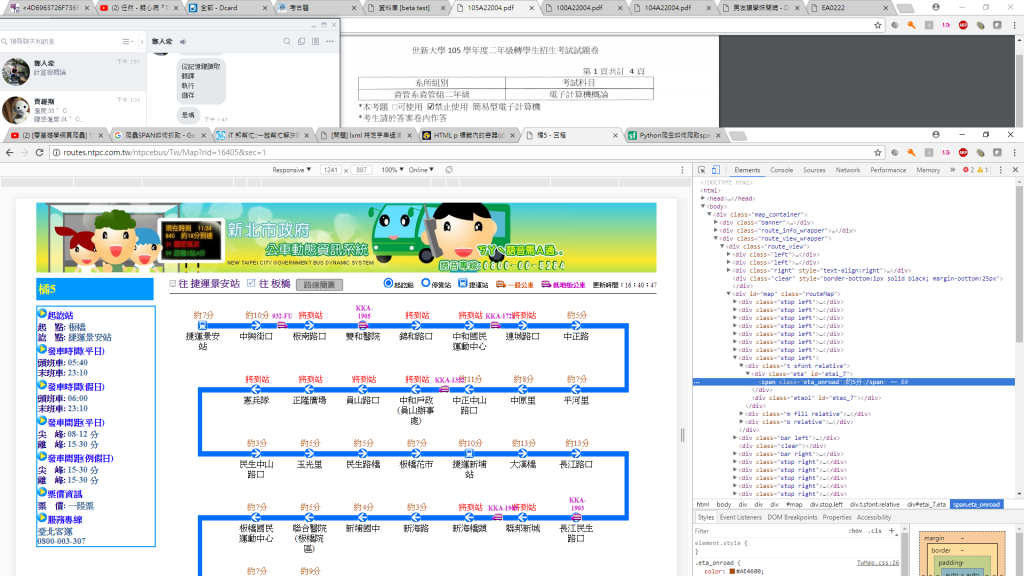
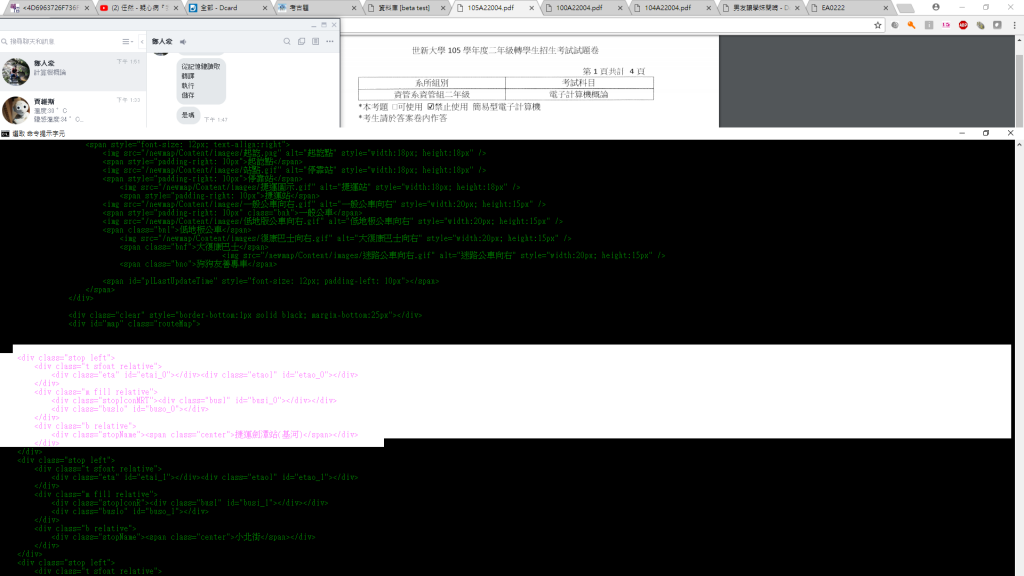
我的code很簡單只是要先看看爬出來的資訊 在做篩選
code:
import requests
from bs4 import BeautifulSoup
res = requests.get('http://www.e-bus.taipei.gov.tw/newmap/Tw/Map?rid=10821&sec=0')
soup = BeautifulSoup(res.text,'html.parser')
print(res.text)
文字解說:第一張是我要抓的公車進站時間
第二張是說明 我print(res.text) 就是沒有出現到站時間
已邀請的邦友 {{ invite_list.length }}/5
幫你看了一下,那個是用ajax去取,然後再由前端呈現的,所以你直接用request取不到。
ajax網址:
http://www.e-bus.taipei.gov.tw/newmap/Js/RouteInfo?rid=10821&sec=0&_=1527033355647
這個網頁的實時公車資訊是使用js傳回來的,這樣requests是取不到的,但是可以先使用瀏覽器的開發者工具,選擇"Network"了解數據是由哪邊過來的。

直接請求json網址加上時間戳,就可以取到公車的資訊。

探索一下兩邊網頁的對應,就能取到目前的停靠站了。
謝謝您的回覆
不好意思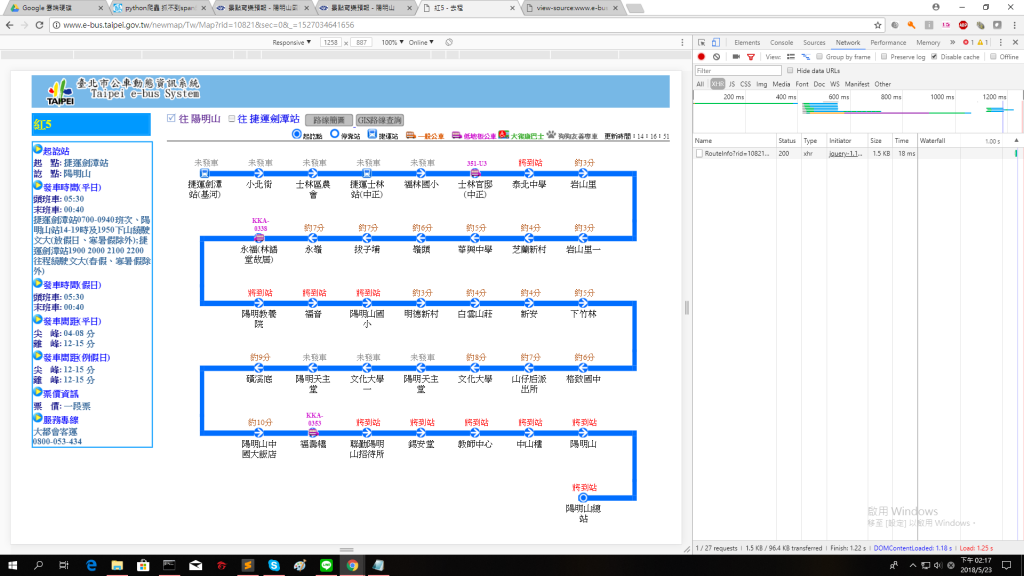
我的看起來怎麼跟你的不一樣
我找到了~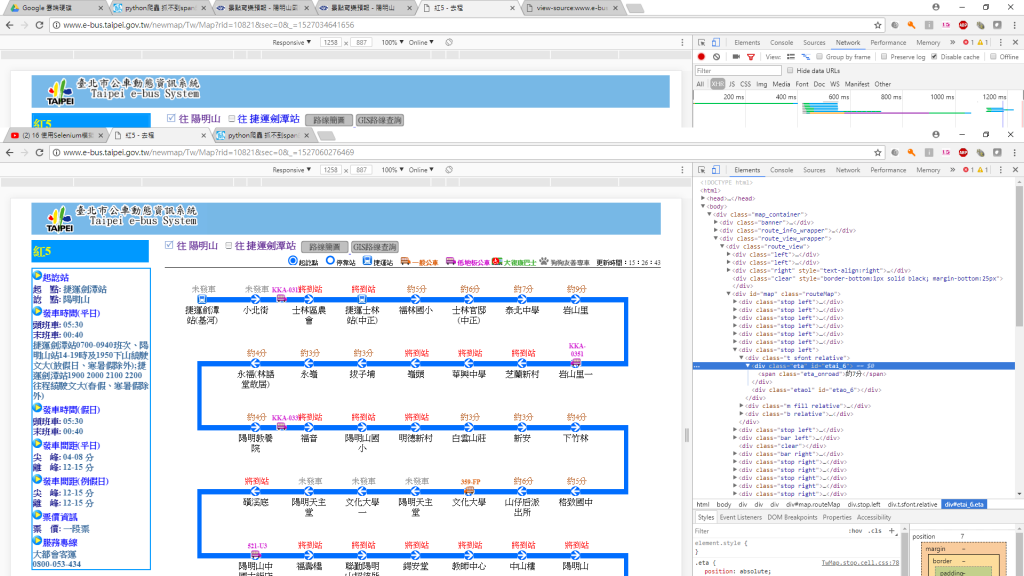
只是沒有跑出跟你第二張一樣的畫面
你可能找錯了,你在看下,紅5的ajax url是這個
http://www.e-bus.taipei.gov.tw/newmap/Js/RouteInfo?rid=10821&sec=0&_=1527119143185

