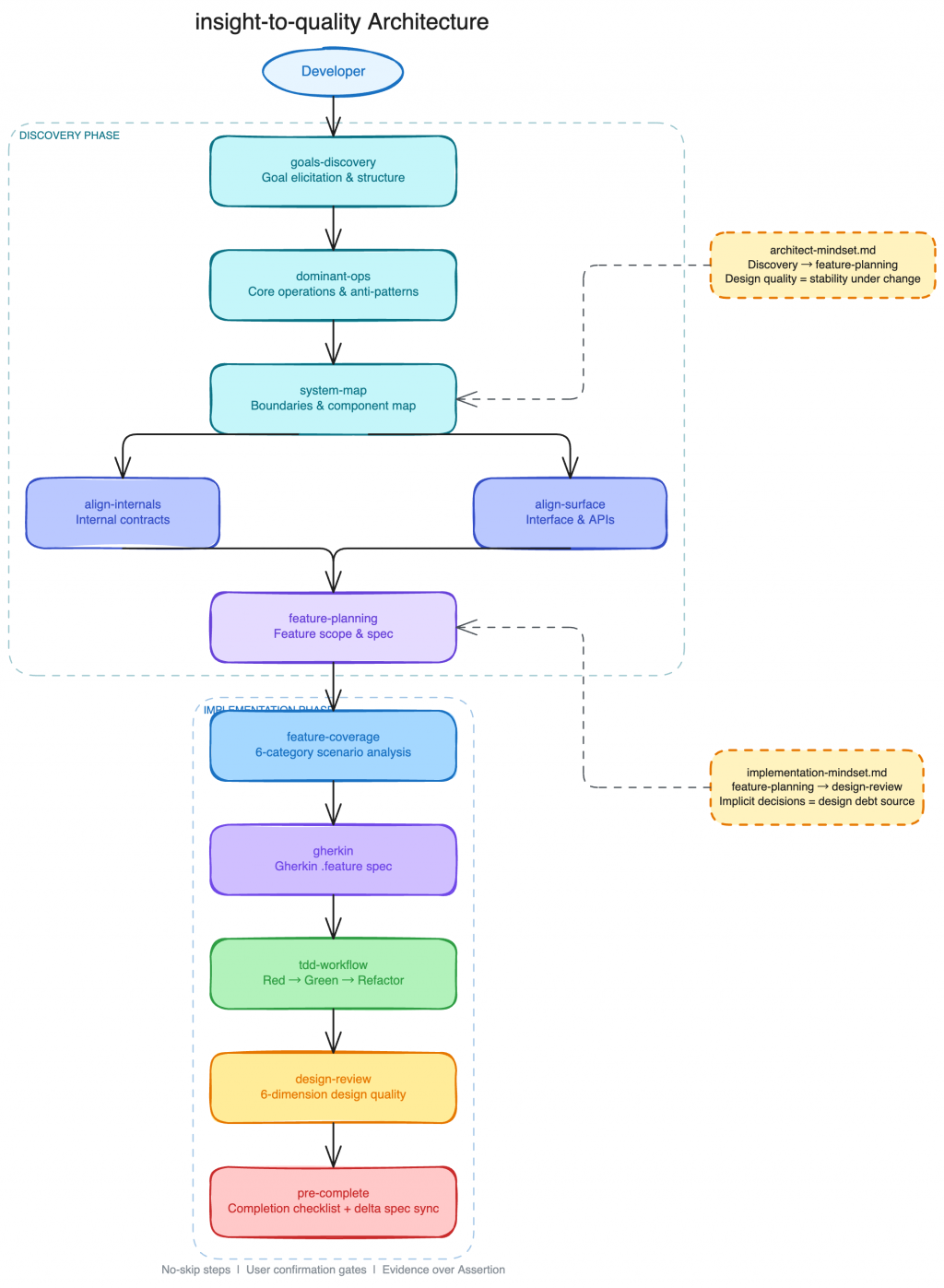
根據上面的流程,我對於整個 discovery 的流程大致如下:
| Skill | 做什麼 |
|---|---|
| goals-discovery | 定義系統目標、非目標、NFR 跟約束條件 |
| dominant-ops | 找出壓力所在(頻率 x 代價 x 失敗影響) |
| system-map | 建立導航地圖:Component Map、Boundary Map、Change Protocol |
| align-internals | 設計或驗證 contracts 與 persistence 的對齊 |
| align-surface | 設計或驗證使用者介面與基礎設施的對齊 |
goals-discovery 不是讓你自由填寫目標清單,而是透過提問確認每個目標「在正確的抽象層面上站得住腳」。每個候選目標要通過三個測試:
通過測試的目標才會被分配 ID(G1, G2...),這些 ID 後續在所有 downstream 文件中都可以被引用,形成可追溯的鏈。
從 goals 到 dominant-ops,要識別「哪些操作的壓力最大」。量化方式是:
Criticality = Frequency × Cost × Failure Impact
Failure impact 是最容易被低估的——一個低頻但靜默失敗會讓資料損壞的操作,比一個高頻但無害的操作實際上更危險。dominant-ops 強制排序,最多選三個;如果每件事都重要,設計上就無法做取捨。
有了 goals 和 dominant-ops 之後,system-map 的工作是把系統裡的邊界(seam)畫出來。每條 seam 要通過三個測試:
三個測試都通過,邊界才是對的;有任何一個不過,邊界可能畫在錯的地方。
SYSTEM_MAP 的實用價值不只是知道邊界在哪裡。Boundary Map 記錄每條 seam 兩端的 contract(資料形狀、API 格式),讓「Component A 的輸出是不是 Component B 期望的輸入」這個問題有地方可查。Component Map 加上 Mermaid diagram 讓資料流的走向一目瞭然。
Change Protocol 是這份文件在多 agent 開發下最關鍵的部分。它把所有改動按影響範圍分成四種類型,讓任何 agent 或開發者在動手前就知道「這次改動需要碰哪些東西」。多個 context window 同時工作時,每個 agent 不需要重新理解整個 codebase,查 SYSTEM_MAP 就能獨立判斷自己的改動範圍。
Current State 和 Lessons 兩個區塊解決了 context 切換的成本問題。切換到新的 context window 或新的 agent 加入時,Current State 記錄現在的開發進度與已知缺口,Lessons 記錄開發過程中踩過的坑,讓新 context 不用從頭理解架構,也不會重複走進同一個死角。
而我原本的 spec-to-quality 流程當然也要跟著調整,在 openspec 開始之前會有 feature-plan 的步驟去好好看我們現在應該是針對哪個目標去開發 feature,同時在實作時,也應該要用統一的規格去開發。
這個統一規格來自另一份 implementation-mindset。它的核心是:隱式決策是設計負債的根源。當一個實作選擇從來沒有被說出來過,它就無法被審查、被質疑、或是被有意識地修改。其中最關鍵的是錯誤處理策略:在寫 Gherkin 與測試之前,你必須先明確宣告 Catch Boundary(例外在哪裡停止往上拋?)、Error Taxonomy(哪些是 domain 錯誤、哪些是 infrastructure 錯誤?)以及 Recovery Strategy(每種錯誤的處置方式是什麼?)。沒有這份宣告,設計審查只能是猜測,而不是對照。
它也提供了一套「衝突分類」機制(Level 0–3):當實作途中遇到阻力,知道是只要改 code(Level 0),還是要回到 OpenSpec(Level 1)、SYSTEM_MAP(Level 2),甚至是 goals/dominant-ops(Level 3)才能根治問題。這讓卡關不再是焦慮,而是有結構的判斷。
這樣的流程調整之後,最後的 code review 自然就變成是驗收——對照宣告、確認預期——而不是在開驚喜箱。
這套流程不是每件事都要從頭跑完整個 discovery。根據情境有不同的起點:
| 情境 | 起點 | 路徑 |
|---|---|---|
| 全新專案 | 沒有任何 discovery 文件 | 完整 discovery(goals → dominant-ops → system-map → align)→ feature-planning → 實作流程 |
| 舊專案接手 | 有 code 但沒有文件 | 考古(掃描 codebase)→ 安全網(characterization tests)→ discovery(驗證模式)→ 漸進重構 |
| 正常開發 | Discovery 完成,開始下一個 feature | feature-planning → feature-coverage → gherkin → tdd-workflow → design-review → pre-complete |
| 小改動 | 內部實作調整,boundary 不變 | OpenSpec → tdd-workflow → pre-complete |
| Bug fix | 測試失敗或非預期行為 | 收集證據 → 建立假說 → 驗證,不猜測性修改 |
| 實作中發現問題 | 實作到一半遇到阻力 | 用 Discovery Conflict Triage 判斷影響層級,從對應層級往下修 |
align 系列(align-internals / align-surface)支援兩種模式:設計模式(沒有現成 code,引導契約設計)和驗證模式(有現成 code,審計現有對齊狀況),讓接手舊專案也有路可走。
這樣的流程目前還沒有經歷多次專案的開發考驗,我目前是根據 skills 生出的檔案以及我對於原始專案的了解來進行評估。同時我也讓 agent 自己設計一個小專案去驗收 skills 是否有好好執行。其中發現有一個很大的前提,那就是與 agent 互動時,必須要真的與 agent 做有效的互動,要透過 agent 的引導,慢慢地讓我們雙方都更接近專案的真相,如果很依賴自動開發的話,最好也是要先把 discovery 的部分先完成,後續步驟再使用更自動化的方式開發。
就像原本的版本一樣,這樣的 skills 就是一個我個人對於開發心態的具象化,原本的我只專注在如何把事情做好,而我漸漸發現還有更重要的事情:我們應該做哪些事情?哪些事情才是最重要的?
GitHub repo:class83108/insight-to-quality
超有共鳴!自己在多 agent 開發時也常常陷入"見樹不見林"的狀態,結果 code review 變成開驚喜包。goals 的三個測試(替換、兩種設計、六個月)很實用,打算馬上試試看,感謝分享!
 blank
blank
