在抓取網頁資料遇到一個問題
如果是視窗模式的話可以抓到值
但只要開啟headless就會抓不到值
['1#镍', '107950—113550', '110750', '-2,600']
感覺是資料擷取長度不足問題
想請問有什麼方式解決嗎?
正常:
['1#镍', '107950—113550', '110750', '-2,600', '元/吨', '01-06']
網站 https://www.ccmn.cn/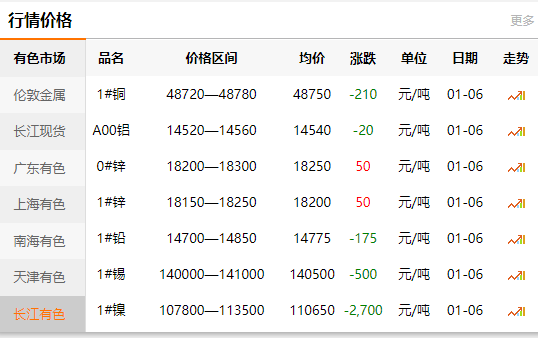
程式碼
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
def scrp_ccmn01(driver):
driver.get("https://www.ccmn.cn/")
#讀取內文報價資料
tr_elem = driver.find_element_by_xpath('//*[@id="quoPrice_box"]/table')
for tr in tr_elem.find_elements_by_xpath('//tr'):
ls = [td.text for td in tr.find_elements_by_xpath('td')
if len(td.text.strip()) > 0]
#print(ls)
if (len(ls) > 0) and ('1#镍' in ls[0]):
break
已邀請的邦友 {{ invite_list.length }}/5
使用headless的chrome時,是需要設定相關的視窗尺寸。
嘗試加上這行
chrome_options.add_argument('window-size=1024x768')
