各位大大好
小弟平常都寫linux script ,第一次寫python。
最近用import web 方式寫了一支pycurl搭配uwsgi
實現的方式,如下圖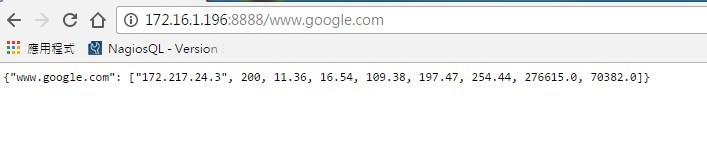
後面get 參數帶domain 的話,會自動跑pycurl 的數值,但想嘗試後面帶多個domain 用for 迴圈的方式跑出多筆domain 的測試結果,類似下列這樣
http://ip/www.google.com,www.yahoo.com
,但不知道要怎修改,有python高手可以幫忙看下嗎?
感激不盡。
下面是我寫的code
#!/bin/python
import os,sys
import time
import sys
import pycurl
import web
import json
import cStringIO
urls = ('/(.*)', 'index',)
app = web.application(urls, globals())
class index():
def __init__(self):
self.contents = ''
def body_callback(self,buf):
self.contents = self.contents + buf
def GET(self,input_url):
condition = web.input()
buf = cStringIO.StringIO()
t = index()
c = pycurl.Curl()
c.setopt(c.WRITEFUNCTION, buf.write)
c.setopt(pycurl.URL, input_url)
c.setopt(pycurl.ENCODING, 'gzip')
c.setopt(pycurl.USERAGENT, 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36')
c.setopt(pycurl.HTTPHEADER,['text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'])
c.setopt(pycurl.COOKIEFILE, "cookie_file_name")
c.setopt(pycurl.CONNECTTIMEOUT, 1)
#c.setopt(pycurl.CONNECTTIMEOUT, 60)
#c.setopt(pycurl.TIMEOUT, 100)
c.setopt(pycurl.FORBID_REUSE, 1)
c.setopt(pycurl.FOLLOWLOCATION, 1)
c.setopt(pycurl.MAXREDIRS, 3)
c.setopt(pycurl.NOPROGRESS, 1)
c.setopt(pycurl.DNS_CACHE_TIMEOUT,30)
try:
c.perform()
self.http_code = c.getinfo(pycurl.HTTP_CODE)
buf.getvalue()
buf.close()
except Exception,e:
error_info=[e[0],e[1]]
error_info=json.dumps(error_info,sort_keys=False)
return error_info
NAMELOOKUP_TIME = c.getinfo(c.NAMELOOKUP_TIME)
CONNECT_TIME = c.getinfo(c.CONNECT_TIME)
PRETRANSFER_TIME = c.getinfo(c.PRETRANSFER_TIME)
STARTTRANSFER_TIME = c.getinfo(c.STARTTRANSFER_TIME)
TOTAL_TIME = c.getinfo(c.TOTAL_TIME)
HTTP_CODE = c.getinfo(c.HTTP_CODE)
SIZE_DOWNLOAD = c.getinfo(c.SIZE_DOWNLOAD)
HEADER_SIZE = c.getinfo(c.HEADER_SIZE)
SPEED_DOWNLOAD=c.getinfo(c.SPEED_DOWNLOAD)
domain=input_url
domainip=c.getinfo(c.PRIMARY_IP)
http_code=HTTP_CODE
namelookuptime=round(NAMELOOKUP_TIME*1000,2)
total_time=round(TOTAL_TIME*1000,2)
speed=round(SPEED_DOWNLOAD,2)
conntime=round(CONNECT_TIME*1000,2)
pretransfertime=round(PRETRANSFER_TIME*1000,2)
starttransfertime=round(STARTTRANSFER_TIME*1000,2)
sizedownload=round(SIZE_DOWNLOAD,2)
url_info_dict={}
url_info_dict={domain:[domainip,http_code,namelookuptime,conntime,pretransfertime,starttransfertime,total_time,speed,sizedownload]}
url_info_dict=json.dumps(url_info_dict,sort_keys=False)
return url_info_dict
#indexfile.close()
bur.close()
c.close()
if __name__ == '__main__':
input_url = sys.argv[1]
application = app.wsgifunc()
已邀請的邦友 {{ invite_list.length }}/5
簡略說明你應該把你的上面的code當作是Middleware另外再寫一支py來get或post至於兩者差異這邊就不再贅述.
建議你詳讀PycURL 說明 http://pycurl.io/docs/latest/quickstart.html
裡頭說的很詳細以及DEMO Code.
祝你順利成功.
