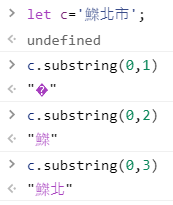
發現有些中文字,用 substring 取內容,會有亂碼:
但一般中文字又不會: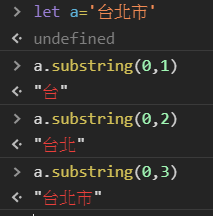
什麼時候該用 substring(0,1) ,什麼時候又該用 substring(0,2)?
已邀請的邦友 {{ invite_list.length }}/5
參考 utf16
let test_str='?北市';
function utf16_substring(str, start, end)
{
let idx_1=0,count=0,n=str.length;
for(count=0; idx_1<n && count<start; ++count) {
idx_1+=str.codePointAt(idx_1)>0xffff?2:1;
}
let idx_2=idx_1;
for(; idx_2<n && count<end; ++count) {
idx_2+=str.codePointAt(idx_2)>0xffff?2:1;
}
return str.substring(idx_1, idx_2);
}
console.log(test_str.substring(0, 2));
console.log(utf16_substring(test_str, 0, 2));
let c = '魚桀北市' // ?北市;
你可以用 console.log(c.length)
會發現長度為 4
也就是說 魚桀 這個字
長度為 2
解決的方法可以用個例外來特別處裡
會這樣的
應該也是少數
javascript的中文字視1長度的。只限於在big5能使用的中文字。其它字還是會被視為2或3的長度。
大多數來說。如果有中文字截斷的處理。我是不會用javascript的截斷處理。
那怎麼辦??無法信任 substring 截取方式??
那就只好自已寫啦!!或是網路上找找其它處理的方式了。



