不好意思,我又來了QQ,繼上次爬的utf-8,這次我爬的是big5
txt好像不能存big5,然後我試過乾脆存word,可是存完是空的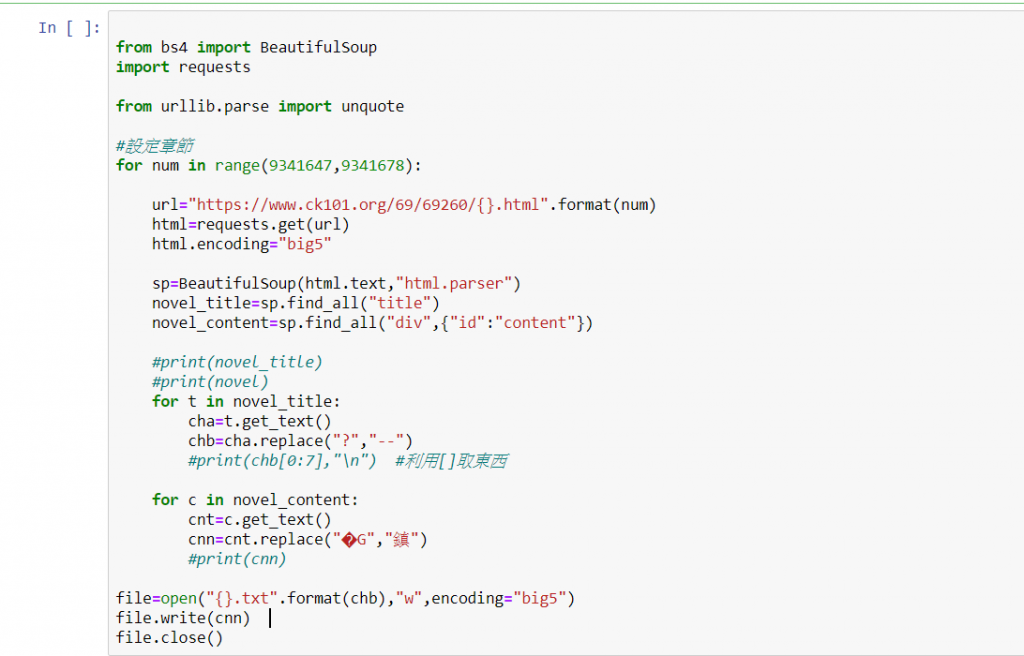
然後想把big5轉成utf-8好像也不行,具體之前寫成這樣:
file=open("{}.txt".format(chb),"w",encoding="utf-8")
請問怎麼處理?謝謝大大們!
已邀請的邦友 {{ invite_list.length }}/5
我用big5存的時候跑出這個,就以為是這個原因...
'big5' codec can't encode character '\xa0' in position 0: illegal multibyte sequence
編碼失敗應該不會是 big5 的關係
因為不是所有網址編碼都是 big5
big5hkscs
big5hkscs
big5hkscs
ISO-8859-1
big5hkscs
big5hkscs
ISO-8859-1
big5hkscs
big5hkscs
big5hkscs
ISO-8859-1
big5hkscs
ISO-8859-1
big5hkscs
big5hkscs
big5hkscs
ISO-8859-1
ISO-8859-1
ISO-8859-1
ISO-8859-1
big5hkscs
big5hkscs
big5hkscs
not catch num: 9341670
ISO-8859-1
big5hkscs
big5hkscs
ISO-8859-1
big5hkscs
big5hkscs
big5hkscs
lydia0231
你仔細讀完這篇,你就知道 listennn08 大大的意思了。
http://www.aobosir.com/blog/2016/11/26/python3-UnicodeEncodeError-gbk-codec-can't-encode-character-xa0/
网页源代码中的 的utf-8 编码是:\xc2 \xa0,通过后,转换为Unicode字符为:\xa0
@listennn08、ted59438 ,謝謝兩位大大,我好像有點理解編碼的轉換過程了

 iThome鐵人賽
iThome鐵人賽