工作上的需要,要將半形轉成全形,網路上找了一下,好像程式碼都很長,於是,自己胡亂寫一個,請大家看看有無改善空間。
CREATE DEFINER=`root`@`%` FUNCTION `chstr`(`nstr` varchar(100)) RETURNS varchar(200) CHARSET utf8mb4
NO SQL
BEGIN
declare nlen,i,nascii int default 1;
declare vtext,chnumber,nsubstr varchar(200) default '';
set nlen=char_length(nstr);
set chnumber = ' !”#$%&’()*+,-./0123456789:;<=>?@abcdefghijklmnopqrstuvwxyz〔\〕︿ˍ‘abcdefghijklmnopqrstuvwxyz{|}~';
while (i<=nlen) do
set nsubstr=substr(nstr,i,1);
set nascii=ascii(nsubstr);
set vtext=concat(vtext,if((nascii between 32 and 126),substr(chnumber,(nascii-32)+1,1),nsubstr));
set i=i+1;
end while;
return vtext;
END
使用方法
select chstr('您要測試的中英文abc ABC 123 {})(*$#@');
我希望程式碼越短越好。
已邀請的邦友 {{ invite_list.length }}/5
嗯...我慣用MSSQL的語法...
如果你找一下相似的MySQL語法~應該可以跟我一樣~
declare @Str nvarchar(max) = '您要測試的中英文abc ABC 123 {})(*$#@'
select replace((
select (case when UNICODE(substring(@Str,Sort,1)) between 33 and 125 then NCHAR (65248 + UNICODE(substring(@Str,Sort,1))) else substring(@Str,Sort,1) end) + ''
from (
select Row_Number()Over(order by number) as Sort
from master..spt_values
) as k
where Sort <= len(@Str)
for xml path('')
),' ',' ') as StrShow
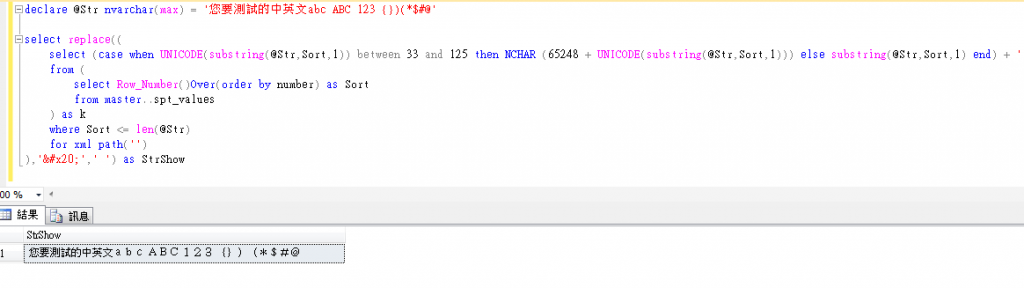
Mysql 版..我只能解到這程度吧..先忙工作= =||
select Replace(GROUP_CONCAT(Str),',','') as Str1
,Replace(GROUP_CONCAT(Str_Run),',','') as Str2
from (
select substring(Str,Sort,1) as Str
,(case when ORD(substring(Str,Sort,1)) between 33 and 125 then 'x' else substring(Str,Sort,1) end) as Str_Run
from (
SELECT @i := @i + 1 as Sort
,Str
FROM information_schema.columns as a
,(
select @i := 0
,'您要測試的中英文abc ABC 123 {})(*$#@' as Str
) temp
) as k
where Sort <= char_length(Str)
) as k
http://sqlfiddle.com/#!9/d47893/37
呵...根據你的方式再調整~這樣的確可以轉~
select
GROUP_CONCAT(if((ascii between 32 and 126),substr(chnumber,(ascii-32)+1,1),name) separator '') ReStr
from(
select
SUBSTR(cStr, c+1,1) as name,
ascii(SUBSTR(cStr, c+1,1)) AS ascii
,chnumber
from(
SELECT (TWO_1.SeqValue + TWO_2.SeqValue + TWO_4.SeqValue + TWO_8.SeqValue + TWO_16.SeqValue + TWO_32.SeqValue) c
FROM (SELECT 0 SeqValue UNION ALL SELECT 1 SeqValue) TWO_1
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 2 SeqValue) TWO_2
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 4 SeqValue) TWO_4
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 8 SeqValue) TWO_8
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 16 SeqValue) TWO_16
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 32 SeqValue) TWO_32
) as b
,(
SELECT ' !”#$%&’()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ〔\〕︿ˍ‘abcdefghijklmnopqrstuvwxyz{|}~' as chnumber
,'您要測試的中英文abc ABC 123 {})(*$#@' as cStr
) as k
WHERE c <= CHAR_LENGTH(cStr)-1
) as a;
感恩!
您的式子,看起來很專業,我的就如同土法練鋼,難登大雅之堂。
不知有沒有那位高僧大德,能將這段語法轉寫成mysql語法。
ckp6250
我轉的MySql的SQL還缺一個函數轉回文字計算~交給你找啦...
感謝您的提點,如此程式碼看起來優雅多了。
由您處得來的靈感,我改寫成如下程式~
CREATE DEFINER=`marco`@`%` FUNCTION `chstr`(`cStr` text) RETURNS text CHARSET utf8mb4
NO SQL
BEGIN
declare cRetStr text;
declare chnumber varchar(200) default ' !”#$%&’()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ〔\〕︿ˍ‘abcdefghijklmnopqrstuvwxyz{|}~';
select
GROUP_CONCAT(if((ascii between 32 and 126),substr(chnumber,(ascii-32)+1,1),name) separator '') into cRetStr
from(
select
SUBSTR(cStr, c+1,1) as name,
ascii(SUBSTR(cStr, c+1,1)) AS ascii
from(
SELECT (TWO_1.SeqValue + TWO_2.SeqValue + TWO_4.SeqValue + TWO_8.SeqValue + TWO_16.SeqValue + TWO_32.SeqValue) c
FROM (SELECT 0 SeqValue UNION ALL SELECT 1 SeqValue) TWO_1
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 2 SeqValue) TWO_2
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 4 SeqValue) TWO_4
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 8 SeqValue) TWO_8
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 16 SeqValue) TWO_16
CROSS JOIN (SELECT 0 SeqValue UNION ALL SELECT 32 SeqValue) TWO_32
) as b
WHERE c <= CHAR_LENGTH(cStr)-1
) as a;
return cRetStr;
END
另一點報告,經我反覆測試的結果,您的方法執行速度約比我的方法耗時多十倍,但我沒有找出原因。
應該是出自information_schema.columns的讀取問題~
我也是這麼懷疑,畢竟information_schema要去讀取硬碟。
但,我也有試著加上 limit 20 語法,限制讀取筆數,
但沒有改進多少。
我的式子約耗時0.05秒,您的約需0.5秒,
差了很多,一定有某個環節卡在那裡。
ckp6250
直接套你的方式~這樣的確轉成~
MySql的全型可能要自己定義吧~
已更新在回答~
您可以參考這篇
https://www.itread01.com/p/1202158.html
這篇是全形轉半形,調整一下或許就可以了
使用Postgresql
select translate('123456789円です', '0123456789', '0123456789');
+-----------------+
| translate |
+-----------------+
| 123456789円です |
+-----------------+
select translate('123456789円です', '0123456789', '0123456789');
+--------------------------+
| translate |
+--------------------------+
| 123456789円です |
+--------------------------+
MySQL 可以使用replace().
Postgresql 另外使用 Oracle的函數
select to_multi_byte('1234567890');
+----------------------+
| to_multi_byte |
+----------------------+
| 1234567890 |
+----------------------+
(1 row)
select to_single_byte('123456789');
+----------------+
| to_single_byte |
+----------------+
| 123456789 |
+----------------+
(1 row)
