Python爬蟲爬蝦皮資料,目前單頁資料已經完成所有的擷取,但是單頁只有6筆資訊,所以進階做多網頁資料爬取,首先,發現不同網頁的差異只有在url網址其中的數字做跳頁,例如
第一頁:
url = "https://shopee.tw/api/v2/shop/get_ratings?filter=0&limit=6&offset=0&shopid=4098392&type=0&userid=4099676"
第二頁:
url = "https://shopee.tw/api/v2/shop/get_ratings?filter=0&limit=6&offset=6&shopid=4098392&type=0&userid=4099676"
只有差在 "offset=0" 和 "offset=6",因為一頁只有6筆(0~5),所以第二頁是從第6筆開始,測試跳頁迴圈是否可以正確抓取 url:下面是我使用的方式
import time
url = "https://shopee.tw/api/v2/shop/get_ratings?filter=0&limit=6&offset={}&shopid=4098392&type=0&userid=4099676"
for t in (0, 6, 12):
print(url.format(t))
time.sleep(2)
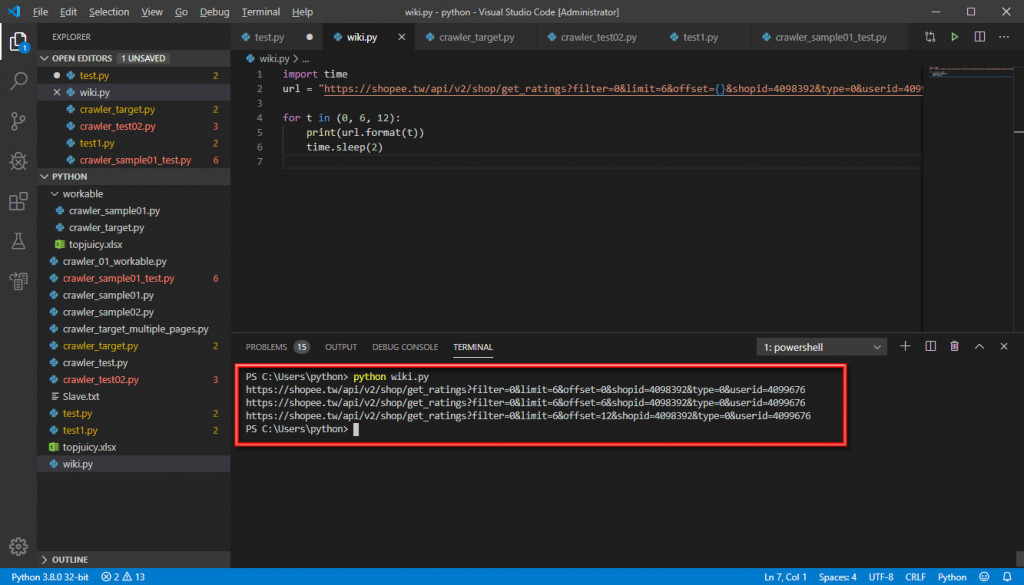
結果顯示可以的(也許有更好的方法),接下來是置入原本正常單一頁爬蟲的程式碼,正常運作的碼如下:
import requests
from selenium import webdriver
import json
import pandas
url = "https://shopee.tw/api/v2/shop/get_ratings?filter=0&limit=6&offset=0&shopid=4098392&type=0&userid=4099676"
path = "C:\chromedriver.exe"
driver = webdriver.Chrome(path)
driver.get(url)
Cookie = ';'.join(['{}={}'.format(item.get('name'), item.get('value')) for item in driver.get_cookies()])
header = {
'cookie': Cookie,
'if-none-match-': 'ad0cf65c2f362c78081c167ace34e140',
'if-none-match-': '55b03-eddbcc2c628e9f6639f434a78134bca1',
'referer': 'https://shopee.tw/buyer/4099676/rating',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
'x-api-source': 'pc',
'x-requested-with': 'XMLHttpRequest',
#'Postman-Token': '68c324d7-4894-448a-a4db-9072b6bbcf0c',
#'Connection': 'keep-alive'
}
req = requests.get(url, headers = header)
data = req.json()
df0 = ('買家ID: {}'.format(data['data']['items'][0]['cmtid']))
df1 = ('買家ID: {}'.format(data['data']['items'][1]['cmtid']))
df2 = ('買家ID: {}'.format(data['data']['items'][2]['cmtid']))
df3 = ('買家ID: {}'.format(data['data']['items'][3]['cmtid']))
df4 = ('買家ID: {}'.format(data['data']['items'][4]['cmtid']))
df5 = ('買家ID: {}'.format(data['data']['items'][5]['cmtid']))
ls = (df0, df1, df2, df3, df4, df5)
all = pandas.DataFrame(ls)
print(all)
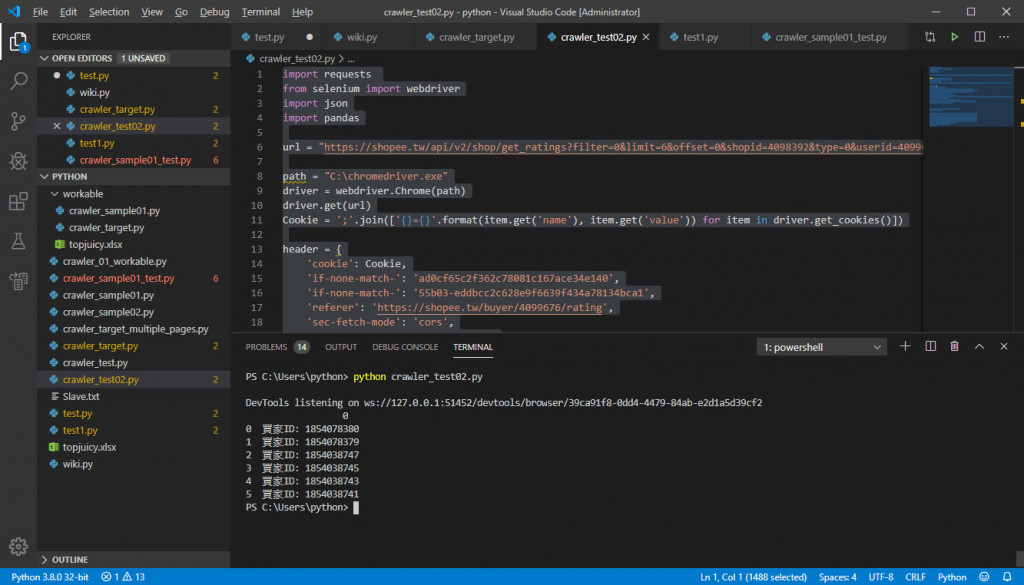
下面是我試著將 Loop 欲抓三頁的程式碼置入,發現有問題,如下:
import requests
from selenium import webdriver
import json
import pandas
import time
#url = "https://shopee.tw/api/v2/shop/get_ratings?filter=0&limit=6&offset=0&shopid=4098392&type=0&userid=4099676"
url = "https://shopee.tw/api/v2/shop/get_ratings?filter=0&limit=6&offset={}&shopid=4098392&type=0&userid=4099676"
for t in (0, 6, 12):
print(url.format(t))
path = "C:\chromedriver.exe"
driver = webdriver.Chrome(path)
driver.get(url)
Cookie = ';'.join(['{}={}'.format(item.get('name'), item.get('value')) for item in driver.get_cookies()])
header = {
'cookie': Cookie,
'if-none-match-': 'ad0cf65c2f362c78081c167ace34e140',
'if-none-match-': '55b03-eddbcc2c628e9f6639f434a78134bca1',
'referer': 'https://shopee.tw/buyer/4099676/rating',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
'x-api-source': 'pc',
'x-requested-with': 'XMLHttpRequest',
#'Postman-Token': '68c324d7-4894-448a-a4db-9072b6bbcf0c',
#'Connection': 'keep-alive'
}
req = requests.get(url, headers = header)
data = req.json()
df0 = ('買家ID: {}'.format(data['data']['items'][0]['cmtid']))
df1 = ('買家ID: {}'.format(data['data']['items'][1]['cmtid']))
df2 = ('買家ID: {}'.format(data['data']['items'][2]['cmtid']))
df3 = ('買家ID: {}'.format(data['data']['items'][3]['cmtid']))
df4 = ('買家ID: {}'.format(data['data']['items'][4]['cmtid']))
df5 = ('買家ID: {}'.format(data['data']['items'][5]['cmtid']))
ls = (df0, df1, df2, df3, df4, df5)
all = pandas.DataFrame(ls)
print(all)
time.sleep(2)
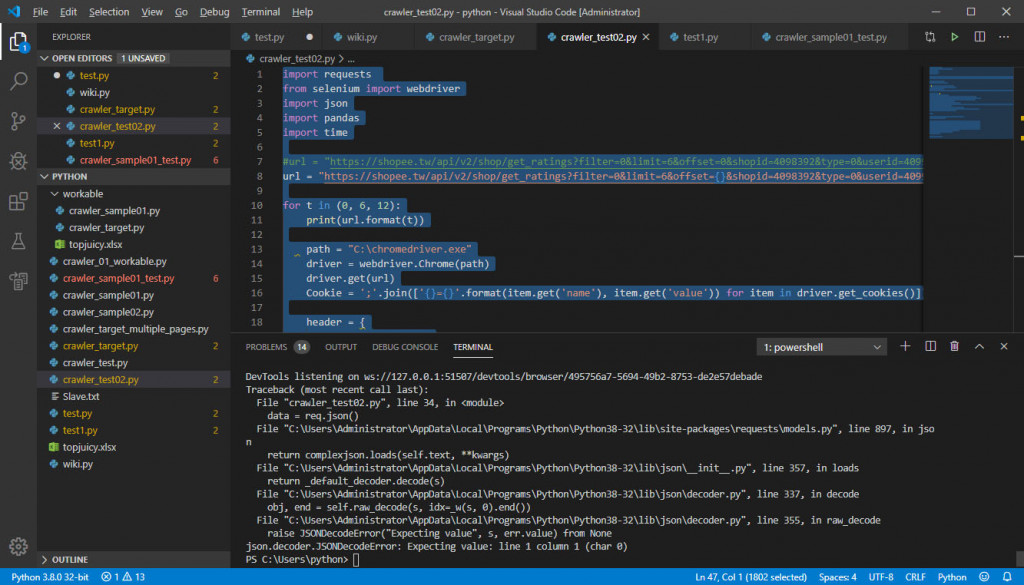
我有試將著code縮減測試,url 的替換在 req = requests.get(url, headers = header),之前是可以運作的,但是有幾種可能是我無法判斷(因為我還很蔡)
麻煩各位先進指導,謝謝
已邀請的邦友 {{ invite_list.length }}/5
我是懶得設置selenium,不過...
爬蟲就是和寫網頁的人鬥智,寫過網頁能理解怎麼運作的,你要寫爬蟲很快。
剛剛瞄了一下程式碼,string format先去搞懂吧。

