Dear 各位IT大大們~
有一個TXT轉入MSSQL需求,我目前只能透過逗點隔開才能匯入到MSSQL...
不以逗點的方式,有什麼方式能以圖片方式取紅色框框兩欄即可,直接匯進去MSSQL呢?
以下是MSSQL的欄位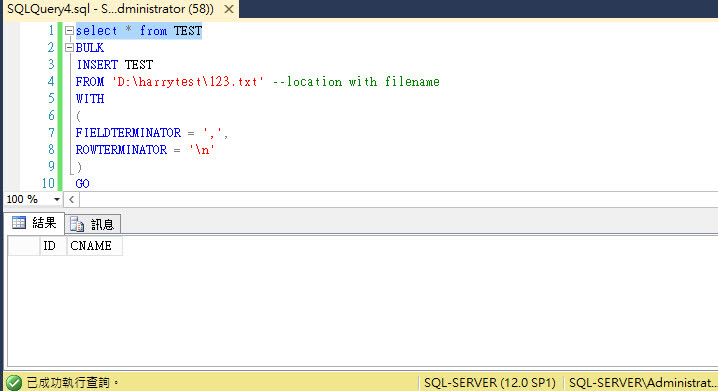
已邀請的邦友 {{ invite_list.length }}/5
除了用逗點的csv檔
還有一種用\t隔開的tsv檔
用法看這篇
https://stackoverflow.com/questions/31769099/local-tsv-file-into-sql-table
除了 \t (tab) 外, 還有一種"固定間隔", 比如第 1~10 格(半形)是身分證字號, 11~20 格( 5 個全形)是姓名.
這樣先插入一個暫存表, 再用 mid / substr 等指令切出特定第幾格, 才存到 Table .
各位大大,目前用網路上的語法有搞定了,剩下一個問題,只會執行最後一筆...
declare @sql varchar(8000)
declare @content varchar(8000)
declare @qrysql varchar(8000)
set @qrysql='select * from test'
--create stage table
create table test2(
c1 varchar(8000) null
)
--load text file to stage table
BULK INSERT test2
FROM 'D:\harrytest\CardInfo2.txt'
--insert into target table
select @content=c1 from test2
set @sql='insert into TEST select '''+SUBSTRING(@content,1,5)+ ''','''+ SUBSTRING(@content,6,5)+''''
exec(@sql)
--show result
exec(@qrysql)
你有一個tab分隔的文字檔,每行有N欄,
但你只需其中的第3,4兩欄,
這種我通常是會寫個小腳本把文字檔濾掉不要的
再另存新文字檔,用新文字檔匯入就不用那些複雜的sql命令了,
腳本範例(使用python):
"""
假設test1.txt內容為
標題 項目 id cname 一 二 三 四 五 六
11 22 id1 tw1 1 2 3 4 5 6
11 22 id2 tw2 1 2 3 4 5 6
11 22 id3 tw3 1 2 3 4 5 6
"""
with open("test1.txt","r",encoding="utf-8") as f:
content=f.read()
f.close
fileArray=content.split('\n')
with open("text1_new.txt","w",encoding="utf-8") as f:
for i in range(1,len(fileArray)):
tmpArr=fileArray[i].split('\t')
f.writelines(tmpArr[2]+'\t'+tmpArr[3]+'\n')
f.close
"""
新文字test1_new.txt內容為
id1 tw1
id2 tw2
id3 tw3
"""
也可以用vbs(相對python作法麻煩很多)或其它方式處理,
甚至你開一個notepad++,
用裡面的尋找取代搭配正則表達式
也可以從十欄取出需要的兩欄,
我想說的是不建議用牛刀殺雞,更不要拿美工刀殺牛,
除非你想練到能徒手殺牛那種境界...

 iThome鐵人賽
iThome鐵人賽