因為你沒寫要抓什麼網頁...所以隨便選一個了。
語言是python。
首先要裝 requests-html
from requests_html import HTMLSession
url = "https://www.google.com/search?q=google&client=ubuntu&hs=Jw5&channel=fs&sxsrf=ACYBGNQoBB1ys9AAPy5g3glvXTdn8PWs7Q:1575993930420&source=lnms&tbm=isch&sa=X&ved=2ahUKEwiT7Y_zuqvmAhUIq5QKHdSHBcoQ_AUoAnoECAwQBA&biw=1920&bih=951"
r = HTMLSession().get(url)
imgs = r.html.find("img")
感謝大大
那擷取後會得到像這樣的
<Element 'img' src='/images/branding/googlelogo/2x/googlelogo_color_92x30dp.png' alt='Google' height='30' width='92' onload="typeof google==='object'&&google.aft&&google.aft(this)">
不乾淨 有其他能指定網址尾端是png或jpeg的方法嗎
抓到這坨字之後使用正規表示法抓出來囉!
不過沒用過python不太清楚,看了一下應該是
import re
re.search(pattern, string)
這樣就可以擷取到你想要的網址了吧!
不過python應該也有像其他語言寫的套件
直接取得element的attribute內的src吧!
這部份就等其他大大回囉~
requests-html是一個高級的爬蟲lib包,爬出來的是他的Element物件。
以上面的例子,你可以很簡單的存取imgs下的所有src:
for img in imgs:
src = img.attrs.get("src")
請參閱 requests-html 給的範例和API,很短。
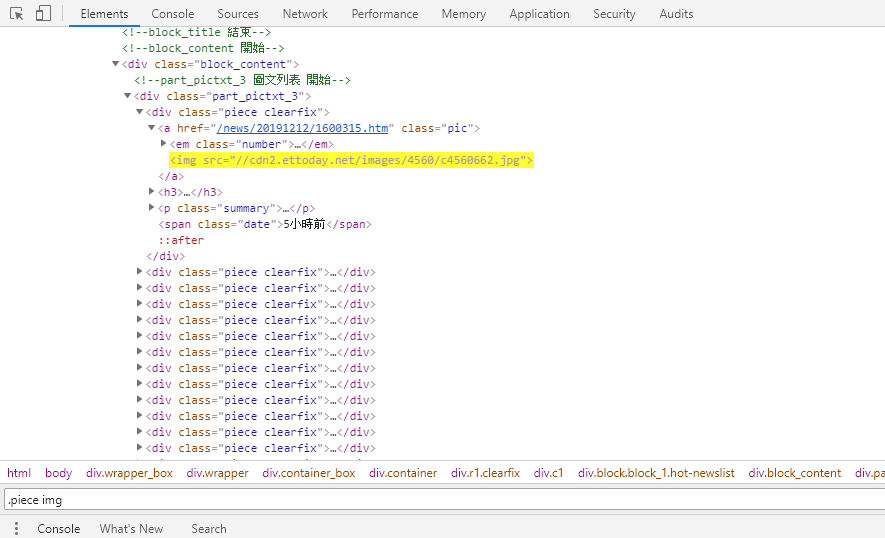
以 ettoday 熱門新聞為例:
import requests
from bs4 import BeautifulSoup
url = 'https://www.ettoday.net/news/hot-news.htm'
res = requests.get(url).text
doc = BeautifulSoup(res, 'lxml')
for news in doc.select('.piece'):
image = news.findAll('img')[0]['src']
print(image)
這個線上教學有你需要的做法,我自己看了之後很有幫助,課程評價非常好,應該可以解決你的問題!
https://www.udemy.com/course/python-crawler/?referralCode=A4F2B9D20A2C35D5001D


 iThome鐵人賽
iThome鐵人賽