該如何合併不要有NAN
apply 可以直接加速資料就不用合併嘛!
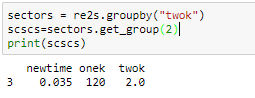
sectors = re2s.groupby("twok")
scscs=sectors.get_group(2)
print(scscs)
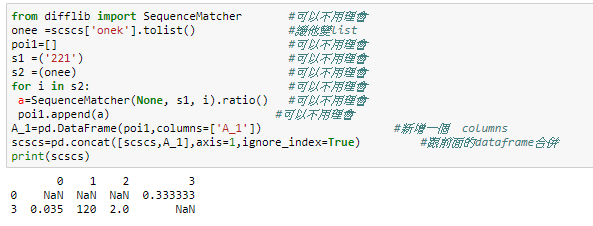
from difflib import SequenceMatcher #可以不用理會
onee =scscs['onek'].tolist() #讓他變list
poi1=[] #可以不用理會
s1 =('221') #可以不用理會
s2 =(onee) #可以不用理會
for i in s2: #可以不用理會
a=SequenceMatcher(None, s1, i).ratio() #可以不用理會
poi1.append(a) #可以不用理會
A_1=pd.DataFrame(poi1,columns=['A_1']) #新增一個 columns
scscs=pd.concat([scscs,A_1],axis=1,ignore_index=True) #跟前面的dataframe合併
print(scscs)
我要如何不要出現NAN 直接加在後面 可以用apply示範一次給我看看嘛!!
已邀請的邦友 {{ invite_list.length }}/5
