想請問一下Hyper-V裡的服務品質(iops)
那東西應該要怎麼設定呢?
有什麼可以參考的?
比如說我公司系統首頁的主機,最低應該要給多少呢...?
Ex.50人用
因為Stroage IOPS不太夠用
所以想藉由這個方式來限制讓一些主要服務可以保持最低的IOPS
今年沒預算買新東西了
已邀請的邦友 {{ invite_list.length }}/5
自己的 IOPS 自己量: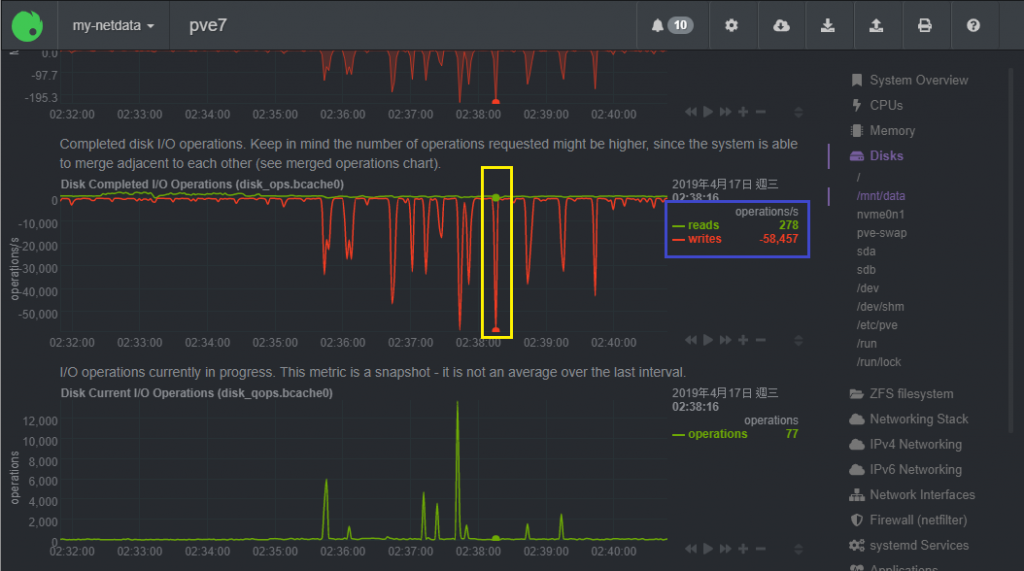
維運工程師隨時要了解自己管轄伺服器的健康狀況, IOPS 只是其中一項而已; 例如上圖: 我可以很清楚的知道, 這台伺服器在 4/17 凌晨 2 點 38 分 16 秒的時候, Read IOPS 是 278, 而 Write IOPS 則是 58,457
而且, 我還可以隨時回去查過去的歷史; 或者把資料倒出來做統計, 或者快照下來做深入的分析比對...
不同的作業系統, 可以用的監測工具也不一樣, 有些內建就有, 有些你要自己建一套網管系統起來收集, 這些都準備好了, 你才能看見自己伺服器的數據....
可以收的維運數據多到像螞蟻, 隨便撿都一堆, 你想問甚麼健康問題, CPU/RAM/DISK/Network/Application....大概都能答得出來; 例如, 下面是伺服器內 CPU 每一個 core 的溫度: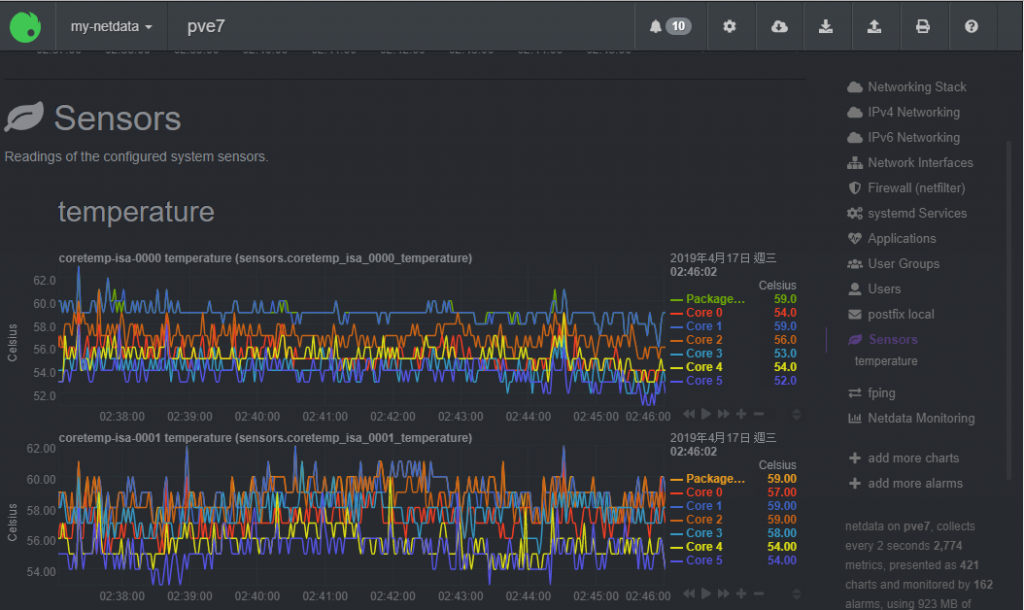
那是 netdata, 2018 鐵人賽介紹過:
IT|維運管理|作業系統| Linux|利用 Netdata 資源監控管理
他很適合用來做即時監控與查修, 以及快照當下的所有狀態進行比對, 但不適合儲存大量歷史數據 (3天以上)....而且, netdata 只適用於抓 Linux 數據....
若是要抓 Windows 數據, 或者兩者混用, 而且需要存長期(1年以上)歷史資料的話, 可以考慮看看 Zabbix+Grafana:
1-1.監控工具之一:Zabbix Server
感謝,就是因為量出來已經超出太多了,導致其他server的服務都變得很慢或異常,所以才想去限制,不過又不知道怎樣限制才不會讓服務出問題?
謝謝大神,可以來好好研究一番了
